

如何使用Ruby语言实现网页抓取
近年来,公司和个人对数据抓取的需求不断增加,而 Ruby 是用于此目的的最佳编程语言之一。Ruby 中的 Web 抓取只是构建一个脚本,可以自动从 Web 检索数据,然后您可以随心所欲地使用提取的数据。
在这个循序渐进的教程中,您将学习如何使用 Nokogiri 和 Selenium 等库使用 Ruby 进行网页抓取。
准备工作
设置环境
以下是我们将在此数据抓取教程中使用的工具:
- Ruby 3+:任何大于或等于 3 的版本都可以。我们将使用 3.1.3,因为它是撰写本文时的最新版本。
- 一个支持 Ruby 的 IDE:带有Ruby Language for IntelliJ插件的IntelliJ IDEA是一个不错的选择。或者,如果您更喜欢免费选项,带有VSCode Ruby扩展的Visual Studio Code也可以。
如果您没有安装这些工具,请单击上面的链接并下载它们。使用官方指南安装它们,您将拥有遵循此网络抓取 Ruby 指南所需的一切。
安装后,您可以通过在终端中启动以下命令来验证 Ruby 是否正常工作:
ruby -v
它应该返回您机器上可用的 Ruby 版本,如下所示:
ruby 3.1.3p185 (2022-11-24 revision 1a6b16756e) [x64-mingw-ucrt]
初始化 Web Scraping Ruby 项目
为您的 Ruby 项目创建一个文件夹,然后使用以下命令进入该文件夹:
mkdir simple-web-scraper-ruby cd simple-web-scraper-ruby
现在,创建一个scraper.rb文件并将其初始化如下:
puts "Hello, World!"
在终端中,运行命令ruby scraper.rb以启动脚本。这应该打印:
"Hello, World!"
这意味着您的 Ruby 数据抓取脚本可以正常工作!
请注意,scraper.rb将包含刮板逻辑。在您的 Ruby IDE 中导入该simple-web-scraper-ruby文件夹,您现在已准备好将使用 Ruby 进行数据抓取的基础知识付诸实践!
