

如何使用Java进行网页数据抓取
在此 Java 网络抓取教程中,您将学习有关 Java 网络抓取的所有知识。按照这个循序渐进的教程,您将成为网络抓取专家。详细地,您将学习如何掌握网络抓取的基础知识以及最高级的方面。
我们不要再浪费时间了!了解如何使用 Java 构建网络抓取工具。该脚本将能够抓取整个网站并自动从中提取数据。很酷,不是吗?
你能用 Java 抓取网页吗?
简短的回答是“是的,你可以! ”
Java 是可用的最可靠的面向对象编程语言之一。因此,Java 可以依赖范围广泛的库。这意味着您可以从多个 Java 网络抓取库中进行选择。
两个例子是 Jsoup 和 Selenium。这些库允许您连接到网页。此外,它们还具有许多功能来帮助您提取您感兴趣的数据。在这个 Java 网络抓取教程中,您将学习如何使用这两者。
你如何在 Java 中抓取页面?
您可以使用 Java 抓取网页,就像您可以使用任何其他编程语言执行网页抓取一样。您需要一个 Web 抓取 Java 库,它允许您访问网页、检索 HTML 元素并从中提取数据。
您可以使用Maven或Gradle轻松安装 Java 网络抓取库。有两种最流行的 Java 依赖工具。遵循此网络抓取 Java 教程,了解有关如何使用 Java 进行网络抓取的更多信息。
准备工作
在开始构建您的 Java 网络爬虫之前,您需要满足以下要求:
- Java LTS 8+:任何大于或等于 8 的 Java LTS(长期支持)版本都可以。详细来说,这个 Java 网页抓取教程指的是 Java 17。在撰写本文时,这是 Java 的最后一个 LTS 版本。
- Gradle或Maven:选择两个构建自动化工具之一。您将需要其中之一的依赖管理功能来安装您的 Java 网络抓取库。
- Java IDE:任何支持 Java 并可以与 Maven 和 Gradle 集成的 IDE 都可以。IntelliJ IDEA是可用的最佳选择之一。
如果您不满足这些先决条件,请点击上面的链接。按顺序下载并安装 Java、Gradle 和 Maven,以及 Java IDE。如果遇到问题,请按照官方安装指南进行操作。然后,您可以使用以下终端命令验证一切是否按预期进行:
java -version
这应该返回如下内容:
java version "17.0.5" 2022-10-18 LTS Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191) Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)
如您所见,它表示与您机器上安装的 Java 版本相关的信息。
然后,如果您是 Gradle 用户,请在您的终端中输入:
gradle -v
同样,这将返回您安装的 Gradle 版本,如下所示:
------------------------------------------------------------ Gradle 7.5.1 ------------------------------------------------------------ Build time: 2022-08-05 21:17:56 UTC Revision: d1daa0cbf1a0103000b71484e1dbfe096e095918 Kotlin: 1.6.21 Groovy: 3.0.10 Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021 JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191) OS: Windows 11 10.0 amd64
或者,如果您是 Maven 用户,请启动以下命令:
mvn -v
如果 Maven 安装过程按预期工作,这应该返回如下内容:
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
您已准备好按照这个循序渐进的 Web 抓取 Java 教程进行操作。详细地说,您将学习如何在https://scrapeme.live/shop/. 这是一个专门为抓取而设计的网站。
请注意,这scrapeme.live/shop/只是一个简单的 Pokemon 启发产品分页列表。Java 网络抓取工具的目标是抓取整个网站并检索所有产品数据。
您可以在支持本教程的 GitHub 存储库中找到网络抓取 java 源代码。使用以下命令克隆它并在阅读教程时查看代码:
git clone https://github.com/Tonel/simple-web-scraper-java
现在,按照这个使用 Java 进行网络抓取的教程学习如何用 Java 构建一个简单的网络抓取器!
