

Python 和 Selenium 中的无头浏览器
Python 无头浏览器是一种工具,可用于在不需要真正的浏览器的情况下顺利地抓取动态内容,从而降低抓取成本并扩展抓取过程。
使用基于浏览器的解决方案进行网络抓取可帮助您处理需要 JavaScript 的站点。另一方面,网络抓取可能是一个漫长的过程,尤其是在处理复杂的网站或大量数据时。
在本指南中,我们将深入探讨 Python 无头浏览器:类型、优点和缺点。
什么是 Python 中的无头浏览器?
无头浏览器是没有图形用户界面 (GUI) 但具有真实浏览器功能的 Web 浏览器。它具有所有标准功能,如处理 JavaScript、单击链接等。Python 是一种可以让您享受其全部功能的编程语言。
使用 Python 无头浏览器,您可以自动化浏览器并学习语言。它可以节省您在开发和抓取阶段的时间。这是可能的,因为 Python 无头浏览器的好处之一是它使用更少的内存。
Python 无头浏览器的好处
Python 无头浏览器或任何无头浏览器进程使用的内存比真正的浏览器少。计算机达到这个条件是因为它不需要为浏览器和网站绘制图形元素。
Python 无头浏览器速度很快,可以加快抓取过程。例如,如果你想从网站上抓取数据,你可以对你的抓取程序进行编程,一旦数据存在于无头浏览器上就抓取数据,这样你就不必等待页面完全加载。
它还可以执行多任务,因为您可以在无头浏览器在后台运行时继续使用计算机。
Python无头浏览器的缺点
Python 无头浏览器的一些缺点是无法执行需要视觉交互的操作并且难以调试。
Python selenium无头
最流行的 Python 无头浏览器是Python Selenium,它的主要用途是自动化 Web 应用程序,包括 Web 抓取。Python Selenium 具有与浏览器和 Selenium 相同的功能。因此,如果浏览器可以无头操作,那么 Python Selenium 也可以。
Selenium 中包含什么无头浏览器?
Chrome、Edge 和 Firefox 是 Selenium Python 中的三个无头浏览器。这三个浏览器可以用来执行 Python Selenium headless。
1. 无头 Chrome Selenium Python
从版本 59开始,Chrome 附带了 headless 功能。您可以从命令行调用 Chrome 二进制文件来执行无头 Chrome。
chrome --headless --disable-gpu --remote-debugging-port=9222 https://zenrows.com
2.edge
该浏览器最初是使用 Microsoft 的专有浏览器引擎 EdgeHTML 构建的。然而,在 2018 年底,它被重建为具有 Blink 和 V8 引擎的 Chromium 浏览器,使其成为最好的无头浏览器之一。
3.火狐
与其他浏览器一样,Firefox 也被广泛使用,要打开无头 Firefox,请在命令行或终端中键入命令,如下所示。
firefox -headless https://zenrows.com
你如何在 Selenium Python 中无头?
您将学习如何通过无外设的 Python Selenium 无外设地执行浏览器自动化。例如,让我们尝试从ScrapeMe中抓取一些 Pokemon 的详细信息,例如名称、链接和价格。该页面如下所示:
先决条件
1.安装chrome
安装 Python 后,让我们继续使用以下命令代码在 Python 中安装 Selenium:
pip install selenium
这将在您的计算机上安装 Python Selenium。好消息是大多数时候 Python 会自动安装 Selenium,因此您不必担心。
2. 安装Webdriver Manager
Python Selenium 需要安装有相同浏览器版本的 Webdriver。您可以下载并设置ChromeDriver以使用已安装的 Chrome 浏览器。尽管存在一些缺点,例如忘记 Webdriver 二进制文件的特定路径或 Webdriver 与浏览器之间的版本不匹配。
为了避免这些问题,我们将使用Python 的Webdriver Manager 。该库可帮助您管理与您的环境相关的 Webdriver。它将下载正确的 Webdriver 并提供相关的二进制文件链接。所以你不需要在脚本中明确地写它。
您还可以使用 pip 安装 WebDrive 管理器。只需打开命令行或终端并键入以下命令。
pip install webdriver-manager
现在我们准备好使用 Python 无头浏览器抓取一些 Pokemon 数据。让我们开始吧!
第一步:打开页面
让我们编写一个打开页面的代码。需要此步骤来确认我们的环境已正确设置并准备好进行抓取。
运行下面的代码将自动打开 Chrome 并转到目标页面。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
url = "https://scrapeme.live/shop/"
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install())) as driver:
driver.get(url)
您成功打开页面,它看起来像这样:

第 2 步:切换到 Python Selenium 无头模式
打开页面后,其余过程将变得更加容易。当然,我们不希望浏览器出现在监视器上,我们希望 Chrome 无头运行。在 Python 中切换到无头 chrome 非常简单。
我们只需要添加两行代码,并在调用 Webdriver 时使用options 参数。
# ...
options = webdriver.ChromeOptions()
options.headless = True
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
# ...
完整的代码如下所示:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
url = "https://scrapeme.live/shop/"
options = webdriver.ChromeOptions() #newly added
options.headless = True #newly added
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver: #modified
driver.get(url)
如果您运行代码,您将在命令行/终端上看到只有少量信息。
没有 Chrome 出现并侵入我们的屏幕。
但是代码是否成功到达页面?如何验证爬虫是否打开了正确的页面?有没有错误?这些是您在无头执行 Python Selenium 时提出的一些问题。
您的代码必须根据需要创建一个日志来解决上述问题。
日志可能会有所不同,这取决于您的需要。它可以是文本格式的日志文件、专用的日志数据库或终端上的简单输出。
为简单起见,我们将通过在终端上输出抓取结果来创建日志。让我们在下面添加两行代码来打印页面 URL 和标题。这将确保 Python Selenium 无头运行按需要运行。
# ...
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
# ...
print("Page URL:", driver.current_url)
print("Page Title:", driver.title)
我们的爬虫不会得到意想不到的结果,这太棒了。既然已经完成了,让我们去抓取一些口袋妖怪数据。
第 3 步:抓取数据
在深入之前,我们需要找到保存数据的 HTML 元素,这可以使用真正的浏览器检查网页来完成。为此,只需右键单击 任何图像并选择Inspect。Chrome DevTools 将在“元素”选项卡上打开。
从显示的元素中,让我们继续查找包含名称、价格和其他信息的元素。浏览器会高亮选中元素覆盖的区域,方便我们识别正确的元素。

<a href="https://scrapeme.live/shop/Bulbasaur/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link">
要获取名称元素,只需将鼠标悬停在名称上,直到无头浏览器突出显示它。

<h2 class="woocommerce-loop-product__title">Bulbasaur</h2>
h2 元素保留在父元素内。让我们将该元素放入代码中,以便 Selenium Python 中的 headless chrome 可以识别应从页面中提取哪个元素。Selenium 提供了多种选择和提取所需元素的方法,例如使用元素 ID、标签名称、类、CSS 选择器和XPath。让我们使用 XPath 方法。
稍微调整初始代码将使抓取工具显示更多信息,例如 URL、标题和口袋妖怪的名称。这是我们的新代码的样子:
#...
from selenium.webdriver.common.by import By
#...
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
#...
pokemons_data = []
parent_elements = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
print(pokemon_name.text)
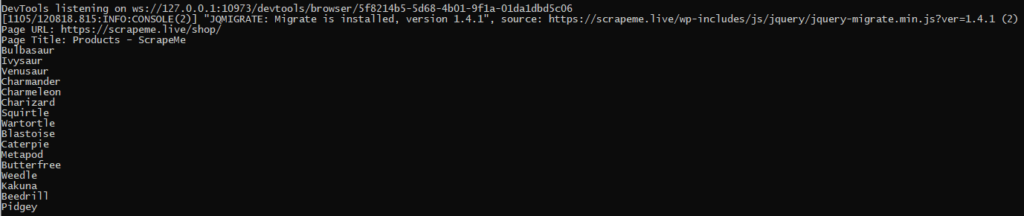
接下来,让我们从父元素下的 href 属性中提取 Pokemon 链接。这个 HTML 标签将帮助抓取工具发现链接。

<a href="https://scrapeme.live/shop/Bulbasaur/" class="woocommerce-LoopProduct-link woocommerce-loop-product__link">
既然我们解决了这个问题,让我们添加一些代码来帮助我们的爬虫提取和存储名称和链接,然后我们可以使用 Python 字典来管理数据,这样它们就不会混淆了。字典将包含每个口袋妖怪的数据。
#...
parent_elements = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
pokemon_link = parent_element.get_attribute("href")
temporary_pokemons_data = {
"name": pokemon_name.text,
"link": pokemon_link
}
pokemons_data.append(temporary_pokemons_data)
print(temporary_pokemons_data)