如何使用 Ruby 抓取网站
让我们使用ScrapeMe作为我们的目标网站,我们将使用我们的 Ruby 蜘蛛访问每个页面并从中检索产品数据。目标网站仅包含在多个页面上分页的 Pokemon 启发元素列表。
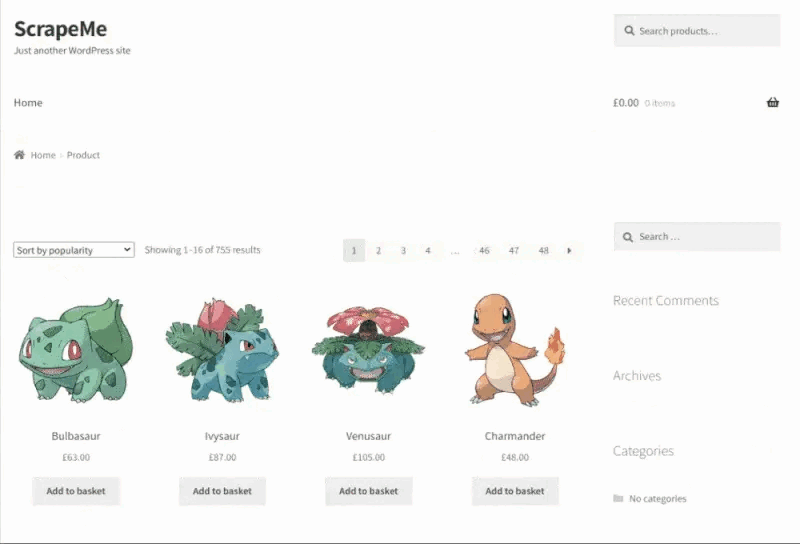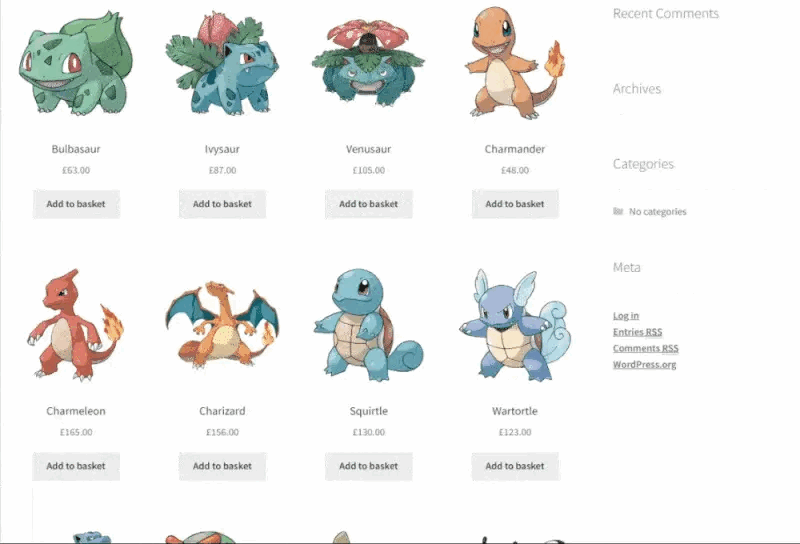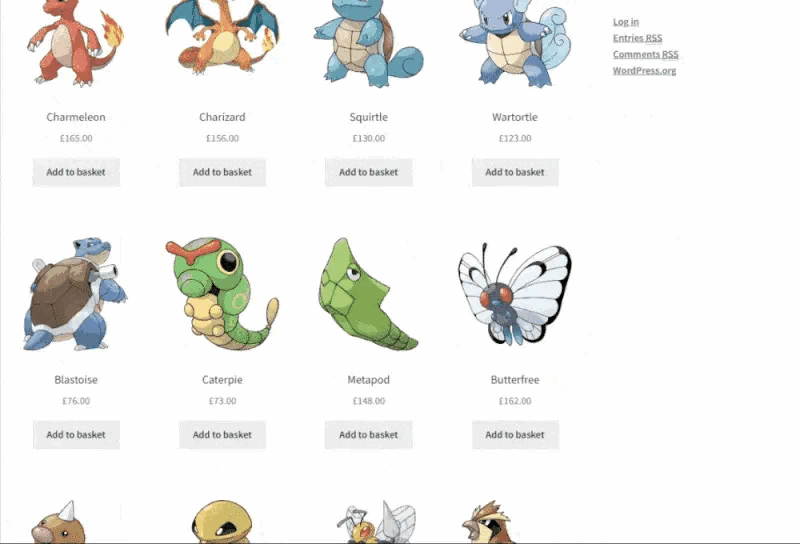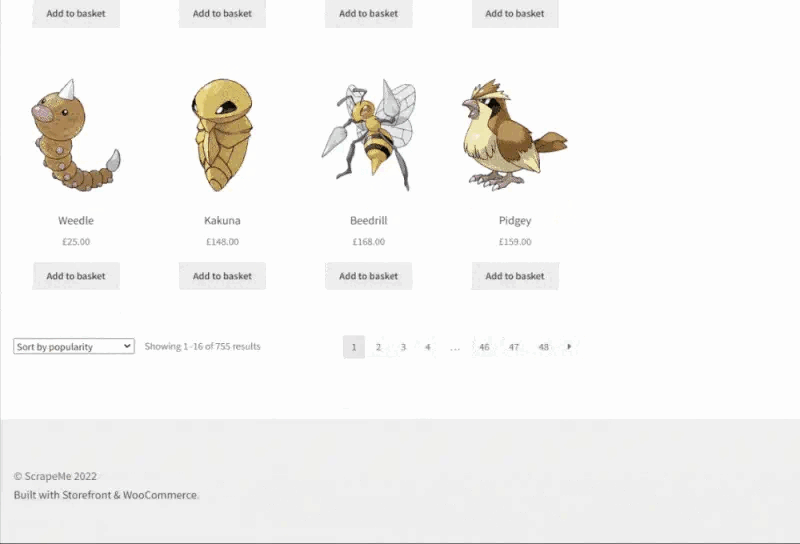
让我们安装一些 Ruby gem 并开始抓取。
第 1 步:安装 HTTParty 和 Nokogiry
Net::HTTP库是 Ruby 的标准 HTTP 客户端 API,您可以使用它来执行 HTTP 请求。但它没有提供最好的语法,可能不是初学者的最佳选择。因此,像HTTPParty这样对用户更友好的 HTTP 客户端是更好的选择。
HTTParty 是一个直观的 HTTP 客户端,它试图让 HTTP 变得有趣,考虑到这些请求在网络爬虫方面的重要性,HTTParty 将派上用场。
使用httparty gem安装 HTTParty :
gem install httparty
您现在可以执行 HTTP 请求来轻松检索 HTML 文档。你只需要一个 HTML 解析器!Nokogiri使在 Ruby 中处理 XML 和 HTML 文档变得容易。它提供了一个功能强大且易于使用的 API,可让您解析 HTML 页面、选择 HTML 元素,强大的 API 可让您解析 HTML 页面、选择 HTML 元素并提取其数据。
换句话说,Nokogiri 可以帮助您在 Ruby 中执行网络抓取。你可以通过nokogirigem 安装它:
gem install nokogiri
在文件顶部添加以下行scraper.rb:
require "httparty" require "nokogiri"
如果您的 Ruby IDE 没有报告错误,则说明您正确安装了这两个 gem。让我们继续看看如何使用 HTTParty 和 Nokogiri!