设置 Java 项目
如果您是 IntelliJ IDEA 用户,您可以通过两个简单的步骤设置一个 Java 网络抓取项目。首先,打开 IntelliJ IDEA 并单击“文件 > 新建 > 项目…”菜单选项。
其次,在“新建项目”弹出窗口中配置您的 Java 项目,如下所示:
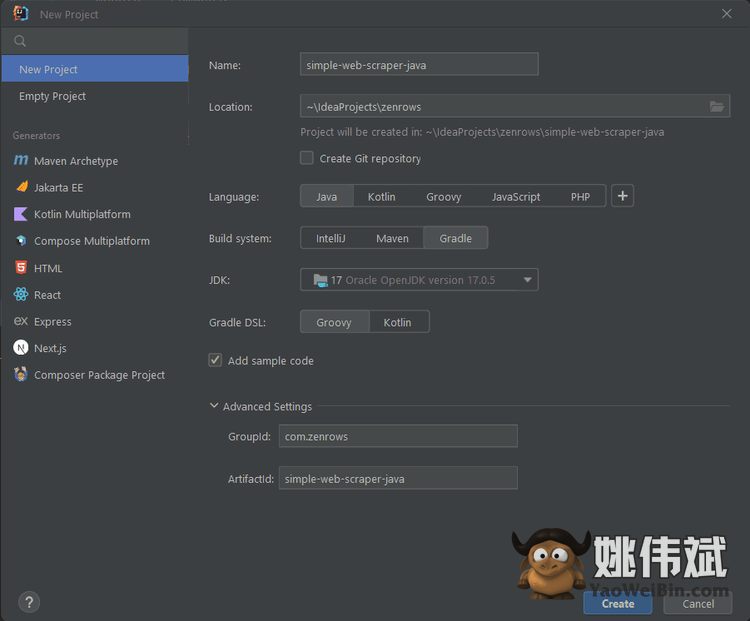
根据您安装或想要使用的构建自动化工具选择 Maven 或 Gradle 。然后,单击“创建”以初始化您的 Java 项目。等待设置过程结束,您现在应该可以访问以下 Java 网络抓取项目:
现在让我们学习使用 Java 进行网页抓取的基础知识!
Java 中的基本 Web 抓取
您需要学习的第一件事是如何使用 Java 抓取静态网站。您可以将静态网站视为预先构建的 HTML 文档的集合。这些 HTML 页面中的每一个都有其 CSS 和 JavaScript 文件。静态网站依赖于服务器端渲染。
在静态网页中,内容嵌入在服务器提供的 HTML 文档中。因此,您不需要 Web 浏览器即可从中提取数据。详细来说,静态网页抓取是关于:
- 下载网页
- 解析从服务器检索到的 HTML 文档。
- 从网页中选择包含感兴趣数据的 HTML 元素。
- 从中提取数据
在 Java 中,抓取网页并不困难。特别是涉及到静态网页抓取时。现在让我们学习使用 Java 进行网页抓取的基础知识。
步骤#1:安装 Jsoup
首先,您需要一个网络抓取 Java 库。Jsoup是一个 Java 库,可以使网络抓取变得容易。详细来说,Jsoup 带有一个高级的 Java 网络抓取 API。这允许您使用 URL 连接到网页,使用 CSS 选择器选择 HTML 元素,并从中提取数据。
换句话说,Jsoup 几乎为您提供了使用 Java 执行静态网页抓取所需的一切。如果您是 Gradle 用户,请将以下内容添加jsoup到dependencies您的build.gradle文件部分:
implementation "org.jsoup:jsoup:1.15.3"
否则,如果您是 Maven 用户,请在您的pom.xml文件中添加以下行:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
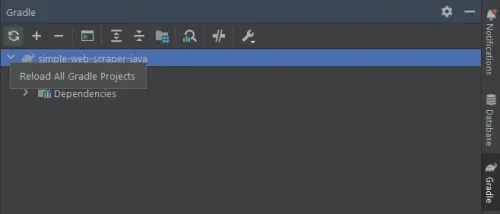
然后,如果您是 IntelliJ 用户,请不要忘记点击下面的 Gradle/Maven 重新加载按钮来安装新的依赖项:
Jsoup 现已安装并可以使用。将其导入到您的Main.java文件中,如下所示:
import org.jsoup.*; import org.jsoup.nodes.*; import org.jsoup.select.*;
第 2 步:连接到您的目标网站
您可以使用 Jsoup通过以下几行的URL 连接到网站:
// initializing the HTML Document page variable
