

如何使用C#进行网页数据抓取
现在越来越多的公司利用从网络中提取的数据,而最适合此目的的编程语言之一是 C#。在本分步教程中,您将了解如何使用 Selenium 和 Html Agility Pack 等库在 C# 中执行网页抓取。
设置环境
以下是遵循此 C# 抓取指南需要满足的先决条件:
- .NET 7+:最新版本的 .NET SDK 即可。在撰写本文时,这是 7.0.102。
- 用于 C# 编码的 IDE:Visual Studio 2022 Community Edition是一个完整的解决方案。如果您更喜欢更轻便的选项,带有C#扩展的Visual Studio Code是完美的选择。
为了节省时间,您可以直接安装.NET Coding Pack。它包括带有基本 .NET 扩展和 .NET SDK 的 Visual Studio Code。否则,请按照上面的链接下载所需的工具。
您现在应该已经准备好按照我们的网络抓取 C# 教程进行操作了。
但是,让我们首先验证您是否正确安装了 .NET。启动 PowerShell 窗口,然后运行以下命令。
dotnet --list-sdks
这应该会打印出您机器上安装的 .NET SDK 的版本。
7.0.101 [C:Program Filesdotnetsdk]
如果您收到'dotnet' is not recognized as an internal or external command error,则说明出了问题。重新启动机器并重试。如果上面的命令返回相同的错误,您将需要重新安装 .NET。
初始化 C# 项目
让我们在 Visual Studio Code 中创建一个 .NET 控制台应用程序。如有问题,请查阅官方指南。
首先,为您的 C# 项目创建一个名为的空文件夹SimpleWebScraper。
mkdir SimpleWebScraper
现在,启动 Visual Studio Code 并从顶部菜单中选择“文件 > 打开文件夹…”。

选择SimpleWebScraper并等待 Visual Studio Code 打开文件夹。然后,通过从主菜单中选择“查看 > 终端”来打开终端窗口。

在 Visual Studio Code 终端中,启动以下命令:
dotnet new console --framework net7.0
这将初始化一个 .NET 7.0 控制台项目。具体来说,它将创建一个.csproj项目文件和一个Program.csC# 文件。
现在,将 的内容替换Program.cs为下面的代码。
namespace SimpleWebScraper
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello, World!");
// scraping logic...
}
}
}
这是一个简单的控制台脚本在 C# 中的样子。请注意,该Main()函数将包含 C# 数据抓取逻辑。
通过启动您接下来看到的命令来运行脚本:
dotnet run
应该打印:
"Hello, World!"
太好了,您的初始 C# 脚本按预期工作!
您将学习使用 C# 进行网络抓取的基础知识。
如何在 C# 中抓取网站
我们将学习如何通过从ScrapeMe中提取数据来使用 C# 构建数据抓取器,ScrapeMe 是一个展示分布在多个页面上的 Pokemon 启发元素列表的网站。C# 蜘蛛将自动访问并从其中的每一个中提取产品数据。
这就是 ScrapeMe 的样子:
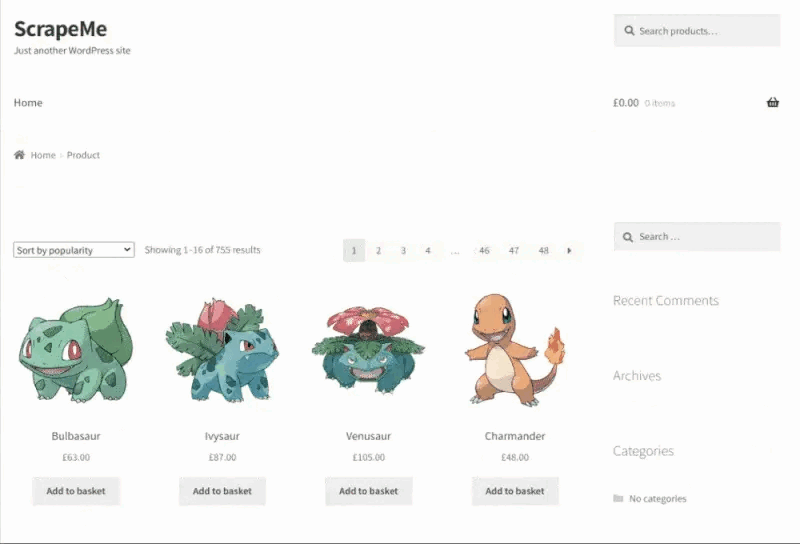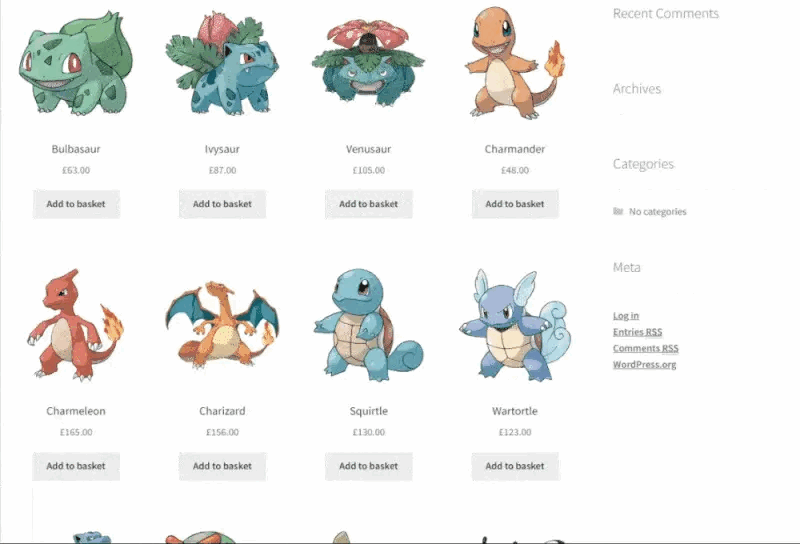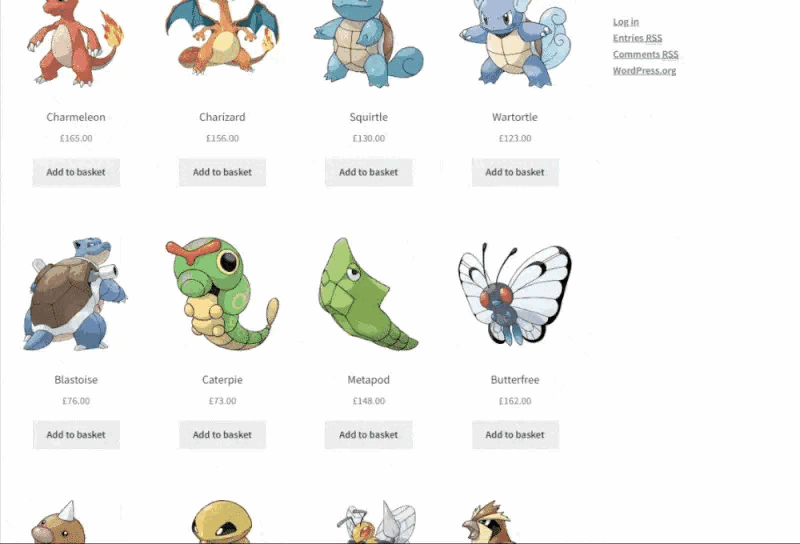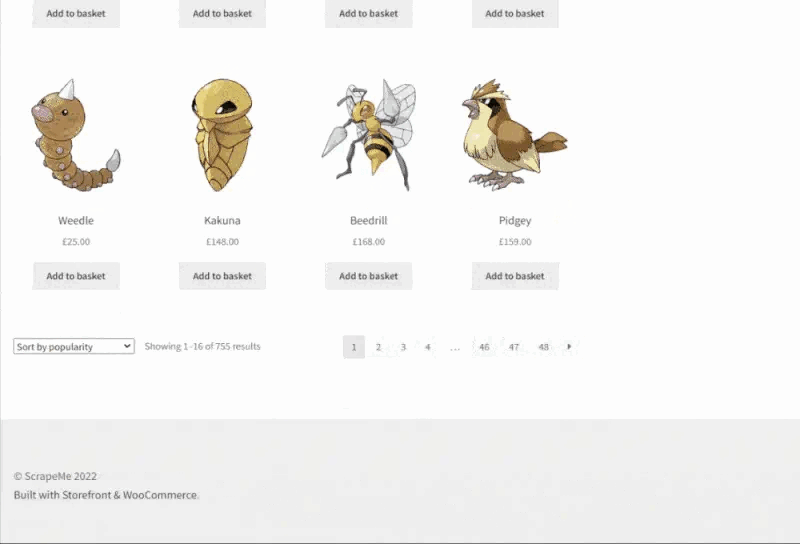
让我们安装一些依赖项并开始从网络上抓取数据。
第 1 步:安装 Html Agility Pack 及其 CSS 选择器扩展
Html Agility Pack (HAP) 是一个功能强大的开源 .NET 库,用于解析 HTML 文档。它为网络抓取提供了一个灵活的 API,允许您下载 HTML 页面并对其进行解析。您还可以选择 HTML 元素并从中提取数据。