第 2 步:下载目标网页
使用 HTTParty 执行 HTTPGET请求以下载您要抓取的网页:
# downloading the target web page
response = HTTParty.get("https://scrapeme.live/shop/")
HTTPartyget()方法对作为参数传递的 URL 执行 GET 请求,并response.body包含服务器返回的 HTML 文档作为响应。
如果您在此阶段遇到错误,请不要翻转表格,因为错误是因为多个网站根据其标头阻止了 HTTP 请求。User-Agent具体来说,作为其反抓取技术的一部分,他们禁止没有有效标头的请求。您可以在 HTTParty 中设置一个,User-Agent如下所示:
response = HTTParty.get("https://scrapeme.live/shop/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
},
})
第 3 步:解析 HTML 文档
使用Nokogiri解析其中包含的HTML文档response.body
# parsing the HTML document returned by the server document = Nokogiri::HTML(response.body)
该Nokogiri:HTML()方法接受一个 HTML 字符串并返回一个 Nokogiri 文档,其中有许多方法可以让您访问所有 Nokogiri 网络抓取功能。让我们看看如何使用它们从目标网页中选择 HTML 元素。
第 4 步:确定最重要的 HTML 元素
为此,请右键单击产品 HTML 元素并选择“检查”选项以打开 DevTools 窗口:

在这里您可以注意到一个li.productHTML 元素包含:
a涉及产品 URL 的 HTML 元素。img包含产品图像的 HTML 元素。h2包装产品名称的 HTML 元素。span存储产品价格的 HTML 元素。
让我们使用 Ruby 从产品 HTML 元素中抓取数据。
第 5 步:从这些 HTML 元素中提取数据
您将需要一个 Ruby对象,您将首先在其中存储抓取的数据,您可以通过使用PokemonProductRuby 创建一个类来完成此操作Struct:
# defining a data structure to store the scraped data PokemonProduct = Struct.new(:url, :image, :name, :price)
AStruct允许您将多个属性捆绑在同一数据结构中,而无需从头开始编写新类。PokemonProduct有四个属性对应于从每个产品 HTML 元素中抓取的数据。现在继续检索所有li.productHTML 元素的列表,如下所示:
# selecting all HTML product elements
html_products = document.css("li.product")
感谢css()Nokogiri 公开的方法,您可以基于 CSS 选择器选择 HTML 元素。在这里,css()应用li.productCSS 选择器策略来检索所有产品 HTML 元素。
遍历 HTML 产品列表并从每个产品中提取感兴趣的数据,如下所示:
# initializing the list of objects
# that will contain the scraped data
pokemon_products = []
# iterating over the list of HTML products
html_products.each do |html_product|
# extracting the data of interest
# from the current product HTML element
url = html_product.css("a").first.attribute("href").value
image = html_product.css("img").first.attribute("src").value
name = html_product.css("h2").first.text
price = html_product.css("span").first.text
# storing the scraped data in a PokemonProduct object
pokemon_product = PokemonProduct.new(url, image, name, price)
# adding the PokemonProduct to the list of scraped objects
pokemon_products.push(pokemon_product)
end
您刚刚学习了如何在 Ruby 中执行数据抓取。上面的代码片段依赖于Nokogiri提供的 Ruby 网络抓取 API从每个产品 HTML 元素中抓取感兴趣的数据。然后它用这些数据创建一个PokemonProduct实例并将其存储在已抓取的产品列表中。
是时候将抓取的数据转换成更方便的格式了。
第 6 步:将抓取的数据转换为 CSV
您可以通过这种方式轻松地将抓取的数据提取到 Ruby 中的 CSV 文件中:
# defining the header row of the CSV file
csv_headers = ["url", "image", "name", "price"]
CSV.open("output.csv", "wb", write_headers: true, headers: csv_headers) do |csv|
# adding each pokemon_product as a new row
# to the output CSV file
pokemon_products.each do |pokemon_product|
csv << pokemon_product
end
end
注意:该CSV库是默认 gem 的一部分。因此,您无需额外的库即可在 Ruby 中处理 CSV 文件。此处的代码片段初始化一个output.csv带有标题行的文件,然后使用已抓取产品列表中包含的数据填充 CSV 文件
scraper.rb在您的 IDE 中或使用以下命令运行数据抓取 Ruby 脚本:
ruby scraper.rb
