

如何使用JS和Node.js爬取网页内容
Javascript 和网络抓取都在增加。我们将把它们结合起来,使用 NodeJS 中的 Javascript 从头开始构建一个爬虫和爬虫。
避免块是网站抓取的重要组成部分。因此,我们还将添加一些功能来帮助解决这方面的问题。最后,借助Node 的事件循环,并行化任务以加快速度。
按照本教程学习如何使用 Node 和 Javascript 进行网络抓取!
准备工作
要使代码正常运行,您需要安装Node(或nvm)和 npm。有些系统已经预装了它。之后,通过运行安装所有必需的库npm install。它将创建一个包含所有依赖项的 package.json 文件。
npm init -y npm install axios cheerio playwright
JS抓取工具介绍
我们使用的是 Node v12,但您始终可以检查每个功能的兼容性。
Axios是一个“基于承诺的 HTTP 客户端”,我们将使用它从 URL 获取 HTML。它允许多个选项,例如标头和代理,我们将在后面介绍。如果你使用 TypeScript,它们包括“定义和 Axios 错误的类型保护”。
Cheerio是一个“快速、灵活和精简的核心 jQuery 实现”Javascript 库。它让我们可以使用选择器找到 DOM 节点,获取文本或属性,以及许多其他事情。我们会将 HTML 传递给 cheerio,然后查询它以提取数据。就像我们在浏览器环境中一样。
Playwright “是一个 Node.js 库,可以通过单个 API 自动化 Chromium、Firefox 和 WebKit。” 当 axios 不够时,我们将使用无头浏览器获取 HTML。然后它将解析内容,执行 Javascript 并等待异步内容加载。
Node JS 适合网页抓取吗?
正如您在上面看到的,工具可用,技术也得到整合。它们都被广泛使用并得到妥善维护。
除了这些之外,它们中的每一个都有几种替代方案。还有更多专注于一项任务,例如table scraper。Javascript 网络抓取生态系统非常庞大!
如何使用 Javascript 抓取网页?
我们首先需要的是 HTML。我们为此安装了 Axios,它的用法很简单。我们将以scrapeme.live为例,这是一个为抓取准备的假网页。
const axios = require('axios');
axios.get('https://scrapeme.live/shop/')
.then(({ data }) => console.log(data));
好的!然后,我们可以使用 cheerio 查询我们现在想要的两件事:分页链接和产品。我们将查看打开 Chrome DevTools 的页面,以了解如何执行此操作。所有现代网络浏览器都提供诸如此类的开发人员工具。选择你最喜欢的。
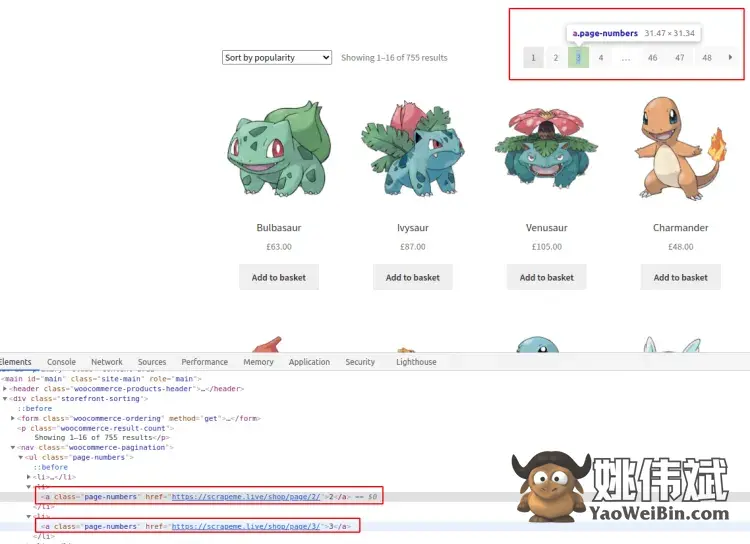
感兴趣的部分我们用红色标注出来了,大家可以自行尝试。在这种情况下,所有的CSS 选择器都很简单,不需要嵌套。如果您正在寻找不同的结果或无法选择它,请查看指南。您还可以使用 DevTools 获取选择器。
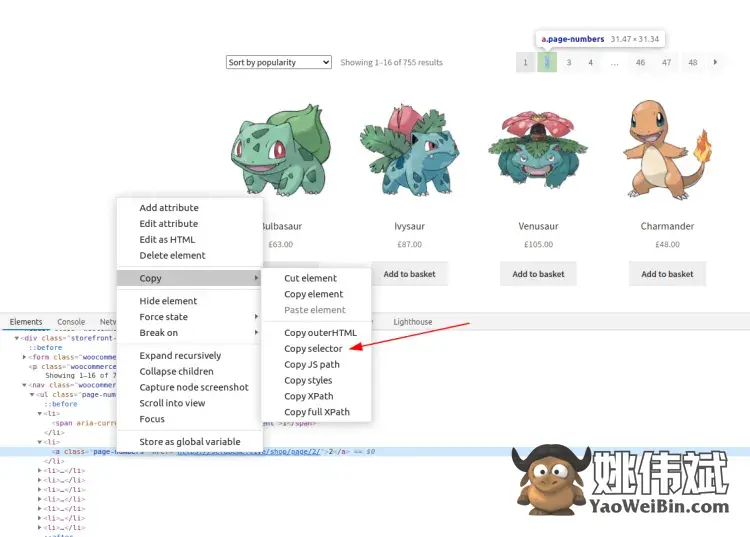
在元素选项卡上,右键单击节点 ➡ 复制 ➡ 复制选择器。但结果通常与 HTML 非常耦合,如本例所示:#main > div:nth-child(2) > nav > ul > li:nth-child(2) > a.
