

如何用Selenium绕过验证码
排名前 100,000 的网站中有三分之一使用 CAPTCHA 来阻止机器人流量,因此它们可能在某些时候使您的抓取计划变得复杂。
今天,您将学习如何使用三种不同的方法在 Python 中使用 Selenium绕过验证码:
Selenium 可以绕过验证码吗?
验证码通常在访问者表现出可疑的类似机器人的行为时出现,例如在不滚动的情况下访问许多页面,但 Selenium 可以在这方面提供帮助。
有两种主要方法可以摆脱测试:您可以通过付钱给人工来解决它们(大规模昂贵,但有时很有用),或者通过实施高级技术来防止它们出现(如果失败则重试您的请求)。Selenium 允许您在第一种情况下与表单进行交互,并在第二种情况下使您的流量看起来更人性化。
方法#1:使用 Selenium 和 2Captcha 绕过验证码
假设您需要解析一个 CAPTCHA,例如,提交一个表单。我们将使用一个名为 2Captcha 的流行服务来使用演示页面来处理 Selenium 中的 CAPTCHA 。
我们将探讨该服务如何应对流行的CAPTCHA 挑战。因此,让我们开始安装一些依赖项。如果您还没有它们,请运行pip install selenium webdriver_manager twocaptcha命令并导入一些模块,如下所示。
from selenium.webdriver.common.by import By from twocaptcha import TwoCaptcha from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.service import Service as ChromeService import time
然后,打开一个 Chrome 实例并导航到演示页面。
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install())) url='https://2captcha.com/demo/normal' driver.get(url)
下一步是定位 CAPTCHA 图像并将其 URL 传递给solver.normal()返回文本解决方案的方法。将其保存在result变量中。
imgResults = driver.find_elements(By.XPATH,"//img[contains(@class,'_17bwEOs9gv8ZKqqYcEnMuQ')]")
solver = TwoCaptcha('Your 2Captcha API key Goes Here')
result=solver.normal(imgResults[0].get_attribute('src'))
下面的任务是找到输入框,填写2Captcha服务收到的解决方案文本,然后点击提交按钮。
captchafield = driver.find_element(By.XPATH,"//input[contains(@class,'GVz3xTybpzDffiIixH8JZ')]") captchafield.send_keys(result['code']) driver.find_element(By.XPATH,"//button[contains(@class, '_2iYm2u0v9LWjjsuiyfKsv4 _1z3RdCK9ek3YQYwshGZNjf _3zBeuZ3zVV-s2YdppESngy _28oc7jlCOdc1KAtktSUZvQ')]").click() time.sleep(10)
最后,找到<p>页面上的元素并打印其消息。如果成功,您应该得到“验证码已成功通过!”。
messagefield=driver.find_element(By.XPATH,"//p[contains(@class,'j4U8b8WW7BD_DOSsopoys')]") print (messagefield.text)
这是完整的代码:
from selenium.webdriver.common.by import By
from twocaptcha import TwoCaptcha
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
import time
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()))
url='https://2captcha.com/demo/normal'
driver.get(url)
imgResults = driver.find_elements(By.XPATH,"//img[contains(@class,'_17bwEOs9gv8ZKqqYcEnMuQ')]")
solver = TwoCaptcha('Your 2Captcha API key Goes Here')
result=solver.normal(imgResults[0].get_attribute('src'))
print ('solved: ' + str(result))
captchafield = driver.find_element(By.XPATH,"//input[contains(@class,'GVz3xTybpzDffiIixH8JZ')]")
captchafield.send_keys(result['code'])
driver.find_element(By.XPATH,"//button[contains(@class, '_2iYm2u0v9LWjjsuiyfKsv4 _1z3RdCK9ek3YQYwshGZNjf _3zBeuZ3zVV-s2YdppESngy _28oc7jlCOdc1KAtktSUZvQ')]").click()
time.sleep(10)
messagefield=driver.find_element(By.XPATH,"//p[contains(@class,'j4U8b8WW7BD_DOSsopoys')]")
print (messagefield.text)
这是输出:
solved: {'captchaId': '72848141048', 'code': 'W9H5K'}
Captcha is passed successfully!
然而,使用付费求解器很难扩大规模,因为它既昂贵又缓慢,而且它们只适用于所有验证码类型中的一小部分。因此,让我们看看接下来的替代方案。
方法 #2:实施 Selenium Stealth
Selenium 的使用很容易被识别,因为它的基本版本会发送一些明确的机器人信号,例如它的 User-Agent 名称,这可能很容易提示验证码。为了证明这一点,让我们尝试访问受保护的站点OpenSea 。
为此,创建一个无头 Chrome 实例,将目标 URL 传递给函数get()以等待页面加载,并截取屏幕截图。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options, service=ChromeService(
ChromeDriverManager().install()))
driver.get("https://opensea.io/")
time.sleep(30)
driver.save_screenshot("opensea.png")
driver.close()
结果如何?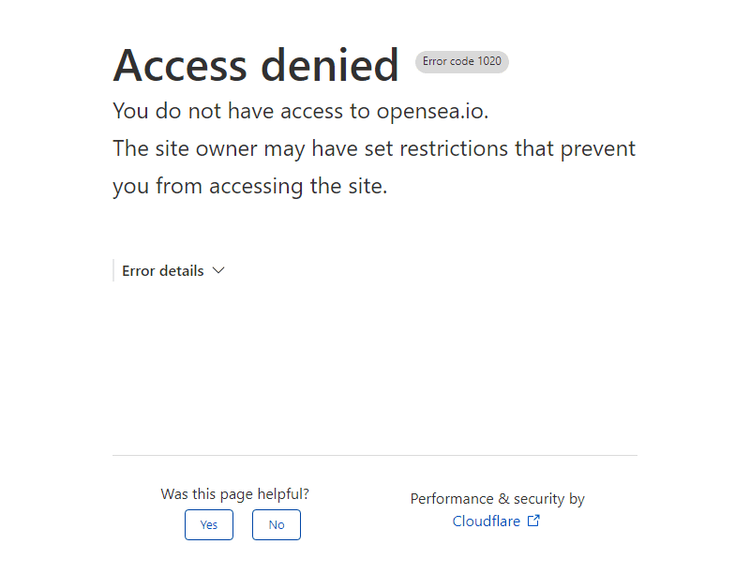
拒绝访问!OpenSea 检测到非人类流量并阻止了我们的机器人。这就是selenium-stealth Python 包的用武之地,它使我们的流量看起来更加手动,从而防止被阻塞,即使用验证码。
首先,安装 Stealth 包。
pip install selenium-stealth
然后,导入一些必要的库并配置驱动程序以在无头模式下运行 Chrome。接下来,配置、排除enable-automation和禁用,useAutomationExtension因为网站使用这些标志检测机器人流量。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
import time
from selenium_stealth import stealth
options = Options()
options.add_argument("--headless")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
以下步骤是关于使用该ChromeDriverManager().install()方法的,该方法会自动下载并安装相应版本的 ChromeDriver 可执行文件。
driver = webdriver.Chrome(options=options, service=ChromeService( ChromeDriverManager().install()))
现在,让我们使用该stealth()函数来设置自定义 Chrome 网络驱动程序配置,以使我们的机器人不易被发现。例如,我们将设置一个用户代理字符串,它与 HTTP 请求一起发送。
stealth(driver,
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.5481.105 Safari/537.36',
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
然后脚本导航到目标页面,等待它加载,并对其进行截图。
driver.get("https://opensea.io/")
time.sleep(30)
driver.save_screenshot("opensea.png")
driver.close()
这是完整的代码:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
import time
from selenium_stealth import stealth
options = Options()
options.add_argument("--headless")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options, service=ChromeService(
ChromeDriverManager().install()))
stealth(driver,
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.5481.105 Safari/537.36',
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
driver.get("https://opensea.io/")
time.sleep(30)
driver.save_screenshot("opensea.png")
driver.close()
让我们看看输出:

这有助于使用 Selenium 绕过 CAPTCHA。
然而,selenium-stealth 是否会使用最严格的反机器人保护来抓取站点?尝试使用G2 上的产品评论页面,您会得到答案。

由于这两种方法足以绕过 Selenium 的验证码,我们应该探索更好的选择。
方法#3:使用 ZenRows API 绕过验证码
从具有高级保护的网站上抓取内容需要正确的工具。ZenRows 是一个强大的反机器人 API,为您提供无头浏览器功能,还可以通过摆脱反机器人保护(包括 CAPTCHA)来实现大规模抓取。
首先,注册免费 API 密钥。您将进入 Request Builder,您必须在其中输入<https://www.g2.com/products/asana/reviews>目标 URL,然后激活Premium Proxy、JavaScript Rendering和Antibot。

其次,将 API 请求代码复制并粘贴到您的 Python IDE。它应该是这样的:
# python3 and requests library required
# pip install requests
import requests
response = requests.get("https://api.zenrows.com/v1/?apikey=Your_ZenRows_API_Key&url=https%3A%2F%2Fwww.g2.com%2Fproducts%2Fasana%2Freviews%2F&js_render=true&antibot=true&premium_proxy=true")
print(response.text)
第三步也是最后一步,执行代码并观察它打印 G2 的 HTML。

结论
我们已经了解了如何使用付费求解器使用 Selenium 绕过 CAPTCHA,但将其用作独立解决方案被证明是不可靠且昂贵的。然后,我们安装了一个基于 Selenium 的插件,这可能有助于大规模抓取,但效果不佳。为了成功检索数据,您需要一个完全依赖的强大工具来处理 CAPTCHA。