通过NuGetHtmlAgilityPack包安装 Html Agility Pack 。
dotnet add package HtmlAgilityPack
尽管 Html Agility Pack原生支持XPath和XSLT,但在从 DOM 中选择 HTML 元素时,这些并不是最流行的方法。幸运的是,有HtmlAgilityPack CSS Selector扩展。
通过 NuGetHtmlAgilityPack.CssSelectors库安装它。
dotnet add package HtmlAgilityPack.CssSelectors
HAP 现在可以通过扩展方法理解 CSS 选择器。
现在,通过在文件顶部添加以下行,将 Html Agility Pack 导入到 C# 网络蜘蛛中Program.cs。
using HtmlAgilityPack;
如果 Visual Studio Code 没有报告错误,那么你就可以开始了。
是时候看看如何在 C# 中使用 HAP 进行网页抓取了!
第 2 步:加载目标网页
首先初始化一个 Html Agility Pack 对象。
var web = new HtmlWeb();
HtmlWeb使您可以访问 HAP 提供的网络抓取功能。
然后,使用HtmlWeb的Load()方法从 URL 获取 HTML。
// loading the target web page
var document = web.Load("https://scrapeme.live/shop/");
在后台,HAP 执行 HTTPGET请求以下载网页并解析其 HTML 内容。HtmlAgilityPack.HtmlWebException如果出现错误,它会引发一个错误,并HtmlDocument在一切按预期工作时提供一个 HAP 对象。
您现在可以使用它HtmlDocument从 HTML 元素中提取数据了。但首先,让我们研究目标页面的代码来定义选择 HTML 元素的有效策略。
第 3 步:检查目标页面
浏览目标网页以查看其结构。我们将从目标 HTML 节点开始,它们是产品元素。右键单击其中一个并通过选择“检查”选项访问浏览器 DevTools:

在这里,您可以清楚地看到单个li.productHTML 由以下四个元素组成:
- 中的产品 URL
a。 - 中的产品图片
img。 - 中的产品名称
h2。 - HTML 元素中的产品价格
.pricespan。
检查其他 HTML 产品,您会发现它们都共享相同的结构。什么变化是存储在底层 HTML 元素中的值。这意味着您可以通过编程方式全部抓取它们。
接下来,我们将学习如何使用 C# 中的 HAP 从这些产品 HTML 元素中抓取数据。
第 4 步:从 HTML 元素中提取数据
您需要定义一个自定义 C# 类来帮助您存储抓取的数据。为此,PokemonProduct在内部初始化一个嵌套类,Program如下所示:
public class PokemonProduct
{
public string? Url { get; set; }
public string? Image { get; set; }
public string? Name { get; set; }
public string? Price { get; set; }
}
此自定义类包含Url、Image、Name和Price字段。这些与您有兴趣从每种产品中提取的内容相匹配。
现在,使用以下行初始化函数PokemonProduct中的列表:Main()
var pokemonProducts = new List<PokemonProduct>();
这将包含存储在实例中的抓取数据PokemonProduct。
是时候使用 HAPli.product从 DOM 中提取所有 HTML 元素的列表了,如下所示:
// selecting all HTML product elements from the current page
var productHTMLElements = document.DocumentNode.QuerySelectorAll("li.product");
QuerySelectorAll()允许您使用 CSS 选择器从 DOM 中检索 HTML 节点。在这里,该方法应用li.productCSS 选择器策略来获取所有产品元素。具体来说,QuerySelectorAll()返回 HAP 对象的列表HtmlNode。