Document doc;
try {
// fetching the target website
doc = Jsoup.connect("https://scrapeme.live/shop").get();
} catch (IOException e) {
throw new RuntimeException(e);
}
此代码段使用connect()Jsoup 中的方法连接到目标网站。请注意,如果连接失败,Jsoup 会抛出一个IOException. 这就是为什么你需要try … catch逻辑。然后,该方法返回一个 Jsoup HTML对象,您可以使用它来探索 DOM。get()Document
请记住,许多网站会自动阻止没有一组预期 HTTP 标头的请求。这是一种最基本的防刮系统。因此,您可以简单地通过手动设置这些 HTTP 标头来避免被阻止。
通常,您应该始终设置的最重要的标头是header。这是一个字符串,可帮助服务器识别HTTP 请求来自的应用程序、操作系统和供应商。User-Agent
您可以在 Jsoup 中设置User-Agent标头和其他 HTTP 标头,如下所示:
Document doc = Jsoup
.connect("https://scrapeme.live/shop")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36")
.header("Accept-Language", "*")
.get();
步骤 #3:选择感兴趣的 HTML 元素
在浏览器中打开目标网页并识别感兴趣的 HTML 元素。在这种情况下,您想要抓取所有产品 HTML 元素。右键单击产品 HTML 元素,然后选择“检查”选项。这应该打开下面的 DevTools 窗口:
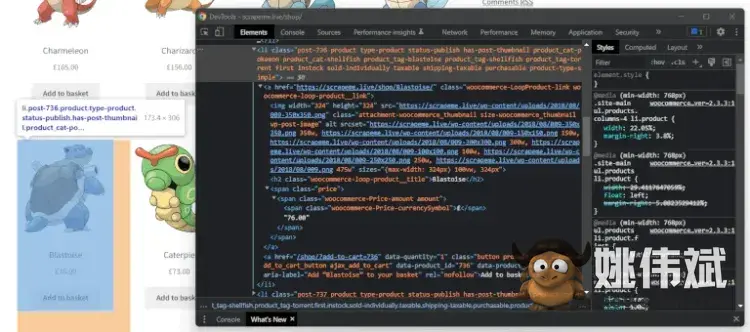
选择产品 HTML 元素后的 DevTools 窗口
如您所见,产品是li.productHTML 元素。这包括:
- 一个
aHTML 元素:包含与产品关联的 URL imgHTML 元素:包含产品图像。h2HTML 元素:包含产品名称。- 一个
spanHTML 元素:包含产品价格。
现在,让我们学习如何使用 Java 中的网络抓取从产品 HTML 元素中提取数据。
步骤 #4:从 HTML 元素中提取数据
首先,您需要一个 Java 对象来存储抓取的数据。data在主包中创建一个文件夹,定义一个PokemonProduct.java类如下:
package com.zenrows.data;
public class PokemonProduct {
private String url;
private String image;
private String name;
private String price;
// getters and setters omitted for brevity...