这种方法将来可能会出现问题,因为它会在任何微小的更改后停止工作。此外,它只会捕获其中一个分页链接,而不是全部。
您可以在控制台选项卡上执行 Javascript 并检查选择器是否正常工作。将选择器传递给document.querySelector函数并检查输出。在网页抓取时记住这个技巧。😉
我们可以捕获页面上的所有链接,然后按内容过滤它们。如果我们要编写一个全站爬虫,那将是正确的方法。
在我们的例子中,我们只需要分页链接。使用提供的类,.page-numbers a将捕获它们。href然后从中提取 URL( s)。CSS 选择器会将所有链接节点与包含该类的祖先相匹配page-numbers。
const axios = require('axios');
const cheerio = require('cheerio');
const extractLinks = $ => [
...new Set(
$('.page-numbers a') // Select pagination links
.map((_, a) => $(a).attr('href')) // Extract the href (url) from each link
.toArray() // Convert cheerio object to array
),
];
axios.get('https://scrapeme.live/shop/').then(({ data }) => {
const $ = cheerio.load(data); // Initialize cheerio
const links = extractLinks($);
console.log(links);
// ['https://scrapeme.live/shop/page/2/', 'https://scrapeme.live/shop/page/3/', ... ]
});
将上面的内容存到一个文件中,在NodeJS中执行,可以看到结果。
至于产品(在本例中为 Pokémon),我们将获得 ID、名称和价格。查看下图以了解有关选择器的详细信息,或自行重试。我们现在只会记录抓取的数据。检查将它们添加到数组的最终代码。
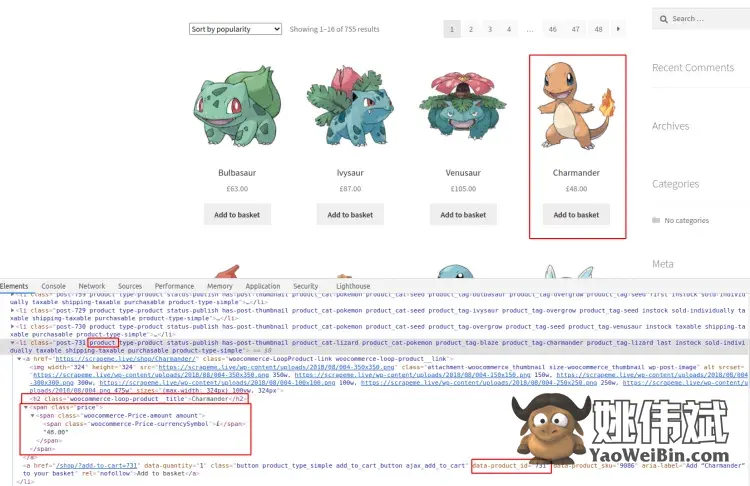
正如您在上面看到的,所有产品都包含 class product,这使我们的工作更容易。对于它们中的每一个,h2标签和price节点都包含我们想要的内容。
至于产品 ID,我们需要匹配一个属性,而不是类或 DOM 节点类型。这可以使用语法来完成node[attribute="value"]。我们只查找具有该属性的 DOM 节点,因此无需将其与任何特定值匹配。
const extractContent = $ =>
$('.product')
.map((_, product) => {
const $product = $(product);
return {
id: $product.find('a[data-product_id]').attr('data-product_id'),
title: $product.find('h2').text(),
price: $product.find('.price').text(),
};
})
.toArray();
// ...
const content = extractContent($);
console.log(content);
// [{ id: '759', title: 'Bulbasaur', price: '£63.00' }, ...]