请注意,它QuerySelectorAll()来自 HAP CSS 选择器扩展,因此您不会在 Html Agility Pack 的原始界面中找到它。
使用foreach循环遍历 HTML 列表并从每个产品中抓取数据。
// iterating over the list of product elements
foreach (var productHTMLElement in productHTMLElements)
{
// scraping the interesting data from the current HTML element
var url = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("a").Attributes["href"].Value);
var image = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("img").Attributes["src"].Value);
var name = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("h2").InnerText);
var price = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector(".price").InnerText);
// instancing a new PokemonProduct object
var pokemonProduct = new PokemonProduct() { Url = url, Image = image, Name = name, Price = price };
// adding the object containing the scraped data to the list
pokemonProducts.Add(pokemonProduct);
}
该QuerySelector()方法在子节点中应用 CSS 选择器HtmlNode以仅获取一个。
然后,我们从中选择一个 HTML 属性Attributes并使用 提取它的日期Value。用 包裹每个值HtmlEntity.DeEntitize()以替换已知的HTML 实体。
再次注意,它QuerySelector()来自 Html Agility Pack CSS Selector 扩展。您不会在 vanilla HAP 中找到该方法。
惊人的!是时候学习如何以易于阅读的格式(例如 CSV)导出抓取的数据了。
第 5 步:将抓取的数据导出为 CSV
您可以使用本机 C# 函数将抓取的数据转换为 CSV,但库会使它更容易。
CsvHelper是一个快速、灵活且可靠的 .NET 库,用于读取和写入 CSV 文件。
通过将 NuGetCsvHelper包添加到项目的依赖项来安装它:
dotnet add package CsvHelper
通过将此行添加到文件顶部来将其导入到您的项目中Program.cs:
using CsvHelper;
使用 CsvHelper 将抓取的数据转换为 CSV 输出文件,如下所示:
// initializing the CSV output file
using (var writer = new StreamWriter("pokemon-products.csv"))
// initializing the CSV writer
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(pokemonProducts);
}
此处的代码片段初始化了一个pokemon-products.csv文件。然后,CsvHelperWriteRecords()将所有产品记录写入该 CSV 文件。由于 C#using语句,脚本将自动释放与写入对象关联的资源。
请注意,构造函数需要一个CultureInfo参数。这定义了格式规范以及要使用的定界符和行结束符。InvariantCulture确保无论用户的本地设置如何,任何软件都可以解析生成的 CSV。