@Override
public String toString() {
return "{ "url":"" + url + "", "
+ " "image": "" + image + "", "
+ ""name":"" + name + "", "
+ ""price": "" + price + "" }";
}
}
请注意,该toString()方法会生成一个 JSON 格式的字符串。这将在以后派上用场。
现在,让我们检索目标网页上的 HTML 产品列表li.product。您可以使用 Jsoup 实现此目的,如下所示:
Elements products = doc.select("li.product");
这个片段的作用很简单。Jsoup函数应用CSS 选择器策略来检索网页上的所有内容。在细节上,扩展了一个. 因此,您可以轻松地对其进行迭代。select()li.productElementsArrayList
因此,您可以迭代products以提取感兴趣的信息并将其存储在PokemonProduct对象中:
// initializing the list of Java object to store
// the scraped data
List<PokemonProduct> pokemonProducts = new ArrayList<>();
// retrieving the list of product HTML elements
Elements products = doc.select("li.product");
// iterating over the list of HTML products
for (Element product : products) {
PokemonProduct pokemonProduct = new PokemonProduct();
// extracting the data of interest from the product HTML element
// and storing it in pokemonProduct
pokemonProduct.setUrl(product.selectFirst("a").attr("href"));
pokemonProduct.setImage(product.selectFirst("img").attr("src"));
pokemonProduct.setName(product.selectFirst("h2").text());
pokemonProduct.setPrice(product.selectFirst("span").text());
// adding pokemonProduct to the list of the scraped products
pokemonProducts.add(pokemonProduct);
}
此逻辑使用Jsoup 提供的 Java 网络抓取 API 从每个产品 HTML 元素中提取所有感兴趣的数据。然后,它使用此数据初始化 aPokemonProduct并将其添加到已抓取的产品列表中。
恭喜!您刚刚学习了如何使用 Jsoup 从网页中抓取数据。现在让我们将这些数据转换成更有用的格式。
第 5 步:将数据导出到 JSON
不要忘记 的方法toString()返回PokemonProduct一个 JSON 字符串。因此,只需调用toString()该List<PokemonProduct>对象:
pokemonProducts.toString()
toString()on anArrayList调用toString()列表中每个元素的方法。然后,它将结果嵌入方括号中。
换句话说,这将产生以下 JSON 数据:
[
{
"url": "https://scrapeme.live/shop/Bulbasaur/",
"image": "https://scrapeme.live/wp-content/uploads/2018/08/001-350x350.png",
"name": "Bulbasaur",
"price": "£63.00"
},
// ...
{
"url": "https://scrapeme.live/shop/Pidgey/",
"image": "https://scrapeme.live/wp-content/uploads/2018/08/016-350x350.png",
"name": "Pidgey",
"price": "£159.00"
}
]
您刚刚使用 Java 执行了网络抓取!然而,该网站由多个网页组成。让我们看看如何将它们全部抓取。
Java 中的网络爬虫
现在让我们检索所有分页链接的列表以抓取整个网站。这就是网络爬虫的意义所在。右键单击页码 HTML 元素并选择“检查”选项。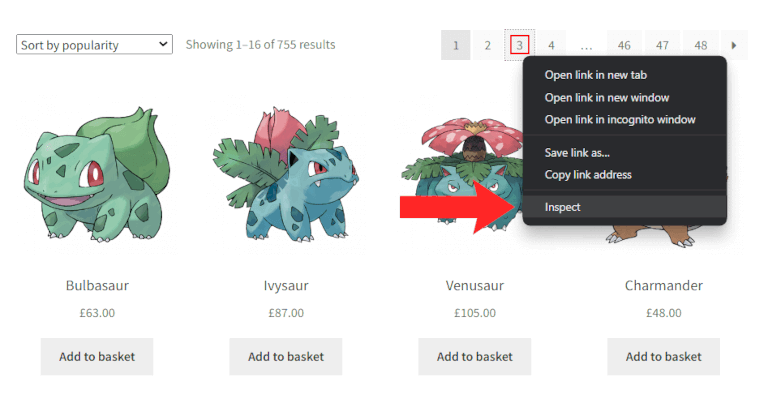
浏览器应打开DevTools 部分并突出显示所选的 DOM 元素,如下所示:

请注意,从这里您可以使用 CSS 选择器提取所有页码 HTML 元素a.page-numbers。这些元素包含您要抓取的链接。您可以使用 Jsoup 检索它们,如下所示:
Elements paginationElements = doc.select("a.page-numbers");
如果要抓取所有网页,则必须实现一些抓取逻辑。此外,您需要依赖一些列表和集合来避免两次抓取网页。您可以实现网络爬虫逻辑来访问有限数量的网页,如下limit所示:
package com.zenrows;
import com.zenrows.data.PokemonProduct;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
public class Main {
public static void scrapeProductPage(
List<PokemonProduct> pokemonProducts,
Set<String> pagesDiscovered,
List<String> pagesToScrape
) {
// the current web page is about to be scraped and
// should no longer be part of the scraping queue
String url = pagesToScrape.remove(0);
pagesDiscovered.add(url);
// scraping logic omitted for brevity...
