

如何使用Python抓取网页内容
如果您知道如何提取数据,互联网就是一个巨大的数据来源。因此,近年来对网络抓取的需求呈指数级增长,而 Python 已成为为此目的最流行的编程语言。
在这个循序渐进的教程中,您将学习如何使用流行的库(例如 Requests 和 Beautiful Soup)检索信息。
让我们深入了解使用 Python 进行网络抓取的世界吧!
什么是 Python 中的网页抓取
Web 抓取是从 Web 检索数据的过程。甚至从页面复制和粘贴内容也是一种抓取形式!然而,该术语通常是指由自动化软件执行的任务,本质上是一个脚本(也称为机器人、爬虫或蜘蛛),它访问网站并从其页面中提取感兴趣的数据。在我们的例子中,使用 Python。
您需要知道,许多网站出于不同的原因实施了反抓取技术。但别担心,因为我们会告诉你如何绕过它们!
如果您负责任地练习抓取,就不太可能遇到法律问题。只需确保您没有违反服务条款或提取敏感信息,尤其是在构建大型项目之前。这是您必须了解的几种网络爬虫最佳实践之一。
Python Web 抓取路线图 101
想知道在使用 Python 学习网络抓取的过程中有什么进展吗?继续阅读,请放心,我们会在您的初始步骤中手把手教您。
你需要学习什么
抓取是一个循序渐进的过程,涉及四个主要任务。这些都是:
- 检查目标站点:大致了解您可以提取哪些信息。要执行此任务:
- 访问目标网站以熟悉其内容和结构。
- 研究 HTML 元素在页面上的定位方式。
- 找出最重要的数据在哪里以及它的格式。
- 获取页面的 HTML 代码:通过下载页面的文档来访问 HTML 内容。要做到这一点:
- 使用 HTTP 客户端库(如 Requests)连接到您的目标网站。
- 使用要抓取的页面的 URL 向服务器发出 HTTP GET 请求。
- 验证服务器是否成功返回了 HTML 文档。
- 从 HTML 文档中提取数据:获取您想要的信息,通常是特定的数据片段或项目列表。为了达成这个:
- 使用 Beautiful Soup 等数据解析库解析 HTML 内容。
- 选择具有相同库的感兴趣的 HTML 内容。
- 编写抓取逻辑以从这些元素中提取信息。
- 如果该网站包含许多页面并且您想全部抓取它们:
- 从当前页面提取链接并将其添加到队列中。
- 按照第一个链接返回,直到队列为空。
- 存储提取的数据:提取后,将其转换并以更易于使用的格式存储。要做到这一点:
- 将抓取的内容转换为 CSV、JSON 或类似格式,并将它们导出到文件中。
- 将其写入数据库。
备注:不要忘记在线数据不是静态的!网站不断变化和发展,其内容也是如此。因此,为了使抓取的信息保持最新,您需要定期查看并重复此过程。
抓取用例
Python 中的网页抓取在各种情况下都能派上用场。一些最相关的用例包括:
- 竞争对手分析:从竞争对手的网站收集有关他们的产品/服务、功能和营销方法的数据,以监控他们并获得竞争优势。
- 比价:收集多个电商平台的价格进行比较,找到最优惠的价格。
- 潜在客户生成:从网站提取联系信息,例如姓名、电子邮件地址和电话号码,为企业创建有针对性的营销列表。但当涉及个人信息时,请注意您的国家法律。
- 情绪分析:从社交媒体中检索新闻和帖子,以跟踪公众对某个主题或品牌的看法。
- 社交媒体分析:从 Twitter、Instagram、Facebook 和 Reddit 等社交平台恢复数据,以跟踪特定主题标签、关键字或影响者的流行度和参与度。
请记住,这些只是一些例子;在很多情况下,检索信息都会有所作为。查看我们的网络抓取用例指南以了解更多信息!
Web 抓取中的挑战
任何可以访问 Internet 的人都可以创建站点,这使得 Web 成为一个以不断变化的技术和风格为特征的混乱环境。因此,您在抓取时必须应对一些挑战:
- 多样性:在线可用的布局、样式、内容和数据结构的多样性使得不可能编写一个蜘蛛来抓取所有内容。每个网站都是独一无二的。因此,每个网络爬虫脚本都必须针对特定目标进行定制。
- 长寿:抓取涉及从网站的 HTML 元素中提取数据。因此,其逻辑取决于站点的结构。但是网页可以更改其结构和内容,恕不另行通知!这会使抓取器停止工作并迫使您相应地调整数据检索逻辑。
- 可伸缩性:随着要收集的数据量的增加,蜘蛛的性能成为一个问题。但是,有几种解决方案可以使您的 Python 抓取过程更具可扩展性:您可以使用分布式系统、采用并行抓取或优化代码性能。
然后,还有另一类挑战需要考虑:反机器人技术。这些是网站为防止恶意或不需要的机器人而采取的措施,默认情况下包括爬虫。
其中一些方法是 IP 阻止、JavaScript 挑战和 CAPTCHA,它们使数据提取变得不那么简单。然而,您可以使用例如旋转代理和无头浏览器来绕过它们。或者您可以只使用ZenRows来省去麻烦并轻松绕过它们。
Web 抓取的替代方案:API 和数据集
一些站点为您提供官方应用程序编程接口( API ) 来请求和检索数据。这种方法更稳定,因为这些机制不会经常更改,并且没有保护措施。同时,您可以通过它们访问的数据是有限的,只有一小部分互联网站点开发了 API。
另一种选择是在线购买现成的数据集,但您可能无法在市场上找到适合您特定需求的数据集。
这就是为什么在大多数情况下网络抓取仍然是成功的方法。
如何用 Python 抓取网站
准备好开始了吗?您将构建一个真正的爬虫,它从ScrapeMe检索数据,ScrapeMe 是一种用于学习网络抓取的 Pokémon 电子商务。

在这个循序渐进的教程结束时,您将拥有一个 Python 网络抓取工具:
- 使用 Requests 从 ScrapeMe 下载一些目标页面。
- 选择包含感兴趣数据的 HTML 元素。
- 用 Beautiful Soup 抓取所需的信息。
- 将信息导出到文件。
您将看到的只是一个示例,用于了解 Python 中的网络抓取是如何工作的。但是请记住,您可以将在这里学到的知识应用到任何其他网站。这个过程可能更复杂,但要遵循的关键概念总是相同的。
我们还将介绍如何解决常见错误并提供练习以帮助您打下坚实的基础。
在开始编写代码之前,您需要满足一些先决条件。立即解决所有问题!