要使用CultureInfo值,您需要以下额外导入:
using System.Globalization;
第 6 步:启动 Scraper
这是Program.cs到目前为止实现的 C# 数据抓取器的样子:
using HtmlAgilityPack;
using CsvHelper;
using System.Globalization;
namespace SimpleWebScraper
{
public class Program
{
// defining a custom class to store the scraped data
public class PokemonProduct
{
public string? Url { get; set; }
public string? Image { get; set; }
public string? Name { get; set; }
public string? Price { get; set; }
}
public static void Main()
{
// creating the list that will keep the scraped data
var pokemonProducts = new List<PokemonProduct>();
// creating the HAP object
var web = new HtmlWeb();
// visiting the target web page
var document = web.Load("https://scrapeme.live/shop/");
// getting the list of HTML product nodes
var productHTMLElements = document.DocumentNode.QuerySelectorAll("li.product");
// iterating over the list of product HTML elements
foreach (var productHTMLElement in productHTMLElements)
{
// scraping logic
var url = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("a").Attributes["href"].Value);
var image = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("img").Attributes["src"].Value);
var name = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("h2").InnerText);
var price = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector(".price").InnerText);
var pokemonProduct = new PokemonProduct() { Url = url, Image = image, Name = name, Price = price };
pokemonProducts.Add(pokemonProduct);
}
// crating the CSV output file
using (var writer = new StreamWriter("pokemon-products.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(pokemonProducts);
}
}
}
}
使用以下命令运行脚本:
dotnet run
根据目标页面服务器的响应时间,可能需要一段时间才能完成。完成后,您会pokemon-products.csv在 C# 项目的根文件夹中找到一个文件。打开它以浏览以下数据:

哇!在 50 行代码中,您构建了一个功能齐全的 C# 数据抓取器!
C# 中的高级网页抓取
C# 中的 Web 抓取远不止您刚刚看到的基础知识。现在,您将学习更多高级技术,帮助您成为 C# 数据抓取专家!