// iterating over the pagination HTML elements
for (Element pageElement : paginationElements) {
// the new link discovered
String pageUrl = pageElement.attr("href");
// if the web page discovered is new and should be scraped
if (!pagesDiscovered.contains(pageUrl) && !pagesToScrape.contains(pageUrl)) {
pagesToScrape.add(pageUrl);
}
// adding the link just discovered
// to the set of pages discovered so far
pagesDiscovered.add(pageUrl);
}
}
public static void main(String[] args) {
// initializing the list of Java object to store
// the scraped data
List<PokemonProduct> pokemonProducts = new ArrayList<>();
// initializing the set of web page urls
// discovered while crawling the target website
Set<String> pagesDiscovered = new HashSet<>();
// initializing the queue of urls to scrape
List<String> pagesToScrape = new ArrayList<>();
// initializing the scraping queue with the
// first pagination page
pagesToScrape.add("https://scrapeme.live/shop/page/1/");
// the number of iteration executed
int i = 0;
// to limit the number to scrape to 5
int limit = 5;
while (!pagesToScrape.isEmpty() && i < limit) {
scrapeProductPage(pokemonProducts, pagesDiscovered, pagesToScrape);
// incrementing the iteration number
i++;
}
System.out.println(pokemonProducts.size());
// writing the scraped data to a db or export it to a file...
}
}
scrapeProductPage()抓取网页,发现要抓取的新链接,并将其 URL 添加到抓取队列中。如果你增加到limit48,在循环结束时while,pagesToScrape将是空的并且pagesDiscovered将包含所有 48 个分页 URL。
如果您是 IntelliJ IDEA 用户,请单击运行图标以运行 Web 抓取 Java 示例。等待进程结束。这将需要几秒钟。在该过程结束时,pokemonProducts将包含所有 755 个口袋妖怪产品。
Java 中的并行 Web 抓取
Java 中的 Web 抓取可能会成为一个耗时的过程。如果您的目标网站包含许多网页和/或服务器需要时间响应,则尤其如此。此外,Java 作为一种高性能编程语言并不受欢迎。
同时,Java 8 引入了很多特性,让并行变得更容易。因此,将您的 Java 网络抓取工具转换为并行工作只需要几次更新。让我们看看如何在 Java 中执行并行网络抓取:
package com.zenrows;
import com.zenrows.data.PokemonProduct;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Main {
public static void scrapeProductPage(
List<PokemonProduct> pokemonProducts,
Set<String> pagesDiscovered,
List<String> pagesToScrape
) {
// omitted for brevity...