设置环境
要使用 Python 构建数据抓取工具,您需要下载并安装以下工具:
- Python 3.11+:本教程指的是编写本文时最新的Python 3.11.2 。
- pip:Python 包索引 ( PyPi ),您可以使用它通过单个命令安装库。
- Python IDE:任何支持 Python 的 IDE 都可以。我们使用的是免费的PyCharm Community Edition 。
注意:如果您是 Windows 用户,请不要忘记勾选Add python.exe to PATH安装向导中的选项。这样,Windows 就可以在终端中使用python和命令。pip仅供参考:由于pip默认包含 Python 3.4 或更高版本,因此您无需手动安装。

您现在拥有了用 Python 构建您的第一个网络抓取工具所需的一切。我们走吧!
初始化 Python 项目
启动 PyCharm 并选择File > New Project...菜单栏上的选项。

它会打开一个弹出窗口。从左侧菜单中选择Pure Python,并按如下方式设置您的项目:
为您的项目创建一个名为python-scraper.Check the Create a main.py welcome scriptoption 的文件夹,然后单击Create按钮。
在等待 PyCharm 设置项目后,您应该会看到以下内容: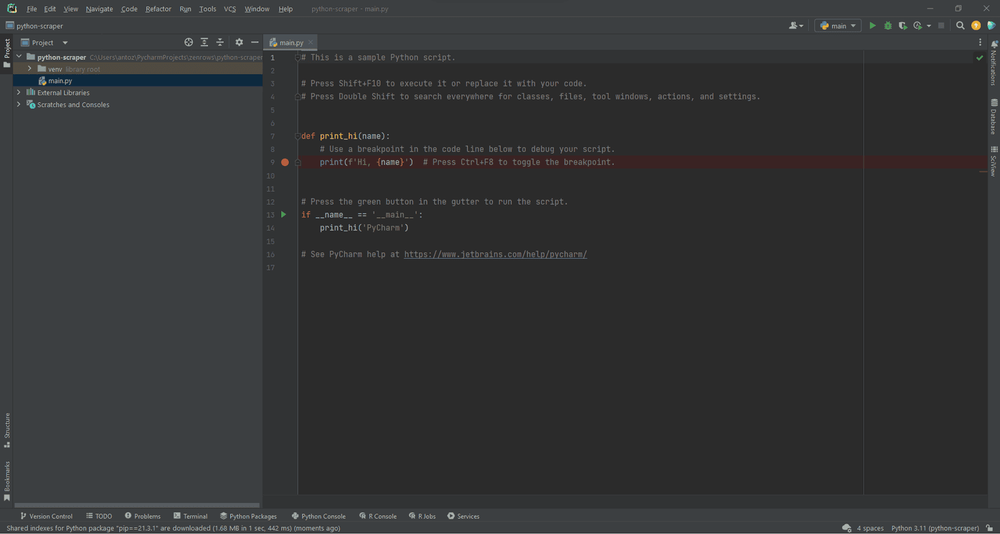
要验证一切正常,请打开屏
Hi, PyCharm
幕底部的“终端”选项卡并键入:
python main.py
启动这个命令,你应该得到:
Hi, PyCharm
重命名main.py并scraper.py从中删除所有代码行。您很快就会了解如何使用 Python 中的 Beautiful Soup 抓取逻辑填充该文件!