当脚本结束时,您会output.csv在 Ruby 项目的根文件夹中找到一个文件。打开它,你会看到如下数据:

干得好!您刚刚使用 Ruby 抓取了一个网页!
第 7 步:将它们放在一起
这就是整个 Ruby 数据抓取工具的样子:
require "httparty"
require "nokogiri"
# defining a data structure to store the scraped data
PokemonProduct = Struct.new(:url, :image, :name, :price)
# initializing the list of objects
# that will contain the scraped data
pokemon_products = []
# initializing the list of pages to scrape with the
# pagination URL associated with the first page
pages_to_scrape = ["https://scrapeme.live/shop/page/1/"]
# initializing the list of pages discovered
# with a copy of pages_to_scrape
pages_discovered = ["https://scrapeme.live/shop/page/1/"]
# current iteration
i = 0
# max pages to scrape
limit = 5
# iterate until there is still a page to scrape
# or the limit is reached
while pages_to_scrape.length != 0 && i < limit do
# getting the current page to scrape
# and removing it from the list
page_to_scrape = pages_to_scrape.pop
# retrieving the current page to scrape
response = HTTParty.get(page_to_scrape, {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
},
})
# parsing the HTML document returned by the server
document = Nokogiri::HTML(response.body)
# extracting the list of URLs from
# the pagination elements
new_pagination_links = document
.css("a.page-numbers")
.map{ |a| a.attribute("href") }
# iterating over the list of pagination links
new_pagination_links.each do |new_pagination_link|
# if the web page discovered is new and should be scraped
if !(pages_discovered.include? new_pagination_link) && !(pages_to_scrape.include? new_pagination_link)
pages_to_scrape.push(new_pagination_link)
end
# discovering new pages
pages_discovered.push(new_pagination_link)
end
# removing the duplicated elements
pages_discovered = pages_discovered.to_set.to_a
# selecting all HTML product elements
html_products = document.css("li.product")
# iterating over the list of HTML products
html_products.each do |html_product|
# extracting the data of interest
# from the current product HTML element
url = html_product.css("a").first.attribute("href").value
image = html_product.css("img").first.attribute("src").value
name = html_product.css("h2").first.text
price = html_product.css("span").first.text
# storing the scraped data in a PokemonProduct object
pokemon_product = PokemonProduct.new(url, image, name, price)
# adding the PokemonProduct to the list of scraped objects
pokemon_products.push(pokemon_product)
end
# incrementing the iteration counter
i = i + 1
end
# defining the header row of the CSV file
csv_headers = ["url", "image", "name", "price"]
CSV.open("output.csv", "wb", write_headers: true, headers: csv_headers) do |csv|
# adding each pokemon_product as a new row
# to the output CSV file
pokemon_products.each do |pokemon_product|
csv << pokemon_product
end
end
在不到 100 行代码中,您可以用 Ruby 构建一个网络抓取工具!