正如您在上面看到的,没有错误处理。为了简洁起见,我们将在片段中省略它,但在现实生活中会考虑到它。大多数时候,返回默认值(即空数组)应该可以解决问题。
以下链接与 Cheerio API
现在我们有了一些分页链接,我们也应该访问它们。如果你运行整个代码,你会看到它们出现了两次——有两个分页栏。
我们将添加两个集合来跟踪我们已经访问过的内容和新发现的链接。自 ES2015 以来,集合就存在于 Javascript 中,并且所有现代 NodeJS 版本都支持它们。
我们使用它们而不是数组来避免处理重复项,但任何一个都可以。为避免抓取太多,我们还将包括一个最大值。
const maxVisits = 5;
const visited = new Set();
const toVisit = new Set();
toVisit.add('https://scrapeme.live/shop/page/1/'); // Add initial URL
我们将在下一部分使用async/await来避免回调和嵌套。异步函数是将基于承诺的函数编写为链的替代方法。同样,所有现代版本的 Node.js 都支持它。
在这种情况下,Axios 调用将保持异步。每页可能需要大约 1 秒,但我们按顺序编写代码而不需要回调。
这有一个小问题await is only valid in async function:这将迫使我们将初始代码包装在IIFE(立即调用的函数表达式)中。语法有点奇怪。它创建一个函数,然后立即调用它。
const crawl = async url => {
visited.add(url);
const { data } = await axios.get(url);
const $ = cheerio.load(data);
const content = extractContent($);
const links = extractLinks($);
links
.filter(link => !visited.has(link)) // Filter out already visited links
.forEach(link => toVisit.add(link));
};
(async () => { // IIFE
// Loop over a set's values
for (const next of toVisit.values()) {
if (visited.size >= maxVisits) {
break;
}
toVisit.delete(next);
await crawl(next);
}
console.log(visited);
// Set { 'https://scrapeme.live/shop/page/1/', '.../2/', ... }
console.log(toVisit);
// Set { 'https://scrapeme.live/shop/page/47/', '.../48/', ... }
})(); // The final set of parenthesis will call the function
网页抓取时避免阻塞
如前所述,我们需要避免块、验证码、登录墙和其他防御技术的机制。100% 地阻止它们是很复杂的。但是我们可以通过简单的努力获得很高的成功率。我们将应用两种策略:添加代理和全套标头。
代理
即使我们不推荐,也有免费代理。它们可能适用于测试,但并不可靠。我们可以使用其中一些进行测试,正如我们将在一些示例中看到的那样。
请注意,这些免费代理可能不适合您。他们的寿命很短。
另一方面,付费代理服务提供 IP 轮换。我们的网络抓取工具将以相同方式工作,但目标网站将看到不同的 IP。在某些情况下,他们会针对每个请求或每隔几分钟轮换一次。无论如何,它们更难被禁止。当它发生时,我们将在短时间后获得一个新的 IP。
我们将使用httpbin进行测试。它提供了一个具有多个端点的 API,这些端点将响应标头、IP 地址等。
const axios = require('axios');
const proxy = {
protocol: 'http',
host: '202.212.123.44', // Free proxy from the list
port: 80,
};
(async () => {
const { data } = await axios.get('https://httpbin.org/ip', { proxy });
console.log(data);
// { origin: '202.212.123.44' }
})();
HTTP 请求标头
下一步是检查我们请求的 HTTP 标头。最著名的是User-Agent(简称 UA),但还有更多。许多软件工具都有自己的工具,例如 Axios ( axios/0.21.1)。
通常,将实际标头与 UA 一起发送是一种很好的做法。这意味着我们需要一组真实的标头,因为并非所有浏览器和版本都使用相同的标头。我们在代码片段中包括两个:Linux 机器中的 Chrome 92 和 Firefox 90。
const axios = require('axios');
// Helper function to get a random item from an array
const sample = array => array[Math.floor(Math.random() * array.length)];
const headers = [
{
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9',
'Sec-Ch-Ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36',
},
{
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:90.0) Gecko/20100101 Firefox/90.0',
},
];
(async () => {
const { data } = await axios.get('https://httpbin.org/anything', { headers: sample(headers) });
console.log(data);
// { 'User-Agent': '...Chrome/92...', ... }
})();
用于动态 HTML 的无头浏览器
到目前为止,访问的每个页面都是使用 完成的axios.get,这在某些情况下可能是不够的。假设我们需要 JS 来加载和执行或与浏览器交互(通过鼠标或键盘)。
虽然出于性能原因,避免使用无头浏览器会更好——但有时别无选择。Selenium、Puppeteer和Playwright是 Javascript 和 NodeJS 世界中最常用和最知名的库。
下面的代码片段仅显示了用户代理。但由于它是一个真正的浏览器,标头将包括整个集合(Accept、Accept-Encoding 等)。
const playwright = require('playwright');
(async () => {
// 'webkit' is also supported, but there is a problem on Linux
for (const browserType of ['chromium', 'firefox']) {
const browser = await playwright[browserType].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://httpbin.org/headers');