第 1 步:检查您的目标网站
您可能很想直接开始编码,但这不是最好的方法。首先,您需要花一些时间了解您的目标网站。这听起来可能很乏味或没有必要,但这是研究站点结构并了解如何从中抓取数据的唯一方法。每个抓取项目都是这样开始的。
冲杯咖啡,然后在您最喜欢的浏览器中打开ScrapeMe。
浏览网站
像任何普通用户一样与网站互动。探索不同的产品列表页面,尝试搜索功能,进入单个产品页面,并将项目添加到您的购物车。研究网站的反应及其页面的结构。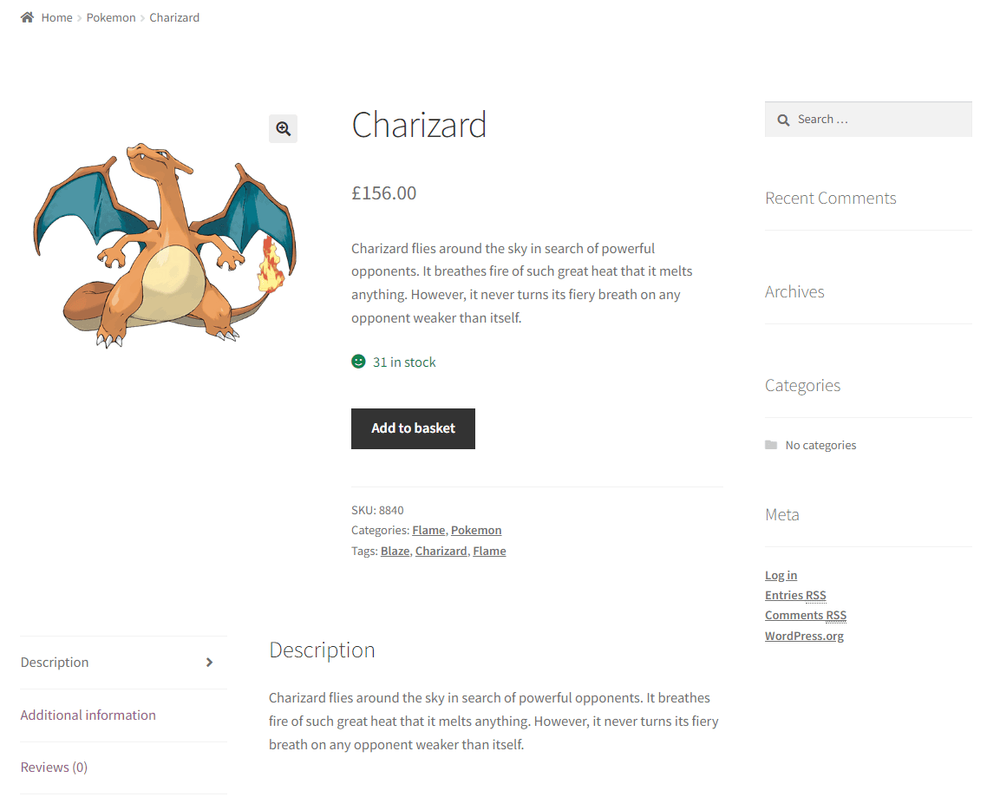
尝试使用网站的按钮、图标和其他元素,看看会发生什么。具体而言,请查看当您更改页面时 URL 如何更新。
分析 URL 结构
Web 服务器根据请求 URL 返回一个 HTML 文档,每个文档都与特定页面相关联。考虑 Venosaur 产品页面 URL:
https://scrapeme.live/shop/Venusaur/
您可以将它们中的任何一个解构为两个主要部分:
- 基本 URL:网站商店部分的路径。在这里
https://scrapeme.live/shop/。 - 特定页面位置:特定产品的路径。URL 可能以
.html,结尾.php,或者根本没有扩展名。
网站上提供的所有产品都将具有相同的基本 URL。每个页面之间的变化是它的后半部分,包含一个字符串,该字符串指定服务器应该返回哪个产品页面。通常,相同类型页面的 URL 总体上共享相似的格式。
此外,URL 可以包含额外信息:
- 路径参数:这些用于在RESTful方法中捕获特定值(例如,in
https://www.example.com/users/14是14路径参数)。 - 查询参数:这些被添加到 URL 末尾的问号 (
?) 之后。它们通常对过滤器值进行编码,以便在执行搜索时发送到服务器(例如,inhttps://www.example.com/search?search=blabla&sort=newest和search=blabla是sort=newest查询参数)。
请注意,任何查询参数字符串都包含:
?: 它标志着开始。- 用:
key=value分隔的参数列表是一个参数的名称,同时显示它的值。查询字符串包含由字符分隔的键值对中的参数。&keyvalue&
换句话说,URL 不仅仅是 HTML 文档的简单位置字符串。它们可以包含参数中的信息,服务器使用这些信息来运行查询并用特定数据填充页面。
看看下面的一个,了解这一切是如何工作的:
https://scrapeme.live/page/3/?s=bla

在该示例中,3是路径参数,而是查询参数bla的值s。此 URL 将指示服务器运行分页搜索查询并获取所有包含该字符串的内容bla,并仅返回第 3 页的结果。
📘练习:尝试使用上面的 URL。更改路径参数和查询字符串以查看会发生什么。同样,使用搜索输入来查看 URL 的反应。
📘解决方案:如果更新搜索框中的字符串并提交,sURL 中的查询参数将相应更改。反之亦然,手动更改该 URL 会导致网站上显示不同的结果。
检查您的目标网站以确定其页面结构以及如何从服务器检索数据。
现在您知道了 ScrapeMe 的页面结构是如何工作的,是时候检查其页面的 HTML 代码了。
使用开发人员工具检查站点
您现在已经熟悉该网站了。下一步是深入研究页面的 HTML 代码以研究其结构和内容,从而了解如何从中提取数据。
右键单击 HTML 元素并选择Inspect打开 DevTools 窗口。如果站点禁用了右键单击菜单,则执行以下操作:
在 macOS 上:选择View > Developer > Developer菜单栏中的工具。
在 Windows 和 Linux 上:单击右上角的⋮菜单按钮,然后选择More Tools > Developer tools选项。
它们让您检查网页的文档对象模型 ( DOM )的结构。这反过来又可以帮助您更深入地了解源代码。在 DevTools 部分,输入Elements选项卡以访问 DOM。

如您所见,这将结构显示为可点击的 HTML 节点树。右侧选择的节点代表左侧突出显示的元素的代码。考虑到您可以直接在 DevTools 中展开、压缩甚至编辑这些节点。
要定位 HTML 元素在 DOM 中的位置,请右键单击它并选择Inspect。将鼠标悬停在右侧的 HTML 代码上,您会看到相应的元素在页面上亮起。
如果您难以理解 DOM 和 HTML 之间的区别:
- HTML 代码表示开发人员编写的网页文档的内容。
- DOM 是浏览器创建的 HTML 代码的动态内存表示。在 JavaScript 中,您可以操纵页面的 DOM 来更改其内容、结构和样式。
📘练习:包含 Bulbasaur 的产品元素的第一类是什么li?产品价格包含在哪个 HTML 标签中?使用 DevTools 探索 DOM 以找出答案!