Ruby 中的高级 Web 抓取
您刚刚了解了使用 Ruby 进行网页抓取的基础知识。现在让我们更深入地研究最先进的方法。
Ruby 中的网络爬虫
由于目标网站涉及多个网页,所以我们进行网络爬虫,通过所有分页链接访问所有目标网站页面。为此,右键单击页码 HTML 元素并选择“检查”:
如果您是 Chrome 用户,您的 DevTools 窗口将如下所示:
选择页码 HTML 元素后的 DevTools 窗口
Chrome 会自动突出显示您右键单击的 HTML 元素。请注意,您可以使用 CSS 选择器选择所有分页元素a.page-numbers。继续使用 Nokogiri 提取所有分页链接:
# extracting the list of URLs from
# the pagination elements
pagination_links = document
.css("a.page-numbers")
.map{ |a| a.attribute("href") }
此代码段返回由每个分页 HTML 元素的属性提取的 URL 列表href。
要从网站上抓取所有页面,您需要编写一些抓取逻辑。您需要一些数据结构来跟踪访问过的页面并避免两次抓取一个页面,还需要一个limit变量来防止您的 Ruby 爬虫访问太多页面:
# initializing the list of pages to scrape with the
# pagination URL associated with the first page
pages_to_scrape = ["https://scrapeme.live/shop/page/1/"]
# initializing the list of pages discovered
# with a copy of pages_to_scrape
pages_discovered = ["https://scrapeme.live/shop/page/1/"]
# current iteration
i = 0
# max pages to scrape
limit = 5
# iterate until there is still a page to scrape
# or the limit is reached
while pages_to_scrape.length != 0 && i < limit do
# getting the current page to scrape
# and removing it from the list
page_to_scrape = pages_to_scrape.pop
# retrieving the current page to scrape
response = HTTParty.get(page_to_scrape, {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
},
})
# parsing the HTML document returned by server
document = Nokogiri::HTML(response.body)
# extracting the list of URLs from
# the pagination elements
new_pagination_links = document
.css("a.page-numbers")
.map{ |a| a.attribute("href") }
# iterating over the list of pagination links
new_pagination_links.each do |new_pagination_link|
# if the web page discovered is new and should be scraped
if !(pages_discovered.include? new_pagination_link) && !(pages_to_scrape.include? new_pagination_link)
pages_to_scrape.push(new_pagination_link)
end
# discovering new pages
pages_discovered.push(new_pagination_link)
end
# removing the duplicated elements
pages_discovered = pages_discovered.to_set.to_a
# scraping logic...
# incrementing the iteration counter
i = i + 1
end
# exporting to CSV...
这个 Ruby 数据抓取器分析网页,搜索新链接,将它们添加到抓取队列并从当前页面抓取数据。然后它为每个页面重复此逻辑。
如果设置limit为 48,脚本将访问整个网站并将pages_discovered存储所有 48 个分页 URL。因此,output.csv网站上将包含所有 755 款口袋妖怪产品的数据。
做得好!您刚刚学会了使用单个网页抓取 Ruby 脚本来抓取整个网站!
Ruby 中的并行 Web 抓取
使用 Ruby 进行 Web 抓取可能会成为一个漫长的过程,尤其是当 Web 服务器需要很长时间才能响应时。避免这种情况的最好方法是通过并行化!Ruby 中的并行网络抓取允许您同时抓取多个页面,从而显着提高性能。
首先,parallel在你的 Ruby 网络爬虫中安装:
gem install parallel
并通过将此行添加到您的 Ruby 文件来导入它:
require "parallel"
您现在可以访问多个实用函数以在 Ruby 中执行并行计算。
现在,您将要抓取的网页列表存储在一个数组中:
pages_to_scrape = [
"https://scrapeme.live/shop/page/1/",
"https://scrapeme.live/shop/page/2/",
# ...
"https://scrapeme.live/shop/page/48/"
]
下一步是用 Ruby 构建一个并行的网络抓取工具。为此,首先实例化 aMutex以实现一个信号量,用于协调多个并发线程对共享数据的访问。您将需要它,因为数组在 Ruby 中不是线程安全的。然后,使用Parallelmap()公开的方法一次在页面上运行并行网络抓取。in_threads
# initializing a semaphore
semaphore = Mutex.new
Parallel.map(pages_to_scrape, in_threads: 4) do |page_to_scrape|
# retrieving the current page to scrape
response = HTTParty.get(page_to_scrape, {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
},
})
# parsing the HTML document returned by server
document = Nokogiri::HTML(response.body)