console.log(await page.locator('pre').textContent());
await browser.close();
}
})();
// "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/94.0.4595.0 Safari/537.36",
// "User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0",
这种方法有其自身的问题:查看用户代理。Chromium 一个包括“HeadlessChrome”。它会告诉目标网页,嗯,它是一个无头浏览器。他们可能会据此采取行动。
与 Axios 一样,我们可以设置标头、代理和其他选项来自定义请求。隐藏我们的“HeadlessChrome”用户代理的绝佳选择。由于这是一个真正的网络浏览器,我们可以拦截请求、阻止其他内容(如 CSS 文件或图像)、截取屏幕截图或视频等等。网页抓取真的很方便!
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
proxy: { server: 'http://91.216.164.251:80' }, // Another free proxy from the list
});
const context = await browser.newContext();
const page = await context.newPage();
page.setExtraHTTPHeaders({ referrer: 'https://news.ycombinator.com/' });
await page.goto('http://httpbin.org/anything');
console.log(await page.locator('pre').textContent()); // Print the complete response
await browser.close();
})();
// "Referrer": "https://news.ycombinator.com/"
// "origin": "91.216.164.251"
现在我们可以在几个函数中分离获取 HTML,一个使用 Playwright,另一个使用 Axios。然后,我们需要一种方法来选择适合手头情况的方法。目前,它是硬编码的。
顺便说一句,使用 Axios 时,这个输出是相同的,但速度更快。
const playwright = require('playwright');
const axios = require('axios');
const cheerio = require('cheerio');
const getHtmlPlaywright = async url => {
const browser = await playwright.chromium.launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto(url);
const html = await page.content();
await browser.close();
return html;
};
const getHtmlAxios = async url => {
const { data } = await axios.get(url);
return data;
};
(async () => {
const html = await getHtmlPlaywright('https://scrapeme.live/shop/page/1/');
const $ = cheerio.load(html);
const content = extractContent($);
console.log('getHtmlPlaywright', content);
})();
(async () => {
const html = await getHtmlAxios('https://scrapeme.live/shop/page/1/');
const $ = cheerio.load(html);
const content = extractContent($);
console.log('getHtmlAxios', content);
})();
使用 Javascript 的 async 进行并行爬取
我们已经在顺序爬取多个链接时引入了 async/await。如果我们要并行爬取它们,删除await就足够了,对吧?嗯……没那么快。
该函数将调用第一个crawl并从集合中获取以下项目toVisit。问题是该集合为空,因为尚未抓取第一页。所以我们没有向列表添加新链接。该函数一直在后台运行,但我们已经退出了主函数。
为了正确地做到这一点,我们需要创建一个队列,该队列将在可用时执行任务。为了避免同时有很多请求,我们会限制它的并发数。
Javascript 和 NodeJS 都没有提供内置队列。对于大规模的网络抓取,您可以搜索做得更好的库。
const queue = (concurrency = 4) => {
let running = 0;
const tasks = [];
return {
enqueue: async (task, ...params) => {
tasks.push({ task, params }); // Add task to the list
if (running >= concurrency) {
return; // Do not run if we are above the concurrency limit
}
running += 1; // "Block" one concurrent task
while (tasks.length > 0) {
const { task, params } = tasks.shift(); // Take task from the list
await task(...params); // Execute task with the provided params
}
running -= 1; // Release a spot
},
};
};
// Just a helper function, JS has no sleep function
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
const printer = async num => {
await sleep(2000);
console.log(num, Date.now());
};
const q = queue();
// Add 8 tasks that will sleep and print a number
for (let num = 0; num < 8; num++) {
q.enqueue(printer, num);
}
运行上面的代码将几乎立即打印从 0 到 3 的数字(带有时间戳)。然后在 2 秒后从 4 到 7。这可能是最难理解的片段 – 不要着急复习。
我们queue在第 1-20 行定义。它将返回一个对象,该对象具有enqueue将任务添加到列表的功能。然后它检查我们是否超过并发限制。如果我们不是,它将求和running并进入一个循环,该循环获取一个任务并使用提供的参数运行它。直到任务列表为空,再减一running。这个变量是一个标记我们何时可以或不能执行更多任务的变量,只允许它低于并发限制。在第 23-28 行中,有辅助函数sleep和printer. 在第 30 行实例化队列并在第 32-34 行(将开始运行 4)将项目入队。
您刚刚在几行代码中使用 JS 创建了一个队列!