📘解决方案:第一类是post-759,而包装价格的 HTML 标签是<span>.
实验和玩耍!您对目标页面的挖掘越好,抓取它们就越容易。
系好安全带!您将要构建一个 Python 蜘蛛,它可以导航 HTML 代码并从中提取相关数据。
第 2 步:下载 HTML 页面
准备好启动您的 Python 引擎!你已经准备好编写一些代码了!
假设您要从以下位置抓取数据:
https://scrapeme.live/shop/
您首先需要检索目标页面的 HTML 代码。换句话说,您必须下载与页面 URL 关联的 HTML 文档。为此,请使用 Pythonrequests库。
在 PyCharm 项目的终端选项卡中,启动以下命令进行安装requests:
pip install requests
打开scraper.py文件并使用以下代码行对其进行初始化:
import requests
// download the HTML document
// with an HTTP GET request
response = requests.get("https://scrapeme.live/shop/")
// print the HTML code
print(response.text)
此代码段导入requests dependencies. 然后,它使用该函数对目标页面 URLrequests get()执行HTTPGET请求get(),并返回包含 HTML 文档的响应的 Python 表示形式。
打印text响应的属性,您将可以访问您之前检查过的页面的代码:
<!doctype html> <html lang="en-GB"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=2.0"> <link rel="profile" href="http://gmpg.org/xfn/11"> <link rel="pingback" href="https://scrapeme.live/xmlrpc.php"> <title>Products – ScrapeMe</title> <!-- rest of the page omitted for brevity... -->
常见错误:忘记错误处理逻辑!
GET对服务器的请求可能由于多种原因而失败。可能是服务器暂时不可用,可能是网址错误,也可能是您的IP被封了。这就是为什么您可能希望按如下方式处理错误:
response = requests.get("https://scrapeme.live/sh1op/")
# if the response is 2xx
if response.ok:
# scraping logic here...
else:
# log the error response
# in case of 4xx or 5xx
print(response)
这样,脚本不会在请求出错的情况下崩溃,并且只会在2xx响应时继续。
极好的!您刚刚学习了如何从 Python 抓取脚本中获取站点页面的 HTML 代码!
在编写一些数据抓取 Python 逻辑之前,让我们先了解一下您可能会遇到的网站类型。
静态内容网站
静态内容网页不执行AJAX请求来动态获取其他数据。ScrapeMe 是一个静态内容网站。这意味着服务器发回已经包含所有内容的 HTML 页面。
要检查这一点,请查看FETCH/XHRDevTools 的网络选项卡中的部分。重新加载页面,该部分应保持为空,如下图所示:

这意味着目标页面不会在呈现时进行 AJAX 调用来检索数据。因此,您从服务器获得的就是您在页面上看到的。
使用静态内容站点,您不需要复杂的逻辑来访问其内容。您所要做的就是使用页面的 URL 向他们的服务器发出 HTTP Web 请求。一块蛋糕!
Python库requests足以检索 HTML 内容。然后,您可以解析 HTML 响应并立即开始收集相关数据。静态内容网站最容易抓取。
然而,还有更具挑战性的类型需要分析!
动态内容网站
在这里,服务器只返回用户将在页面上看到的一小部分 HTML 内容。浏览器通过 JavaScript 代码生成剩余信息。这使得 API 请求获取数据并动态生成其余的 HTML 内容。
当涉及到某些技术时,服务器几乎不发送任何 HTML。相反,您得到的是大量 JavaScript 代码。这指示浏览器根据它通过 API 动态检索的数据在呈现时创建所需的 HTML。
您在服务器响应中获得的代码与您使用开发人员工具检查页面时看到的完全不同。这在使用 React、Vue 或 Angular 开发的应用程序中很常见。这些技术使用客户端的浏览器功能来卸载服务器的工作。
页面始终保持不变,而不是向服务器发出新请求。当用户浏览 Web 应用程序时,JavaScript 会负责获取新信息并更新 DOM。这就是它们被称为单页应用程序 ( SPA ) 的原因。
请记住,只有浏览器可以运行 JavaScript。出于这个原因,抓取具有动态内容的站点需要具有浏览器功能的工具。使用requests,您只会得到服务器发送的内容,这将是您无法运行的大量 JS 代码。
要使用 Python 从动态内容站点中提取数据,您可以使用requests-html. 这是作者创建的一个项目,requests添加了运行 JavaScript 的能力。另一个选择是Selenium,最流行的无头浏览器库。
对于那些不熟悉这个概念的人来说,无头浏览器是没有图形用户界面 ( GUI ) 的浏览器。使用像 Selenium 这样的库,您可以指示它运行任务。它们是在 Python 中运行 JavaScript 代码的理想解决方案!