# scraping logic...
# since arrays are not thread-safe in Ruby
semaphore.synchronize {
# adding the PokemonProduct to the list of scraped objects
pokemon_products.push(pokemon_product)
}
end
您现在知道如何使您的 Ruby 网络抓取脚本快如闪电!请注意,这只是一个简单的片段,但您可以在此处找到完整的并行 Ruby 蜘蛛:
require "httparty"
require "nokogiri"
require "parallel"
# defining a data structure to store the scraped data
PokemonProduct = Struct.new(:url, :image, :name, :price)
# initializing the list of objects
# that will contain the scraped data
pokemon_products = []
# initializing the list of pages to scrape
pages_to_scrape = [
"https://scrapeme.live/shop/page/2/",
"https://scrapeme.live/shop/page/3/",
"https://scrapeme.live/shop/page/4/",
"https://scrapeme.live/shop/page/5/",
"https://scrapeme.live/shop/page/6/",
# ...
"https://scrapeme.live/shop/page/48/"
]
# initializing a semaphore
semaphore = Mutex.new
Parallel.map(pages_to_scrape, in_threads: 4) do |page_to_scrape|
# retrieving the current page to scrape
response = HTTParty.get(page_to_scrape, {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
},
})
# parsing the HTML document returned by server
document = Nokogiri::HTML(response.body)
# selecting all HTML product elements
html_products = document.css("li.product")
# iterating over the list of HTML products
html_products.each do |html_product|
# extracting the data of interest
# from the current product HTML element
url = html_product.css("a").first.attribute("href").value
image = html_product.css("img").first.attribute("src").value
name = html_product.css("h2").first.text
price = html_product.css("span").first.text
# storing the scraped data in a PokemonProduct object
pokemon_product = PokemonProduct.new(url, image, name, price)
# since arrays are not thread-safe in Ruby
semaphore.synchronize {
# adding the PokemonProduct to the list of scraped objects
pokemon_products.push(pokemon_product)
}
end
end
# defining the header row of the CSV file
csv_headers = ["url", "image", "name", "price"]
CSV.open("output.csv", "wb", write_headers: true, headers: csv_headers) do |csv|
# adding each pokemon_product as a new row
# to the output CSV file
pokemon_products.each do |pokemon_product|
csv << pokemon_product
end
end
使用 Ruby 中的无头浏览器抓取动态内容网站
许多网站使用 JavaScript 通过AJAX执行 HTTP 请求以异步检索数据。然后他们可以使用这些数据相应地更新 DOM,同样,他们可以使用 JavaScript 动态地操作 DOM。
在这种情况下,服务器返回的 HTML 文档可能不包含所有感兴趣的数据。如果你想抓取动态内容网站,你需要一个可以运行 JavaScript 的工具,比如无头浏览器。
无头浏览器是一种使您能够在没有 GUI 的浏览器中加载网页的技术。提供无头浏览器功能的最可靠的 Ruby 库之一是Selenium 的 Ruby 绑定。
要使用它来抓取动态网页,请selenium-webdriver在 Ruby 中安装 Selenium gem:
gem install selenium-webdriver
安装 Selenium 后,运行下面的 Ruby scraper 从 ScrapeMe 中检索数据:
require "selenium-webdriver"
# defining a data structure to store the scraped data
PokemonProduct = Struct.new(:url, :image, :name, :price)
# initializing the list of objects
# that will contain the scraped data
pokemon_products = []