现在让我们获取我们需要的最后一条 Pokemon 数据,即价格。
让我们跳到真正的浏览器并快速检查保存价格的元素。然后我们可以在代码中插入一个 span 标签,让爬虫知道哪个元素包含价格。

#...
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
pokemon_link = parent_element.get_attribute("href")
pokemon_price = parent_element.find_element(By.XPATH, ".//span")
temporary_pokemons_data = {
"name": pokemon_name.text,
"link": pokemon_link,
"price": pokemon_price.text
}
print(temporary_pokemons_data)
唯一剩下的就是运行脚本,瞧,我们得到了所有的口袋妖怪数据。

万一你迷路了,完整的代码应该是这样的:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
url = "https://scrapeme.live/shop/"
options = webdriver.ChromeOptions()
options.headless = True
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options) as driver:
driver.get(url)
print("Page URL:", driver.current_url)
print("Page Title:", driver.title)
parent_elements = driver.find_elements(By.XPATH, "//a[@class='woocommerce-LoopProduct-link woocommerce-loop-product__link']")
for parent_element in parent_elements:
pokemon_name = parent_element.find_element(By.XPATH, ".//h2")
pokemon_link = parent_element.get_attribute("href")
pokemon_price = parent_element.find_element(By.XPATH, ".//span")
temporary_pokemons_data = {
"name": pokemon_name.text,
"link": pokemon_link,
"price": pokemon_price.text
}
print(temporary_pokemons_data)
什么是最好的无头浏览器?
Selenium 无头 Python 并不是唯一的无头浏览器,因为还有其他替代品,一些只提供一种编程语言,而另一些则提供对多种语言的绑定。
除了 Selenium,这里有一些最好的无头浏览器可用于您的抓取项目。
1.ZenRows
ZenRows是一种一体化的网络抓取工具,它使用单个 API 调用来处理所有反机器人绕过,从旋转代理和无头浏览器到验证码。提供的住宅代理可帮助您抓取网页并像真实用户一样浏览而不会被阻止。
ZenRows 适用于几乎所有流行的编程语言,您可以利用正在进行的免费试用,无需信用卡。
2.Puppeteer
Puppeteer是一个 Node.js 库,提供 API 以在无头模式下操作 Chrome/Chromium。谷歌于 2017 年开发了它,并且一直保持增长势头。它可以使用 DevTools 协议完全访问 Chrome,使 Puppeteer 在处理 Chrome 时优于其他工具。
Puppeteer 也比 Selenium 更容易设置并且速度更快。缺点是它只适用于 JavaScript 语言。因此,如果您不熟悉该语言,您会发现使用 Puppeteer 具有挑战性。
3. HtmlUnit
这种无头浏览器是用于 Java 程序的无 GUI 浏览器,如果配置得当,它可以模拟特定的浏览器(即 Chrome、Firefox 或 Internet Explorer)。JavaScript 支持相当不错,而且还在不断增强。不幸的是,您只能将HtmlUnit与 Java 语言一起使用。
4.Zombie.JS
Zombie.JS是一个用于测试客户端 JavaScript 代码的轻量级框架,也可用作 Node.js 库。因为主要目的是为了测试,所以它可以完美地运行在测试框架上。与 Puppeteer 类似,您只能使用 JavaScript 语言来使用 Zombie.JS。
5.Playwright
Playwright本质上是一个用于浏览器自动化的 Node.js 库,但它为其他语言(如 Python、.NET 和 Java)提供 API。与 Python Selenium 相比,它相对较快。
结论
Python 无头浏览器为网络抓取过程提供了好处。例如,它最大限度地减少了内存占用,完美地处理了 JavaScript,并且可以在无 GUI 环境中运行,此外,实现只需要几行代码。
在本指南中,我们通过分步指南在 Selenium Python 中使用 headless chrome 从网页中抓取数据。
本指南中讨论的 Python 无头浏览器的一些缺点是:
- 它无法评估图形元素,因此,您将无法在无头模式下执行任何需要视觉交互的操作。
- 很难调试。