深入研究抓取动态内容网站的工作原理并不是本教程的目标。如果您想了解更多信息,请查看我们的Python 无头浏览器指南!
登录墙站点
一些网站限制登录墙后面的信息。只有授权用户才能克服它并访问特定页面。
著名的LinkedIn授权墙
要从中抓取数据,您需要一个帐户。在浏览器中登录是一回事,但在 Python 中以编程方式进行登录又是另一回事。
由于 ScrapeMe 不受登录保护,因此本教程将不涉及身份验证。但我们有适合您的解决方案!按照我们的指南了解如何抓取需要使用 Python 登录的网站以了解更多信息!
第 3 步:使用 Beautiful Soup 解析 HTML 内容
在上一步中,您从服务器检索了一个 HTML 文档。如果你看一下它,你会看到一长串代码,理解它的唯一方法是通过HTML 解析提取所需的数据。
是时候学习如何使用 Beautiful Soup 了!
Beautiful Soup是一个用于解析 XML 和 HTML 内容的 Python 库,它公开了一个 API 来探索 HTML 代码。换句话说,它允许您选择 HTML 元素并轻松地从中提取数据。
要安装库,请在终端中启动以下命令:
pip install beautifulsoup4
然后,用它来解析通过这种方式检索到的内容requests:
import requests
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
# download the target page
response = requests.get("https://scrapeme.live/shop/")
# parse the HTML content of the page
soup = BeautifulSoup(response.content, "html.parser")
构造函数BeautifulSoup()获取一些内容和一个指定要使用的解析器的字符串。"html.parser"指示 Beautiful Soup 使用 HTML 格式。
常见错误:传递response.text而不是传递response.content给BeautifulSoup()。
content对象的属性以response原始字节保存 HTML 数据,这比存储在属性中的文本表示更容易解码text。为避免字符编码问题,最好response.content使用.response.textBeautifulSoup()
需要注意的是,网站包含多种格式的数据。单个元素、列表和表格只是几个示例。如果你想让你的 Python 爬虫有效,你需要知道如何在许多场景中使用 Beautiful Soup。让我们看看如何解决最常见的挑战!
从单个元素中提取数据
Beautiful Soup 提供了多种从 DOM 中选择 HTML 元素的方法,字段id是选择单个元素的最有效方法。顾名思义,id唯一标识页面上的 HTML 节点。
识别用于在 ScrapeMe 上搜索产品的输入元素。右键单击并使用 DevTools 检查它:

如您所见,该<input>元素具有以下 ID:
woocommerce-product-search-field-0
您可以使用此信息来选择产品搜索元素:
product_search_element = soup.find(id="woocommerce-product-search-field-0")
该find()函数使您能够从 DOM 中提取单个 HTML 元素。
请记住,这id是一个可选属性。这就是为什么还有其他选择元素的方法:
- 通过标签:使用
find()不带参数的函数:# get the first <h1> element # on the page h1_element = soup.find("h1")
按类别:通过class_中的参数find()
# find the first element on the page # with "search_field" class search_input_element = soup.find(class_="search_field")
- 您还可以通过CSS 选择器使用
select()和select_one()检索 HTML 节点:# find the first element identified # by the "input.search-field" CSS selector search_input_element = soup.select_one("input.search-field")此代码段将打印:
ScrapeMe
常见错误:不检查
None.当
find()或select_one()没有设法找到所需的元素时,他们返回None。由于页面随时间变化,您应该始终执行非检查,None如下所示:product_search_element = soup.find(id="woocommerce-product-search-field-0") # making sure product_search_element is present on the page # before trying to access its data if product_search_element is not None: placeholder_string = product_search_element["placeholder"]这个简单的
if检查可以避免像这样的愚蠢错误:TypeError: 'NoneType' object is not subscriptable
选择嵌套元素
DOM 是一个嵌套的树结构。定义一个选择策略以在一个步骤中获得所需的 HTML 元素并不总是那么容易,但这就是 Beautiful Soup 提供另一种搜索节点的方法的原因。
首先,选择包含许多嵌套节点的父节点。接下来,直接在这个上调用 Beautiful Soup 搜索功能。这会将研究范围仅限于父元素的子元素。
让我们用一个例子来深入研究这个问题!