.NET 中的网络爬虫
不要忘记,ScrapeMe 显示的是一个分页的产品列表,它是由多个网页组成的目标网站。要抓取所有产品,您需要访问整个网站,这就是网络抓取的意义所在。
要在 C# 中进行网络爬虫,您必须跟踪所有分页链接。让我们把它们全部找回来!
检查分页 HTML 元素以了解如何提取页面的 URL。右键单击数字并选择“检查”:

选择“检查”选项以打开 DevTools 窗口
你应该能够在浏览器 DevTools 中看到类似这样的内容:
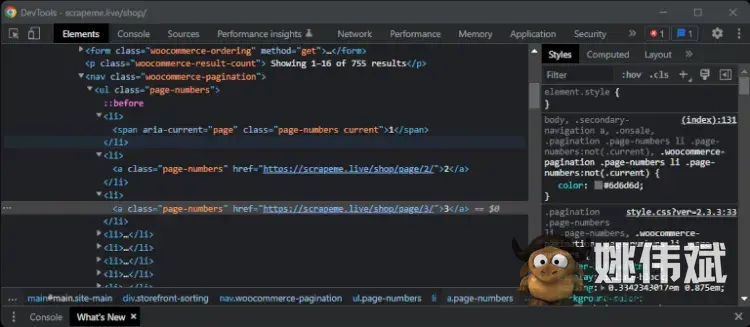
选择页码 HTML 元素后的 DevTools 窗口
在这里,请注意所有分页 HTML 元素共享page-numbersCSS 类。具体来说,只有 HTML 节点涉及 URL,而span元素是占位符。因此,您可以使用 CSS 选择器选择所有分页元素a.page-numbers。
为避免两次抓取页面,您需要一些额外的数据结构:
pagesDiscovered: AList跟踪爬虫发现的 URL。pagesToScrape:Queue包含蜘蛛将很快抓取的页面列表。
此外,limit变量将阻止 C# 蜘蛛永远抓取页面。
// the URL of the first pagination web page
var firstPageToScrape = "https://scrapeme.live/shop/page/1/";
// the list of pages discovered during the crawling task
var pagesDiscovered = new List<string> { firstPageToScrape };
// the list of pages that remains to be scraped
var pagesToScrape = new Queue<string>();
// initializing the list with firstPageToScrape
pagesToScrape.Enqueue(firstPageToScrape);
// current crawling iteration
int i = 1;
// the maximum number of pages to scrape before stopping
int limit = 5;
// until there are no pages to scrape or limit is hit
while (pagesToScrape.Count != 0 && i < limit)
{
// extracting the current page to scrape from the queue
var currentPage = pagesToScrape.Dequeue();
// loading the page
var currentDocument = web.Load(currentPage);
// selecting the list of pagination HTML elements
var paginationHTMLElements = currentDocument.DocumentNode.QuerySelectorAll("a.page-numbers");
// to avoid visiting a page twice
foreach (var paginationHTMLElement in paginationHTMLElements)
{
// extracting the current pagination URL
var newPaginationLink = paginationHTMLElement.Attributes["href"].Value;
// if the page discovered is new
if (!pagesDiscovered.Contains(newPaginationLink))
{
// if the page discovered needs to be scraped
if (!pagesToScrape.Contains(newPaginationLink))
{
pagesToScrape.Enqueue(newPaginationLink);
}
pagesDiscovered.Add(newPaginationLink);
}
}
// scraping logic...
// incrementing the crawling counter
i++;
}
上面的数据爬虫执行以下操作:
- 从分页列表的第一页开始。
- 在当前页面上查找新的分页 URL。
- 将它们添加到抓取队列中。
- 从当前页面抓取数据。
- 对队列中的每个页面重复前四个步骤,直到没有页面或它访问了多个
limit页面。
由于 ScrapeMe 由 48 个页面组成,设置limit为 48 以从所有产品中抓取数据。在这种情况下,pokemon-product.csv将对网站上包含的 755 种产品中的每一种都有记录。
干得好!您现在可以构建一个可以抓取完整网站的网络抓取 C# 应用程序!
避免被封锁
C# 中的数据抓取器可能会失败。这是由于网站可能采用的几种反抓取机制。您的脚本应该准备好许多反抓取技术。使用ZenRows轻松绕过它们!