# configuring Chrome to run in headless mode
options = Selenium::WebDriver::Chrome::Options.new
options.add_argument("--headless")
# initializing the Selenium Web Driver for Chrome
driver = Selenium::WebDriver.for :chrome, options: options
# visiting a web page in the browser opened
# by Selenium behind the scene
driver.navigate.to "https://scrapeme.live/shop/"
# selecting all HTML product elements
html_products = driver.find_elements(:css, "li.product")
# iterating over the list of HTML products
html_products.each do |html_product|
# extracting the data of interest
# from the current product HTML element
url = html_product.find_element(:css, "a").attribute("href")
image = html_product.find_element(:css, "img").attribute("src")
name = html_product.find_element(:css, "h2").text
price = html_product.find_element(:css, "span").text
# storing the scraped data in a PokemonProduct object
pokemon_product = PokemonProduct.new(url, image, name, price)
# adding the PokemonProduct to the list of scraped objects
pokemon_products.push(pokemon_product)
end
# closing the driver
driver.quit
# exporting logic
Selenium 允许您使用 方法在 Ruby 中选择 HTML 元素find_elements()。当调用find_element()Selenium HTML 元素时,它会在其子元素中查找 HTML 节点。然后,使用attribute()和之类的方法text(),您可以从 HTML 节点中提取数据。
这种在 Ruby 中进行网络抓取的方法消除了对 HTTParty 和 Nokogiri 的需求,因为 Selenium 使用浏览器来执行请求GET并呈现生成的 HTML 文档。因此,您可以直接访问 Selenium 中的新网页:
# selecting a pagination element pagination_element = driver.find_element(:css, "a.page-numbers") # visiting to a new page # directy in the browser paginationElement.click # waiting for the web page to load... puts driver$title # prints "Products – Page 2 – ScrapeMe"
当您调用该click方法时,Selenium 将在无头浏览器中打开一个新页面,让您可以像人类用户一样在 Ruby 中进行网络爬虫。这使得在不被阻止的情况下执行网络抓取变得容易。
Ruby 中的其他 Web 抓取库
其他用于使用 Ruby 进行网络抓取的有用库是:
- ZenRows:一个网络抓取 API,可以轻松地从网页中提取数据并自动绕过任何反机器人或反抓取系统。ZenRows 还提供无头浏览器、旋转代理和 99% 的正常运行时间保证。
- OpenURI:一个 Ruby gem,它包装了
Net::HTTP库以使其更易于使用。使用 OpenURI,您可以轻松地在 Ruby 中执行 HTTP 请求。 - Kimurai:一个开源的现代数据抓取 Ruby 框架,可与无头浏览器(如 Chromium、无头 Firefox 和 PhantomJS)配合使用,让您与需要 JavaScript 的网站进行交互。它还支持对静态内容网站的简单 HTTP 请求。
- Watir:一个用于执行自动化测试的开源 Ruby 库。Watir 允许您指示浏览器并提供无头浏览器功能。
- Capybara:一个高级 Ruby 库,用于为 Web 应用程序构建测试。Capybara 与网络驱动程序无关,支持 Rack::Test 和 Selenium。
结论
这个循序渐进的教程讨论了开始使用 Ruby 网络抓取所需了解的基本知识。
回顾一下,您了解到:
- 如何使用 Nokogiri 在 Ruby 中进行基本的网页抓取。
- 如何定义网络爬虫逻辑来爬取整个网站。
- 为什么您可能需要 Ruby 无头浏览器库。
- 如何使用 Selenium 的 Ruby 绑定来抓取和抓取动态内容网站。
使用 Ruby 抓取 Web 数据可能会很麻烦,因为有许多网站都采用了反抓取技术,绕过它们可能具有挑战性。避免这些麻烦的最好方法是使用 Ruby 网络抓取 API,例如ZenRows。它能够通过单个 API 调用来处理反机器人绕过。
您可以免费开始使用并试用 ZenRows 的抓取功能,例如旋转代理和无头浏览器。
常见问题
你如何使用 Ruby 从网站上抓取数据?
就像使用任何其他编程语言一样,您可以使用 Ruby 从网站上抓取数据。如果您采用一个或多个 Ruby 网络抓取库,这将变得更容易。使用它们连接到您的目标网站,从其页面中选择 HTML 元素并从中提取数据。
你能用 Ruby 抓取吗?
是的你可以!Ruby 是一种通用编程语言,拥有数量惊人的库。有几个 Ruby gem 可以支持您的网络抓取项目,例如httparty、nokogiri、open-uri、selenium-webdriver和。watircapybara
Ruby 中最流行的网络抓取库是什么?
Nokogiri 是 Ruby 中最受欢迎的网络抓取库。它是一个 gem,可让您轻松解析 HTML 和 XML 文档并从中提取数据。Nokogiri 通常与 HTTP 客户端一起使用,例如 OpenURI 或 HTTParty。