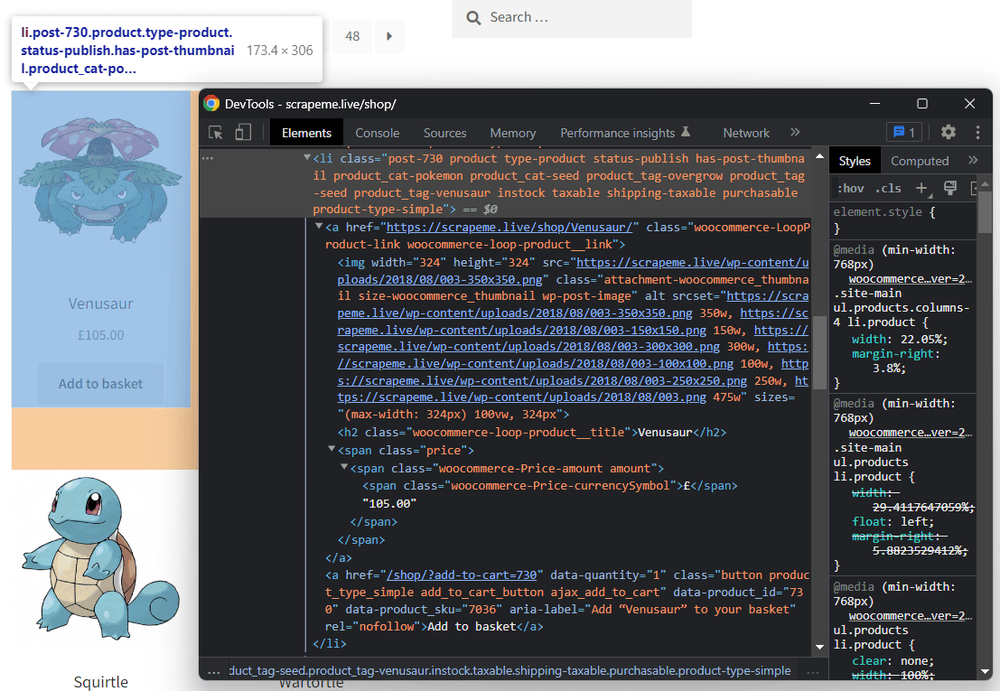
假设您要从 Venosaur 产品中检索一些数据。通过检查它,您会发现它的 HTML 元素没有 ID。这意味着您不能直接访问它们,您需要一个复杂的 CSS 选择器。

首先选择父元素:
venosaur_element = soup.find(class_="post-730")
然后,将
find()函数应用于venosaur_element:# extracting data from the nested nodes # extracting data from the nested nodes # inside the Venosaur product element venosaur_image_url = venosaur_element.find("img")["src"] venosaur_price = venosaur_element.select_one(".amount").get_text() print(venosaur_image_url) print(venosaur_price)这将打印:
https://scrapeme.live/wp-content/uploads/2018/08/003-350x350.png £105.00
您现在可以毫不费力地从嵌套元素中抓取数据!
📘练习:获取与Wartortle产品相关的页面URL和完整名称。
📘解决方案:与您之前所做的没有太大区别。
wartortle_element = soup.find(class_="post-735") wartortle_element = soup.find(class_="post-735") wartortle_url = wartortle_element.find("a")["href"] wartortle_name = wartortle_element.find("h2").get_text()寻找隐藏元素
具有display:none或visibility:hiddenCSS 类的 HTML 元素不可见。由于浏览器不会在页面上显示它们,因此它们也被称为隐藏元素。
通常,这些包含仅在特定交互后显示的数据。此外,它们还允许 Web 开发人员存储最终用户不应看到的信息。此信息通常用于为页面提供附加功能或用于调试。
它们仍然是 DOM 的一部分。因此,您可以像从所有其他 HTML 元素中一样从它们中选择和抓取数据。让我们看一个例子:
浏览特定产品的页面,例如 Charizard:
response = requests.get("https://scrapeme.live/shop/Charizard/")
soup = BeautifulSoup(response.content, "html.parser")
查看“描述”部分,您会看到左侧有一些可点击的选项。单击它们会激活页面上以前不可见的元素:

使用本节中的开发人员工具检查 HTML 页面。您会注意到“附加信息”和“评论”父级<div>具有display: noneCSS 类。

当您单击左侧菜单中的相应语音时,浏览器会通过 JavaScript 删除该类。这将使它可见。但是您不必等待元素出现才能从中抓取数据!
选择“附加信息”内容<div>:
additional_info_div = soup.select_one(".woocommerce-Tabs-panel--additional_information")
现在,打印一个节点来验证 Beautiful Soup 是否找到了它。作为补充,在生成的节点上运行prettify()以获取易于阅读格式的 HTML 内容。
print(additional_info_div.prettify())
这将返回:
<div aria-labelledby="tab-title-additional_information" class="woocommerce-Tabs-panel woocommerce-Tabs-panel--additional_information panel entry-content wc-tab" id="tab-additional_information" role="tabpanel">
<h2>
Additional information
</h2>
<table class="shop_attributes">
<tr>
<th>
Weight
</th>
<td class="product_weight">
199.5 kg
</td>
</tr>
<tr>
<th>
Dimensions
</th>
<td class="product_dimensions">
5 x 5 x 5 cm
</td>
</tr>
</table>
</div>
这正是“附加信息”中包含的 HTML 代码<div>。由于结果不是None,Beautiful Soup 能够找到它,即使它是一个隐藏元素。
从表中获取数据
让我们继续这个例子来学习如何从<table>HTML 元素中抓取数据。

<tr>HTML 表格是一组结构化数据,由多行和许多单元格组成<td>。检索所有信息:
# get the table contained inside the
# "Additional Information" div
additional_info_table = additional_info_div.find("table")
# iterate over each row of the table
for row in additional_info_table.find_all("tr"):
category_name = row.find("th").get_text()
cell_value = row.find("td").get_text()
print(category_name, cell_value)
注意使用find_all()。这是一个 Beautiful Soup 函数,用于获取与选择查询匹配的所有 HTML 元素的列表。
运行它,你会看到:
Weight 199.5 kg Dimensions 5 x 5 x 5 cm
这就是表格中包含的所有内容!