}
public static void main(String[] args) throws InterruptedException {
// initializing the list of Java object to store
// the scraped data
List<PokemonProduct> pokemonProducts = Collections.synchronizedList(new ArrayList<>());
// initializing the set of web page urls
// discovered while crawling the target website
Set<String> pagesDiscovered = Collections.synchronizedSet(new HashSet<>());
// initializing the queue of urls to scrape
List<String> pagesToScrape = Collections.synchronizedList(new ArrayList<>());
// initializing the scraping queue with the
// first pagination page
pagesToScrape.add("https://scrapeme.live/shop/page/1/");
// initializing the ExecutorService to run the
// web scraping process in parallel on 4 pages at a time
ExecutorService executorService = Executors.newFixedThreadPool(4);
// launching the web scraping process to discover some
// urls and take advantage of the parallelization process
scrapeProductPage(pokemonProducts, pagesDiscovered, pagesToScrape);
// the number of iteration executed
int i = 1;
// to limit the number to scrape to 5
int limit = 10;
while (!pagesToScrape.isEmpty() && i < limit) {
// registering the web scraping task
executorService.execute(() -> scrapeProductPage(pokemonProducts, pagesDiscovered, pagesToScrape));
// adding a 200ms delay to avoid overloading the server
TimeUnit.MILLISECONDS.sleep(200);
// incrementing the iteration number
i++;
}
// waiting up to 300 seconds for all pending tasks to end
executorService.shutdown();
executorService.awaitTermination(300, TimeUnit.SECONDS);
System.out.println(pokemonProducts.size());
}
}
请记住,ArrayList和HashSet在 Java 中不是线程安全的。这就是为什么您需要分别用和包装您的集合。这些方法会将它们变成线程安全的集合,然后您可以在线程中使用它们。Collections.synchronizedList()Collections.synchronizedSet()
然后,您可以使用异步运行任务。多亏了,您可以毫不费力地执行和管理并行任务。具体来说,允许您初始化一个可以同时运行与传递给初始化方法的线程数一样多的线程。ExecutorServicesExecutorServicesnewFixedThreadPool()Executor
您不想使目标服务器或本地计算机超载。这就是为什么您需要在线程之间添加几毫秒的超时时间sleep()。您的目标是执行网络抓取,而不是 DOS 攻击。
然后,永远记得关闭你的ExecutorService并释放它的资源。由于当代码存在时,while循环某些任务可能仍在运行,因此您应该使用该awaitTermination()方法。
您必须在关闭请求后调用此方法。详细地说,awaitTermination()阻塞代码并等待所有任务在作为参数传递的时间间隔内完成。
运行此 java 网络抓取示例脚本,与之前相比,您将体验到性能的显着提高。您刚刚学习了如何使用 Java 执行即时网络抓取。
做得好!您现在知道如何使用 Java 进行并行网络抓取了!但仍有一些教训需要学习!
用 Java 抓取动态内容网站
不要忘记网页不仅仅是其相应的 HTML 文档。网页可以通过AJAX在浏览器中执行 HTTP 请求。这种机制允许网页异步检索数据并相应地更新显示给用户的内容。
大多数网站现在都依赖前端 API 请求来检索数据。这些请求是 AJAX 调用。因此,这些 API 调用提供了您在网络抓取时不能忽视的宝贵数据。您可以嗅探这些调用,将它们复制到您的抓取脚本中,然后检索这些数据。
要嗅探 AJAX 调用,请使用浏览器的 DevTools。右键单击网页,选择“检查”,然后选择“网络”选项卡。在“Fetch/XHR”选项卡中,您会找到网页执行的 AJAX 调用列表,如下所示。
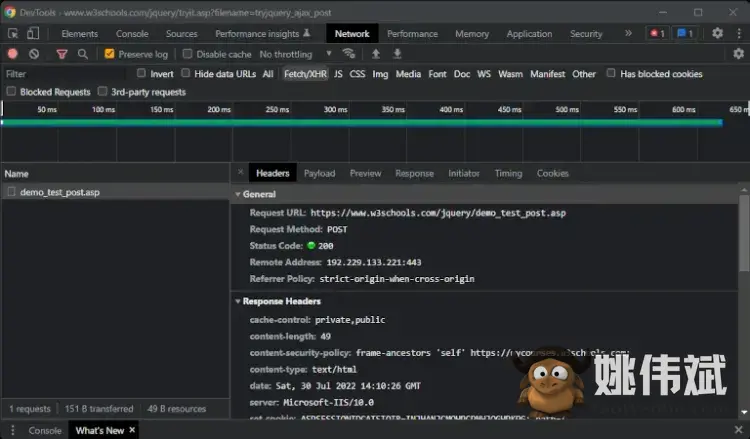
在这里,您可以检索在网络抓取脚本中复制这些调用所需的所有信息。然而,这并不是最好的方法。
使用无头浏览器进行网页抓取
网页执行大部分 AJAX 调用以响应用户交互。这就是为什么您需要一种工具来在浏览器中加载网页并复制用户交互的原因。这就是无头浏览器的意义 所在。
由于无头,您可以像人类一样通过 JavaScript 与网页交互。提供无头浏览器功能的 Java 中最受欢迎的库之一是Selenium WebDriver。
请注意,ZenRows API 带有无头浏览器功能。详细了解如何提取动态加载的数据。
