

如何利用Python进行数据分析
我们将演示您可以在短短几分钟内从下载数据集到从中获取有价值的见解。您可以获得来自德国的高质量CSV 格式的汽车数据集,其中包含超过 45000 条记录。
先决条件
为了使代码正常工作,您需要安装 python3。有些系统已经预装了它。之后 ,通过运行安装所有必需的库
,通过运行安装所有必需的库pip install。
pip install pandas matplotlib squarify seaborn
首先,从数据集文件导入数据。创建 python 文件或在包含 CSV 文件的文件夹中打开控制台。Pandas 带有一个方便的函数来从文件路径或缓冲区read_csv创建一个。DataFrame
导入该库并使用数据集文件的本地路由调用该函数。在我们的例子中,它是一个相对路径。它将生成一个名为cars的变量,其中包含文件中的所有数据。
import pandas as pd
cars = pd.read_csv('./germany-cars-zenrows.csv')
探索性数据分析
一旦我们可以访问数据,我们就可以开始在我们的代码中使用它。问题是,我们可能对它的内容甚至结构一无所知。
此命令将显示包含 20 行的示例。您可以在下面看到一个总结的示例。
cars.sample(frac=1).head(n=20)
| 里程 | 制作 | 模型 | 燃料 | 档位 | 报价类型 | 价格 | 生命值 | 年 |
|---|---|---|---|---|---|---|---|---|
| 17700 | 福特 | 久贺 | 汽油 | 手动的 | 用过的 | 16990 | 150.0 | 2017年 |
| 4000 | 日产 | 纳瓦拉 | 柴油机 | 自动的 | 示范 | 37290 | 190.0 | 2025年 |
| 33000 | 奔驰 | 四人 | 汽油 | 手动的 | 用过的 | 8500 | 71.0 | 2015年 |
| 70000 | 斯柯达 | 室斯特 | 汽油 | 自动的 | 自动 | 9890 | 105.0 | 2013年 |
| 75581 | 日产 | 笔记 | 汽油 | 手动的 | 用过的 | 6990 | 80.0 | 2014年 |
在这里,我们可以看到Fuel、gear和OfferType等字段的几个可能值。我们将打印它们独特的值,以了解它们的数量以及如何对待它们。
下面介绍的是装备和报价类型的输出。燃料有很多种类型,我们稍后将对其进行分组。
cars.gear.unique() # ['Manual' 'Automatic' 'Semi-automatic'] cars.offerType.unique() # ['Used' 'Demonstration' "Employee's car" 'Pre-registered' 'New']
我们将describe包含数值的字段。它将显示每列的描述性统计数据,例如平均值或标准差。这里应用一个技巧来避免科学记数法并显示一些更清晰的输出。
我们可以发现一些异常值,也可能发现一些错误——比如一辆马力为 1 马力的汽车——但我们会在以后的文章中担心它们。
(cars.describe(percentiles=[.01, .25, .5, .75, .99]).apply(
lambda s: s.apply('{0:.2f}'.format)))
| 里程 | 价格 | 生命值 | 年限 | |
|---|---|---|---|---|
| 数量 | 46405.00 | 46405.00 | 46376.00 | 46405.00 |
| 平均 | 71177.86 | 16572.34 | 132.99 | 2016.01 |
| 标准 | 62625.31 | 19304.70 | 75.45 | 3.16 |
| 分钟 | 0.00 | 1100.00 | 1.00 | 2011.00 |
| 1% | 5.00 | 3299.00 | 60.00 | 2011.00 |
| 25% | 19800.00 | 74900.00 | 86.00 | 2013.00 |
| 50% | 60000.00 | 10999.00 | 116.00 | 2016.00 |
| 75% | 105000.00 | 19490.00 | 150.00 | 2019.00 |
| 99% | 259633.64 | 83490.00 | 2021.00 | 2019.00 |
| 最大限度 | 1111111.00 | 1199900.00 | 850.00 | 2021.00 |
现在我们对数据和列包含的内容有了更深入的了解。我们可以从数据可视化开始。我们现在将了解如何进行分配,然后继续进行价格预测。
可视化汽车品牌
为了显示数据集中的前 20 个品牌,我们将按值计数对它们进行分组。这意味着我们将创建一个仅包含品牌及其计数的新数据框,即“Volkswagen 6931”。
然后对它们进行排序并取前 20 个。最后一行将重命名这些列以供以后操作。
我们将计算每个品牌的平均价格以及商品数量。
首先,根据原始数据集中的品牌对汽车进行分组,并将其平均值提取到新的DataFrame. 另外,重置索引。
然后,将平均价格合并回品牌DataFrame。现在它将包含品牌、尺寸和价格列。