这是一个简单的示例,但您可以简单地将上面的抓取逻辑扩展到更大更复杂的场景。
📘练习:从其维基百科页面中提取所有海绵宝宝第一季剧集信息:
https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes
📘解决方案:有几种方法可以解决这个问题。这是许多可能的解决方案之一:
response = requests.get("https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes")
soup = BeautifulSoup(response.content, "html.parser")
episode_table = soup.select_one(".wikitable.plainrowheaders.wikiepisodetable")
# skip the header row
for row in episode_table.find_all("tr")[1:]:
# to store cell values
cell_values = []
# get all row cells
cells = row.find_all("td")
# iterating over the list of cells in
# the current row
for cell in cells:
# extract the cell content
cell_values.append(cell.get_text())
print("; ".join(cell_values))
抓取元素列表
网页通常包含元素列表,例如电子商务中的产品列表。从它们中检索数据可能会花费很多时间,但是 Python 的 Beautiful Soup 抓取功能在这里发挥了作用!
回到https://scrapeme.live/:
response = requests.get("https://scrapeme.live/shop/")
soup = BeautifulSoup(response.content, "html.parser")
其中包含元素中受口袋妖怪启发的产品列表<li>:

请注意,所有<li>节点都有产品类别。全部选择:
product_elements = soup.select("li.product")
迭代它们以提取所有产品数据,如下所示:
for product_element in product_elements:
name = product_element.find("h2").get_text()
url = product_element.find("a")["href"]
image = product_element.find("img")["src"]
price = product_element.select_one(".amount").get_text()
print(name, url, image, price)
在处理元素列表时,应该将抓取的数据存储在字典列表中。Python 字典是键值对的无序集合,您可以按如下方式使用它:
# the list of dictionaries containing the
# scrape data
pokemon_products = []
for product_element in product_elements:
name = product_element.find("h2").get_text()
url = product_element.find("a")["href"]
image = product_element.find("img")["src"]
price = product_element.select_one(".amount").get_text()
# define a dictionary with the scraped data
new_pokemon_product = {
"name": name,
"url": url,
"image": image,
"price": price
}
# add the new product dictionary to the list
pokemon_products.append(new_pokemon_product)
pokemon_products现在包含从页面上的每个单独产品中抓取的所有信息的列表。
哇!您现在拥有使用 Beautiful Soup 在 Python 中构建数据抓取器所需的所有构建块。但是继续前进;教程还没有结束!
第四步:导出抓取的数据
检索 Web 内容通常是更大过程中的第一步。然后将抓取的信息用于满足不同的需求和不同的目的。这就是为什么将其转换为易于阅读和探索的格式(例如 CSV 或 JSON)至关重要的原因。
pokemon_products您在前面显示的列表中有产品信息。现在,了解如何将其转换为新格式并将其导出到 Python 文件中!
导出为 CSV
CSV 是一种流行的数据交换、存储和分析格式,尤其是在涉及大型数据集时。CSV 文件以表格形式存储信息,值以逗号分隔。这使其与 Microsoft Excel 等电子表格程序兼容。
在 Python 中将字典列表转换为 CSV:
import csv
# scraping logic...
# create the "products.csv" file
csv_file = open('products.csv', 'w', encoding='utf-8', newline='')
# initialize a writer object for CSV data
writer = csv.writer(csv_file)
# convert each element of pokemon_products
# to CSV and add it to the output file
for pokemon_product in pokemon_products:
writer.writerow(pokemon_product.values())
# release the file resources
csv_file.close()
此代码段将抓取的数据导出到pokemon_product文件中products.csv。它创建一个带有open(). 然后,它遍历每个产品并将其添加到带有writerow(). 这会将产品字典作为 CSV 格式的行写入 CSV 文件。
常见错误:寻找外部依赖项来处理 Python 中的 CSV 文件。
csv提供类和方法以方便地处理此类文档,它是Python 标准库的一部分。因此,您可以导入并使用它而无需安装任何额外的依赖项。
启动 Python 蜘蛛:
python scraper.py
在项目的根文件夹中,您会看到一个products.csv包含以下内容的文件:
Bulbasaur,https://scrapeme.live/shop/Bulbasaur/,https://scrapeme.live/wp-content/uploads/2018/08/001-350x350.png,£63.00 Bulbasaur,https://scrapeme.live/shop/Bulbasaur/,https://scrapeme.live/wp-content/uploads/2018/08/001-350x350.png,£63.00 Ivysaur,https://scrapeme.live/shop/Ivysaur/,https://scrapeme.live/wp-content/uploads/2018/08/002-350x350.png,£87.00 ... Beedrill,https://scrapeme.live/shop/Beedrill/,https://scrapeme.live/wp-content/uploads/2018/08/015-350x350.png,£168.00 Pidgey,https://scrapeme.live/shop/Pidgey/,https://scrapeme.live/wp-content/uploads/2018/08/016-350x350.png,£159.00
导出为 JSON
JSON 是一种轻量级、通用、流行的数据交换格式,尤其是在 Web 应用程序中。它通常用于通过 API 在服务器之间或客户端与服务器之间传输信息。许多编程语言都支持它,您还可以将其导入 Excel。
使用以下代码将字典列表导出到 Python 中的 JSON:
import json
# scraping logic...
# create the "products.json" file
json_file = open('data.json', 'w')
# convert pokemon_products to JSON
# and write it into the JSON output file
json.dump(pokemon_products, json_file)
# release the file resources
json_file.close()
上面的导出逻辑围绕json.dump()函数展开。它来自json标准 Python 模块,允许您将 Python 对象写入 JSON 格式的文件。
json.dump()接受两个参数:
- 要转换为 JSON 格式的 Python 对象。
open()使用写入 JSON 数据的位置初始化的文件对象。
启动抓取脚本:
python scraper.py
products.json项目文件夹中将出现一个文件。打开它,你会看到这个:
[
{
"name": "Bulbasaur",
"url": "https://scrapeme.live/shop/Bulbasaur/",
"image": "https://scrapeme.live/wp-content/uploads/2018/08/001-350x350.png",
"price": "£63.00"
},
{
"name": "Ivysaur",
"url": "https://scrapeme.live/shop/Ivysaur/",
"image": "https://scrapeme.live/wp-content/uploads/2018/08/002-350x350.png",
"price": "£87.00"
},
...