如果您使用 Gradle,请在您的文件部分添加selenium-java以下行:dependenciesbuild.gradle
implementation "org.seleniumhq.selenium:selenium-java:4.6.0"
否则,如果您使用 Maven,请在您的文件中插入以下行pom.xml:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.6.0</version>
</dependency>
确保通过从终端或 IDE 中运行更新命令来安装新的依赖项。然后,您需要下载并安装驱动程序来控制您的浏览器。否则,您可以使用WebDriverManager库。这会自动管理 Selenium 所需的驱动程序。您现在已准备好开始使用 Selenium。
您可以使用以下脚本在单个页面上复制上面看到的网络抓取逻辑:
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.WebDriverWait;
import com.zenrows.data.PokemonProduct;
public class Main {
public static void main(String[] args) {
// setting the system property for the Chrome Driver
System.setProperty("webdriver.chrome.driver", "<COMPLETE_PATH_TO_YOUR_DRIVER>");
// defining the options to run Chrome in headless mode
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
// initializing a Selenium WebDriver ChromeDriver instance
// to run Chrome in headless mode
WebDriver driver = new ChromeDriver(options);
// connecting to the target web page
driver.get("https://scrapeme.live/shop/");
// initializing the list of Java object to store
// the scraped data
List<PokemonProduct> pokemonProducts = new ArrayList<>();
// retrieving the list of product HTML elements
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
// iterating over the list of HTML products
for (WebElement product : products) {
PokemonProduct pokemonProduct = new PokemonProduct();
// extracting the data of interest from the product HTML element
// and storing it in pokemonProduct
pokemonProduct.setUrl(product.findElement("a").getAttribute("href"));
pokemonProduct.setImage(product.findElement("img").getAttribute("src"));
pokemonProduct.setName(product.findElement("h2").getText());
pokemonProduct.setPrice(product.findElement("span").getText());
// adding pokemonProduct to the list of the scraped products
pokemonProducts.add(pokemonProduct);
}
// ...
}
}
如您所见,网络抓取逻辑与之前看到的并没有什么不同。真正改变的是 Selenium 在浏览器中运行网络抓取逻辑。这意味着Selenium 可以访问浏览器提供的所有功能。
例如,您可以单击分页元素直接导航到新页面,如下所示:
WebElement paginationElement = driver.findElement(By.cssSelector("a.page-numbers");
// navigating to a new web page
paginationElement.click();
// wait for the page to load...
System.out.println(driver.getTitle()); // "Products – Page 2 – ScrapeMe"
换句话说,Selenium 允许您通过与网页中的元素交互来执行网络爬行。就像人类一样。这使得基于无头浏览器的网络抓取工具更难检测和阻止。详细了解如何在不被阻止的情况下执行网络抓取。
其他 Java 网页抓取库
其他用于网络抓取的有用 Java 库是:
- HtmlUnit:用于 Java 的无 GUI/无头浏览器。HtmlUnit 可以在网页上执行所有特定于浏览器的操作。和 Selenium 一样,它是为测试而生的,但你可以用它来进行网络抓取和抓取。
- Playwright:Microsoft 开发的用于 Web 应用程序的端到端测试库。同样,它使您能够控制浏览器。因此,您可以像 Selenium 一样将其用于网络抓取。
结论
在此 Web 抓取 Java 教程中,您学习了有关使用 Java 执行专业 Web 抓取的所有知识。详细地,你看到了:
- 为什么 Java 在网络抓取方面是一种很好的编程语言
- 如何使用 Jsoup 在 Java 中执行基本的网页抓取
- 如何用Java爬取整个网站
- 为什么您可能需要无头浏览器
- 如何使用 Selenium 在动态内容网站上执行 Java 抓取
你永远不应该忘记的是,你的网络抓取工具需要能够绕过反抓取系统。这就是为什么您需要一个完整的网络抓取 Java API。