最基本的技术是根据标头的值来阻止 HTTP 请求。这通常发生在请求使用无效User-Agent值时。
标User-Agent头包含限定请求来源的信息。通常,接受的是指流行的浏览器和操作系统。抓取库倾向于使用User-Agent可以轻松暴露您的蜘蛛的占位符。
User-Agent您可以使用以下行在 Html Agility Pack 中全局设置有效:
// setting a global User-Agent header in HAP web.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36";
现在,HAP 执行的所有 HTTP 请求似乎都来自 Chrome 109。
C# 中的并行 Web 抓取
使用 C# 进行网络抓取的性能取决于目标网络服务器的速度。通过同时发出并行请求和抓取页面来解决这个问题。避免停滞时间,将你的爬虫速度提升到一个新的水平……这就是 C# 中的并行网络爬虫!
将您的 C# 数据爬虫应访问的所有页面的列表存储在ConcurrentBag:
var pagesToScrape = new ConcurrentBag<string> {
"https://scrapeme.live/shop/page/1/",
"https://scrapeme.live/shop/page/2/",
"https://scrapeme.live/shop/page/3/",
// ...
"https://scrapeme.live/shop/page/47/",
"https://scrapeme.live/shop/page/48/"
};
在 C# 中,List它不是线程安全的,在并行任务中不应该使用它。用它的无序线程安全替代品替换它ConcurrentBag。
出于同样的原因,制作pokemonProducts一个ConcurrentBag:
var pokemonProducts = new ConcurrentBag<PokemonProduct>();
让我们用 C# 执行并行网络抓取!用于在C#中并行Parallel.forEach()执行foreach循环并同时抓取多个页面:
// the import statement required to use Parallel.forEach()
using System.Collections.Concurrent;
// ...
Parallel.ForEach(
pagesToScrape,
// limiting the parallelization level to 4 pages at a time
new ParallelOptions { MaxDegreeOfParallelism = 4 },
currentPage => {
// visiting the current page of the loop
var currentDocument = web.Load(currentPage);
// complete scrapping logic
var productHTMLElements = currentDocument.DocumentNode.QuerySelectorAll("li.product");
foreach (var productHTMLElement in productHTMLElements)
{
var url = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("a").Attributes["href"].Value);
var image = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("img").Attributes["src"].Value);
var name = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("h2").InnerText);
var price = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector(".price").InnerText);
var pokemonProduct = new PokemonProduct() { Url = url, Image = image, Name = name, Price = price };
// storing the scraped product data in parallel
pokemonProducts.Add(pokemonProduct);
}
}
);
您的 C# 网络抓取工具现在快如闪电!但是不要忘记限制并行化级别以避免对服务器造成压力。您的目标是从网站提取数据,而不是执行 DoS 攻击。
上面的代码片段作为一个例子来理解如何在C#中实现并行爬取。在这里查看整个并行 C# 数据蜘蛛:
using HtmlAgilityPack;
using CsvHelper;
using System.Globalization;
using System.Collections.Concurrent;
namespace SimpleWebScraper
{
public class Program
{
public class PokemonProduct
{
public string? Url { get; set; }
public string? Image { get; set; }
public string? Name { get; set; }
public string? Price { get; set; }
}
public static void Main()
{
// initializing HAP
var web = new HtmlWeb();
// this can't be a List because it's not thread-safe
var pokemonProducts = new ConcurrentBag<PokemonProduct>();
// the complete list of pages to scrape
var pagesToScrape = new ConcurrentBag<string> {
"https://scrapeme.live/shop/page/1/",
"https://scrapeme.live/shop/page/2/",
// ...