{
"name": "Beedrill",
"url": "https://scrapeme.live/shop/Beedrill/",
"image": "https://scrapeme.live/wp-content/uploads/2018/08/015-350x350.png",
"price": "£168.00"
},
{
"name": "Pidgey",
"url": "https://scrapeme.live/shop/Pidgey/",
"image": "https://scrapeme.live/wp-content/uploads/2018/08/016-350x350.png",
"price": "£159.00"
}
]
下一步
Web 抓取 Python 教程到此结束,但这并不意味着您的学习也是如此!查看以下有用资源的集合,以了解更多信息、提高技能并挑战自我。
更多练习以提高您的技能
以下是一系列练习,可帮助您提高 Python 中的数据抓取技能:
- 爬取整个网站:展开此处构建的蜘蛛以爬取整个网站并检索所有产品数据。它应该从产品分页列表的第一页开始。按照我们的Python 网络爬虫指南进行操作。
- 实施并行抓取:更新以前的脚本以同时从多个页面抓取数据。使用
concurrent.futures模块或任何其他并行处理库。查看我们的Python 并行抓取教程。 - 将抓取的内容写入数据库:展开 Python 脚本以将存储的信息写入
pokemon_products数据库。使用您选择的任何数据库管理系统,例如 MySQL 和 PostgreSQL。确保以结构化的方式保存信息以支持将来的检索。
最佳课程
在线课程是学习新事物的一种非常有效的方式。此外,您还将获得结业证书以丰富您的简历。这些是目前可用的最受推荐的 Python 网络抓取课程之一:
- Python 中的网页抓取和 API 基础知识:这涵盖了 Python 中网页抓取和 API 的基础知识。它将教您如何使用流行的 Requests 库从网站和 API 中提取内容,以及如何解析 HTML 和 JSON 数据。
- Python 中的网页抓取:掌握基础知识:本课程介绍了 Python 中网页抓取的基础知识。它解释了如何使用 Beautiful Soup 和 Requests 库提取数据以及如何解析 HTML 和 XML 数据。
其他有用的资源
以下是您应该阅读的后续教程列表,以成为 Python 网络抓取专家:
- 2025年5个最佳Python Web抓取库:概述最流行的用于网络抓取的 Python 库,包括 BeautifulSoup、Scrapy 和 Selenium。
- 如何用Python抓取JavaScript渲染的网页:关于如何从使用 JavaScript 加载内容的网页中提取数据的指南,包括可用的不同方法和工具的比较。
- Python中的秘密网络抓取:像忍者一样避免阻塞:有关如何避免在抓取时被检测或阻止的指南,包括有关旋转 IP 地址、使用 HTTP 标头和 cookie 以及克服验证码的技巧。
- 如何在 Python 中轮换代理:有关如何使用多个代理 IP 地址以避免被检测或阻止的深入分步指南。
- 如何在 Python 中绕过 Cloudflare:有关如何使用 Python 和各种抓取技术访问受 Cloudflare 保护的网页的指南,Cloudflare 是一种流行的安全和性能优化服务。
结论
这个循序渐进的教程涵盖了开始使用 Python 进行网络抓取所需了解的所有内容。
首先,我们向您介绍了术语。然后,我们一起解决了最流行的 Python 数据抓取概念。
你现在知道了:
- 什么是网络抓取以及何时有用。
- 使用 Beautiful Soup 和 Requests 在 Python 中进行抓取的基础知识。
- 如何使用 Beautiful Soup 从单个节点、列表、表格等中提取数据。
- 如何将抓取的内容导出为多种格式,例如 JSON 和 CSV。
- 如何解决使用 Python 进行数据抓取时最常见的挑战。
常见问题
Python 最适合网络抓取吗?
Python 被认为是网络抓取的最佳编程语言之一。这是因为它的简单性、可读性、范围广泛的库和为此目的而设计的工具,以及庞大的社区。它不是唯一的选择,但它的特性使其可能成为开发人员的最佳选择。
此外,它作为一种编程语言的多功能性,可用于许多不同的目的,包括数据分析和机器学习,这也使它成为那些希望在抓取之外扩展技能的人的绝佳选择。
可以使用 Python 进行数据抓取吗?
是的你可以!在检索数据方面,Python DTijCmU5aS98c6gihFDmkSUmKgTCXBGHrXrHXJv61aXf HTTP 请求、解析 HTML 和提取信息。这使得 Python 成为数据抓取项目的完美解决方案。
你如何使用 Python 进行网页抓取?
您可以像使用任何其他编程语言一样,使用 Python 从网站上抓取数据。如果您利用 Python 中可用的众多 Web 抓取库之一,这会变得更容易。使用它们连接到目标网站,从其页面中选择 HTML 元素,并从中提取数据。