group = cars.groupby(cars.make) mean_price = pd.DataFrame(group.price.mean()) mean_price.reset_index(level=0, inplace=True) makes = pd.merge(makes, mean_price, how='left', on='make')
这部分的最后一步是显示图表。需要两个新的导入来绘制它。
我们将首先创建显示品牌、商品数量和平均价格的标签。
接下来,使用squarify划分矩形并根据项目数量调整大小。基本参数是尺寸和标签。其余的纯粹是装饰性的。
最后两行用于隐藏轴并显示绘图。根据您的环境,最后一步可能不是必需的。
import matplotlib.pyplot as plt
import squarify
labels = ["%sn%d itemsnMean price: %d€" % (label) for label in
zip(makes['make'], makes['size'], makes['price'])]
squarify.plot(sizes=makes['size'], label=labels, alpha=.8,
color=plt.cm.tab20c.colors, edgecolor="white", linewidth=2)
plt.axis('off')
plt.show()
可视化燃料类型
我们现在来看看燃料,但将电力和其他分组。
cars['fuel'] = cars['fuel'].replace(
['Electric/Gasoline', 'Electric/Diesel', 'Electric'],
'Electric')
cars['fuel'] = cars['fuel'].replace(
['CNG', 'LPG', 'Others', '-/- (Fuel)', 'Ethanol', 'Hydrogen'],
'Others')
然后计算总计,与之前的情况类似,但现在绘制饼图。该代码块较长,但看起来像最后一个,因此无需解释太多。
总结一下,创建一个包含值计数、按燃料分组和提取方式的新数据框。然后,合并这两个。像以前一样准备标签并绘制饼图。
fuels = pd.DataFrame(cars['fuel'].value_counts())
group = cars.groupby(cars['fuel'])
mean_price = pd.DataFrame(group.price.mean())
mean_price.reset_index(level=0, inplace=True)
fuels.reset_index(level=0, inplace=True)
fuels.columns = ('fuel', 'size')
fuels = pd.merge(fuels, mean_price, how='left', on='fuel')
labels = ["%sn%d itemsnMean price: %d€" % (label) for label in
zip(fuels['fuel'], fuels['size'], fuels['price'])]
fig1, ax1 = plt.subplots()
ax1.pie(fuels['size'], labels=labels,
autopct='%1.1f%%', startangle=15, colors=plt.cm.Set1.colors)
ax1.axis('equal')
plt.show()
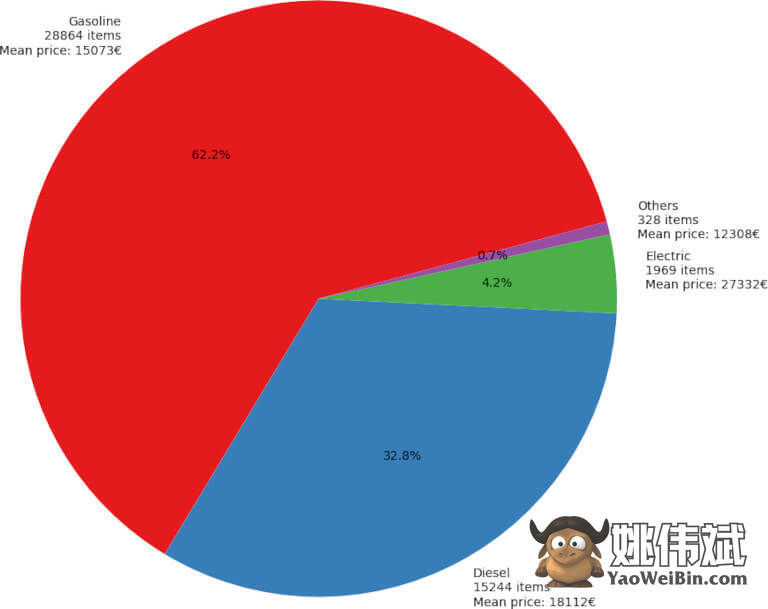
每年的燃料类型
在这种探索性分析中,有时我们会尝试一些事情或跟随直觉。在这种情况下,我们认为电动汽车正在变得流行,而柴油汽车正在(相对)下降。
为了测试这一点,我们只需要创建一个countplot:计算每年数据集中有多少种燃料类型的汽车。我们将显示上一步中分组后的结果。这将避免一些噪音并将相似的燃料类型绘制在一起(即电力和电力/汽油)。
我们将使用seaborn图书馆。只需要x 轴的年份和分组的燃料,它将自动处理其余的事情。
import seaborn as sns sns.countplot(x="year", hue="fuel", data=cars) plt.show()
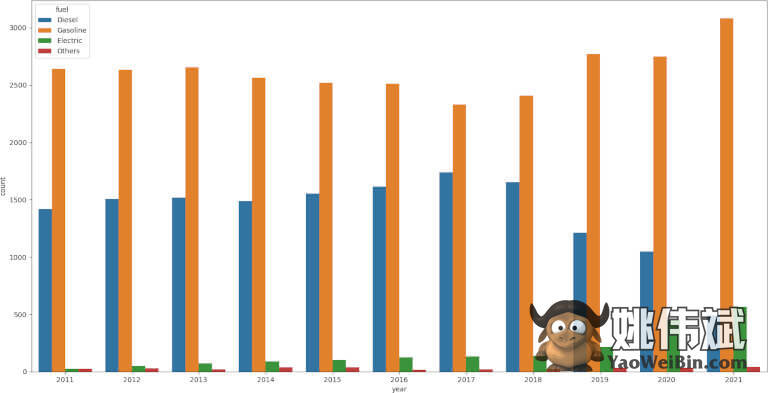
我们是对的,但这不是重点。就是我们用一个简单的图表在几分钟内证明了我们的假设。
价格怎么样?
您可能注意到,我们甚至没有提到哪一列可能是最相关的:价格。这不是我们这边的失误。
我们将编写第二部分,解释价格与其他变量的关系,并比较不同的价格预测算法。
请在下面订阅,以便我们在发布时分享。再也不会错过精彩内容!
更新:您可以继续阅读第二部分。
结论
正如我们所见,将 CSV 数据导入 python pandas 相对容易。当我们开始寻找见解时,事情变得更加复杂。一些简单的函数,如 head 或describe 将为我们提供很多信息。
有了所有这些早期知识,我们可以使用图表来可视化数据的分布方式,甚至变量如何演变(例如燃料类型)。我们可以利用这些知识来形成假设并快速证明或反驳它们。