"https://scrapeme.live/shop/page/48/"
};
// performing parallel web scraping
Parallel.ForEach(
pagesToScrape,
new ParallelOptions { MaxDegreeOfParallelism = 4 },
currentPage =>
{
var currentDocument = web.Load(currentPage);
var productHTMLElements = currentDocument.DocumentNode.QuerySelectorAll("li.product");
foreach (var productHTMLElement in productHTMLElements)
{
var url = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("a").Attributes["href"].Value);
var image = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("img").Attributes["src"].Value);
var name = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("h2").InnerText);
var price = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector(".price").InnerText);
var pokemonProduct = new PokemonProduct() { Url = url, Image = image, Name = name, Price = price };
pokemonProducts.Add(pokemonProduct);
}
}
);
// exporting to CSV
using (var writer = new StreamWriter("pokemon-products.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(pokemonProducts);
}
}
}
}
在 C# 中使用无头浏览器抓取动态内容网站
静态内容站点将其所有内容嵌入到服务器返回的 HTML 页面中。这使它们成为任何 HTML 解析库的轻松抓取目标。
动态内容网站使用 JavaScript 呈现或检索数据。那是因为它们依靠 JavaScript 来动态检索全部或部分内容。抓取此类网站需要一个可以运行 JavaScript 的工具,例如无头浏览器。如果您不熟悉这个术语,无头浏览器是一种没有 GUI 的可编程浏览器。
Selenium是最常用的 C# 无头浏览器库,下载量超过 6500 万次。安装Selenium.WebDriver的 NuGet 包。
dotnet add package Selenium.WebDriver
在 headless 模式下使用 Selenium 从 ScrapeMe 中抓取数据,逻辑如下:
using CsvHelper;
using System.Globalization;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace SimpleWebScraper
{
public class Program
{
public class PokemonProduct
{
public string? Url { get; set; }
public string? Image { get; set; }
public string? Name { get; set; }
public string? Price { get; set; }
}
public static void Main()
{
var pokemonProducts = new List<PokemonProduct>();
// to open Chrome in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
// starting a Selenium instance
using (var driver = new ChromeDriver(chromeOptions))
{
// navigating to the target page in the browser
driver.Navigate().GoToUrl("https://scrapeme.live/shop/");
// getting the HTML product elements
var productHTMLElements = driver.FindElements(By.CssSelector("li.product"));
// iterating over them to scrape the data of interest
foreach (var productHTMLElement in productHTMLElements)
{
// scraping logic
var url = productHTMLElement.FindElement(By.CssSelector("a")).GetAttribute("href");
var image = productHTMLElement.FindElement(By.CssSelector("img")).GetAttribute("src");
var name = productHTMLElement.FindElement(By.CssSelector("h2")).Text;
var price = productHTMLElement.FindElement(By.CssSelector(".price")).Text;
var pokemonProduct = new PokemonProduct() { Url = url, Image = image, Name = name, Price = price };
pokemonProducts.Add(pokemonProduct);
}
}
// export logic
using (var writer = new StreamWriter("pokemon-products.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(pokemonProducts);
}
}
}
}
SeleniumFindElements()函数允许指示浏览器查找 HTML 节点。多亏了它,您可以通过 CSS 选择器查询选择产品 HTML 元素。然后,在循环中迭代它们foreach。应用GetAttribute()并用于Text提取感兴趣的数据。
使用 HAP 或 Selenium 在 C# 中抓取网站在代码方面大致相同。区别在于它们运行抓取逻辑的方式。HAP 解析 HTML 页面以从中提取数据,Selenium 在无头浏览器中运行抓取语句。
感谢 Selenium,您可以像真实用户一样抓取动态内容网站并在浏览器中与网页交互。这也意味着您的脚本不太可能被检测为机器人,因为 Selenium 可以更轻松地抓取网页而不会被阻止。
Html Agility Pack 不具备完整的浏览器功能,因此您只能使用 HAP 来抓取静态内容网站。并且它不涉及运行典型的 Selenium 浏览器的资源开销。
放在一起:最终代码
以下是使用 Html Agility Pack 构建的具有爬虫和基本反块逻辑的 C# 爬虫的完整代码:
using HtmlAgilityPack;
using System.Globalization;
using CsvHelper;
using System.Collections.Concurrent;
namespace SimpleWebScraper
{
public class Program
{
// defining a custom class to store
// the scraped data
public class PokemonProduct
{
public string? Url { get; set; }
public string? Image { get; set; }
