

如何在Python中使用cfscrape绕过Cloudflare
如果您曾经尝试抓取受 Cloudflare 反机器人保护的网站,您就会知道被它阻止或减慢速度的挫败感。但是不要再害怕了,因为 cfscrape 来拯救世界了!
在这个 cfscrape 教程中,我们将探索这个 Python 模块的魔力,它允许您绕过 Cloudflare 保护并轻松抓取网站:从在 Python 中设置它到实际场景和需要注意的常见错误。
因此,掌握您的 Python 技能,让我们在没有反机器人措施的情况下进入网络抓取的世界。
什么是 cfscrape?
简单来说,cfscrape 是一个 Python 模块,允许用户在网页抓取时绕过 Cloudflare 的反机器人保护系统。

当用户访问已实施 Cloudflare 保护的网站时,用户的浏览器会收到JavaScript 质询,其中包含访问该网站必须完成的一系列任务。这些任务可以包括解决验证码、完成 JavaScript 难题或执行一些计算。
目的是区分人类用户和机器人,以防止后者访问网站并可能造成危害,例如发起 DDoS 攻击。但是,对于出于合法目的(例如网络抓取)而尝试访问该网站的用户来说,这也可能是一个问题。这就是 cfscrape 发挥作用的地方。
GitHub 上的社区开发的 Python 库通常通过模拟网络浏览器成功绕过挑战,从而使网站相信请求来自实际用户而不是爬虫。
现在我们已经对什么是 cfscrape 及其工作原理有了基本的了解,让我们深入了解如何在 Python 中设置和使用它。
你如何使用 cfscrape?
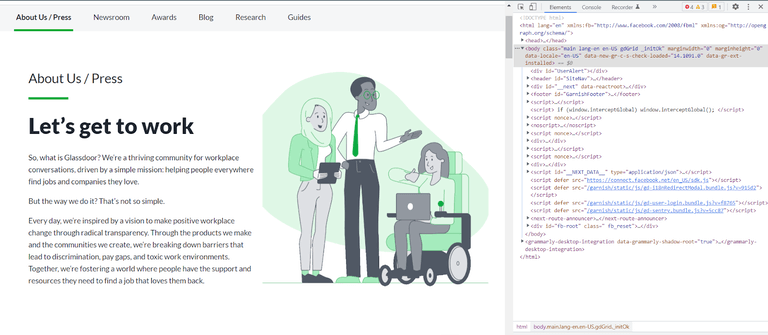
假设您正在尝试抓取受 Cloudflare 保护的Glassdoor网站。您尝试使用标准requests库通过简单的爬虫访问网站:
import requests
scraper = requests.get('https://www.glassdoor.com')
print(scraper.text)
但是,您并没有提取所需的数据,而是突然看到一个Status 403 Forbidden响应。
<!doctype html><html lang="en"><head><title>HTTP Status 403 Forbidden</title>…
通常,此类错误是由于网站的保护措施将您标记为机器人并阻止您尝试连接而导致的。
现在让我们看看如何通过充分利用 cfscrape 来解决这个问题。
如何在 Python 中使用 cfscrape?
按照以下步骤在 Python 中使用 cfscrape 以抓取受 Cloudflare 保护的网站。
第一步:安装cfscrape
首先,通过在终端中运行以下命令来安装 cfscrape:
pip install cfscrape
第 2 步:编写您的爬虫代码
安装模块后,通过导入在 Python 代码中使用它,然后调用该create_scraper()函数来创建scraper对象。get()现在,通过调用其方法并传入网站的 URL 作为参数,使用该对象访问受 Cloudflare 保护的网站:
import cfscrape
scraper = cfscrape.create_scraper()
response = scraper.get('https://www.glassdoor.com/about')
print(response.text)
with open('./file.html', '+w') as file:
file.write(response.text)
该方法response返回的对象get()将包含网站的 HTML,然后您可以像处理任何其他 HTML 内容一样对其进行解析或抓取。
就是这样!只需几行代码,您就可以轻松绕过 Cloudflare 保护并使用 cfscrape 和 Python 抓取网站。
第 3 步:将 cfscrape 与其他库相结合
等等,还有更多!cfscrape 的一大优点是它可以轻松地与其他 Python 库结合使用。例如,您可以使用 cfscrape 绕过 Cloudflare 保护,然后使用像 BeautifulSoup 这样的库从 HTML 内容中解析和提取数据。
在上面的示例中,我们曾经向Glassdoorcfscrape发送请求并检索 HTML 内容。然后,对象被传递给,它解析 HTML 并提取特定的数据元素,例如页面上显示的图像的 URL。get()responseBeautifulSoup
import cfscrape
from bs4 import BeautifulSoup
scraper = cfscrape.create_scraper()
response = scraper.get('https://www.glassdoor.com/about')
soup = BeautifulSoup(response.text, 'html.parser')
# To return src attribute of all images on the page
for img in soup.find_all('img'):
print(img.get('src'))
这是我们的输出:
https://about-us.glassdoor.com/app/uploads/sites/2/2022/10/2022_about-us-hero_x.svg https://about-us.glassdoor.com/app/uploads/sites/2/2022/10/2022_about-us-for-job-seekers_x-1.svg https://about-us.glassdoor.com/app/uploads/sites/2/2022/10/2022_about-us-for-employees_x-1.svg …
如您所见,通过将 cfscrape 与其他 Python 模块结合使用,您可以轻松构建功能强大的网络抓取工具。
但是,有时您可能需要处理错误,所以让我们了解哪些错误!
解决 cfscrape 中的常见错误
在使用 cfscrape 时,您可能会遇到几个常见错误:
ConnectionError让我们知道连接到网站的问题。如果网站已关闭或您的互联网连接有问题,就会发生这种情况。CloudflareCaptchaError表示 Cloudflare 检测到请求是由机器人发出的,并提出了验证码挑战。在这种情况下,您需要手动解决验证码或尝试再次访问它。CloudflareChallengeError当 cfscrape 无法自动解决 Cloudflare 挑战时返回。如果提出的挑战发生变化或 cfscrape 中存在错误,则可能会发生这种情况。在这种情况下,您需要更新 cfscrape 或尝试使用其他库来绕过 Cloudflare 的保护,例如ZenRows。
要处理它们,请使用try和except语句来捕获使用 cfscrape 时可能发生的任何错误。如果捕获到错误,except将执行相应的块,您可以根据需要处理错误。如果没有错误发生,else将执行该块,您可以根据需要处理响应。
import cfscrape
try:
# Create a scraper object
scraper = cfscrape.create_scraper()
# Use the scraper object to access the website
response = scraper.get(your_url)
except cfscrape.ConnectionError:
# Handle connection error
except cfscrape.CloudflareCaptchaError:
# Handle captcha error
except cfscrape.CloudflareChallengeError:
# Handle challenge error
else:
# Process the response as needed
…
cfscrape 和替代方案的局限性
此外,尽管 cfscrape 是绕过反机器人保护的宝贵工具,但需要注意的是,它可能不足以绕过 Cloudflare 实施的最新安全措施,因为它近年来没有更新。
看看这个例子:

当尝试使用 cfscrape 访问G2.com 上的 Asana 页面时,反机器人服务会检测到自动浏览器会话并阻止尝试,从而产生一条Access denied消息。
<!DOCTYPE html>
<html lang="en-US">
<head>
<title>Access denied</title>
要像老板一样抓取 G2 网页,请注册以在几秒钟内获得免费的 API 密钥并尝试以下操作:
# pip install zenrows
from zenrows import ZenRowsClient
client = ZenRowsClient("YOUR_API_KEY")
url = "https://www.g2.com/products/asana/reviews"
# Enable JavaScript rendering, Antibot and Premium proxy features
params = {
"js_render": "true",
"antibot": "true",
"premium_proxy": "true"
}
response = client.get(url, params=params)
print(response.text)
URL 被传递给该client.get()方法,由于 ZenRows 的反机器人和高级代理功能,Cloudflare 的保护被顺利绕过。没有更多令人沮丧的块或错误。

此外,就像使用 cfscrape 一样,您可以将 ZenRows 与其他库结合使用。
结论
本教程涵盖了使用 cfscrape 的基础知识,cfscrape 是一个 Python 模块,用于在进行 Web 抓取时绕过 Cloudflare 的反机器人保护措施。此外,我们还讨论了您在使用 cfscrape 时可能遇到的一些常见错误以及如何处理这些错误。
总体而言,虽然 cfscrape 是绕过 Cloudflare 保护的有用工具,但代理因其易用性、全面的功能集和可靠性而成为更好的选择。