我们现在必须使用队列而不是 for 循环来同时运行多个页面。下面的代码是部分更改的部分。
const crawl = async url => {
// ...
links
.filter(link => !visited.has(link))
.forEach(link => {
q.enqueue(crawlTask, link); // Add to queue instead of to the list
});
};
// Helper function that will call crawl after some checks
const crawlTask = async url => {
if (visited.size >= maxVisits) {
console.log('Over Max Visits, exiting');
return;
}
if (visited.has(url)) {
return;
}
await crawl(url);
};
const q = queue();
// Add the first link to the process
q.enqueue(crawlTask, url);
请记住,Node.js 在单线程中运行。我们可以利用它的事件循环,但不能使用多个 CPU/线程。我们所看到的效果很好,因为线程大部分时间都处于空闲状态——网络请求不会消耗 CPU 时间。
为了进一步构建它,我们需要使用一些存储(数据库、CSV 或 JSON 文件)或分布式队列系统。现在,我们依赖于 Node.js 中线程之间不共享的变量。目前,显示抓取的数据足以进行演示。
它并不过分复杂,但我们在这篇博文中涵盖了足够多的内容。干得好,干得好!
最终代码
演示的所有代码都在同一个 js 文件中。考虑将其拆分为真实世界的用例。你也可以在Github上看到它。
const axios = require('axios');
const playwright = require('playwright');
const cheerio = require('cheerio');
const url = 'https://scrapeme.live/shop/page/1/';
const useHeadless = false; // "true" to use playwright
const maxVisits = 30; // Arbitrary number for the maximum of links visited
const visited = new Set();
const allProducts = [];
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
const getHtmlPlaywright = async url => {
const browser = await playwright.chromium.launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto(url);
const html = await page.content();
await browser.close();
return html;
};
const getHtmlAxios = async url => {
const { data } = await axios.get(url);
return data;
};
const getHtml = async url => {
return useHeadless ? await getHtmlPlaywright(url) : await getHtmlAxios(url);
};
const extractContent = $ =>
$('.product')
.map((_, product) => {
const $product = $(product);
return {
id: $product.find('a[data-product_id]').attr('data-product_id'),
title: $product.find('h2').text(),
price: $product.find('.price').text(),
};
})
.toArray();
const extractLinks = $ => [
...new Set(
$('.page-numbers a')
.map((_, a) => $(a).attr('href'))
.toArray()
),
];
const crawl = async url => {
visited.add(url);
console.log('Crawl: ', url);
const html = await getHtml(url);
const $ = cheerio.load(html);
const content = extractContent($);
const links = extractLinks($);
links
.filter(link => !visited.has(link))
.forEach(link => {
q.enqueue(crawlTask, link);
});
allProducts.push(...content);
// We can see how the list grows. Gotta catch 'em all!
console.log(allProducts.length);
};
// Change the default concurrency or pass it as a param
const queue = (concurrency = 4) => {
let running = 0;
const tasks = [];
return {
enqueue: async (task, ...params) => {
tasks.push({ task, params });
if (running >= concurrency) {
return;
}
++running;
while (tasks.length) {
const { task, params } = tasks.shift();
await task(...params);
}
--running;
},
};
};
const crawlTask = async url => {
if (visited.size >= maxVisits) {
console.log('Over Max Visits, exiting');
return;
}
if (visited.has(url)) {
return;
}
await crawl(url);
};
const q = queue();
q.enqueue(crawlTask, url);
结论
我们希望您分享四个要点:
- 了解网站解析、抓取以及如何提取数据的基础知识。
- 分离职责并在必要时使用抽象。
- 应用所需的技术来避免阻塞。
- 能够找出以下步骤来扩大规模。
我们可以使用我们已经看到的部分使用 Javascript 和 NodeJS 构建自定义网络抓取工具。它可能无法扩展到数千个网站,但对于少数几个网站来说已经足够了。转向分布式爬虫离这里并不远。然后是自动化。