public string? Name { get; set; }
public string? Price { get; set; }
}
public static void Main()
{
// initializing HAP
var web = new HtmlWeb();
// setting a global User-Agent header
web.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36";
// creating the list that will keep the scraped data
var pokemonProducts = new List<PokemonProduct>();
// the URL of the first pagination web page
var firstPageToScrape = "https://scrapeme.live/shop/page/1/";
// the list of pages discovered during the crawling task
var pagesDiscovered = new List<string> { firstPageToScrape };
// the list of pages that remains to be scraped
var pagesToScrape = new Queue<string>();
// initializing the list with firstPageToScrape
pagesToScrape.Enqueue(firstPageToScrape);
// current crawling iteration
int i = 1;
// the maximum number of pages to scrape before stopping
int limit = 5;
// until there is a page to scrape or limit is hit
while (pagesToScrape.Count != 0 && i < limit)
{
// getting the current page to scrape from the queue
var currentPage = pagesToScrape.Dequeue();
// loading the page
var currentDocument = web.Load(currentPage);
// selecting the list of pagination HTML elements
var paginationHTMLElements = currentDocument.DocumentNode.QuerySelectorAll("a.page-numbers");
// to avoid visiting a page twice
foreach (var paginationHTMLElement in paginationHTMLElements)
{
// extracting the current pagination URL
var newPaginationLink = paginationHTMLElement.Attributes["href"].Value;
// if the page discovered is new
if (!pagesDiscovered.Contains(newPaginationLink))
{
// if the page discovered needs to be scraped
if (!pagesToScrape.Contains(newPaginationLink))
{
pagesToScrape.Enqueue(newPaginationLink);
}
pagesDiscovered.Add(newPaginationLink);
}
}
// getting the list of HTML product nodes
var productHTMLElements = currentDocument.DocumentNode.QuerySelectorAll("li.product");
// iterating over the list of product HTML elements
foreach (var productHTMLElement in productHTMLElements)
{
// scraping logic
var url = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("a").Attributes["href"].Value);
var image = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("img").Attributes["src"].Value);
var name = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector("h2").InnerText);
var price = HtmlEntity.DeEntitize(productHTMLElement.QuerySelector(".price").InnerText);
var pokemonProduct = new PokemonProduct() { Url = url, Image = image, Name = name, Price = price };
pokemonProducts.Add(pokemonProduct);
}
// incrementing the crawling counter
i++;
}
// opening the CSV stream reader
using (var writer = new StreamWriter("pokemon-products.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(pokemonProducts);
}
}
}
}
C# 中的其他 Web 抓取库
使用 C# 进行 Web 抓取时需要考虑的其他工具是:
- ZenRows:一个功能齐全且易于使用的 API,可以轻松地从网页中提取数据。ZenRows 为任何反机器人或反抓取系统提供自动旁路。此外,它还带有旋转代理、无头浏览器功能和 99% 的正常运行时间保证。
- Puppeteer Sharp:流行的Puppeteer Node.js 库的 .NET 端口。有了它,您可以指示无头 Chromium 浏览器执行测试和抓取。
- AngleSharp:用于解析和操作 XML 和 HTML 的开源 .NET 库。它允许您从网站中提取数据并通过 CSS 选择器选择 HTML 元素。
这是一个简短的提醒,还有其他有用的工具可以使用 C# 进行数据抓取。阅读我们关于最佳 C# 网络抓取库的指南。
结论
我们的分步教程涵盖了您需要了解的有关使用 C# 进行网页抓取的所有信息。首先,我们学习了基础知识,然后处理了最高级的 C# 网络抓取概念。
回顾一下,您现在知道:
- 如何使用 Html Agility Pack 在 C# 中进行基本的 Web 抓取。
- 如何通过网络抓取来抓取整个网站。
- 当您需要使用 C# 无头浏览器解决方案时。
- 如何使用 Selenium 从动态内容网站中提取数据。
使用 C# 抓取 Web 数据是一项挑战。这是由于网站现在使用的许多反抓取技术。绕过它们并不容易,您总是需要找到解决方法。使用完整的C# 网络抓取 API避免这一切。多亏了它,您可以通过 API 调用执行数据抓取而忘记反机器人保护。
常见问题
如何从 C# 中的网站抓取数据?
在 C# 中从 Web 抓取数据与在其他编程语言中一样发生。使用 C# 网络抓取库,您可以连接到所需的网站,从其 DOM 中选择 HTML 元素,并检索数据。
C# 适合网页抓取吗?
是的!C# 是一种通用编程语言,可让您进行网络抓取。C# 有一个庞大而活跃的社区,该社区开发了许多库来帮助您实现抓取目标。
使用 C# 抓取的最佳方式是什么?
在 C# 中使用众多 NuGet 库之一进行抓取使一切变得更容易。支持您的数据爬网项目的一些最流行的 C# 库是 Selenium、ScrapySharp 和 Html Agility Pack。






