

如何使用Axios和Cheerio进行网页抓取
网络抓取是从网站提取内容和数据的过程。这称为刮擦。抓取网站的原因有无数。今天我们将学习如何在 Axios 的帮助下实现这一点,Axios 是一款适用于 Node.js 和浏览器的出色 HTTP 客户端。
Axios 是做什么的?
Axios 允许您以类似于浏览器的方式向网站和服务器发出请求。但 Axios 允许您使用代码来操纵响应,而不是直观地呈现结果。这在网络抓取的上下文中非常有用。
在本教程中,我们将抓取ScrapeMe(一种旨在抓取的电子商务)的内容,以了解该过程。具体来说,我们将提取一些产品的名称及其价格。通过使用您将在本文中学到的技术,您可以将 Axios 网页抓取的强大功能应用到许多网站。
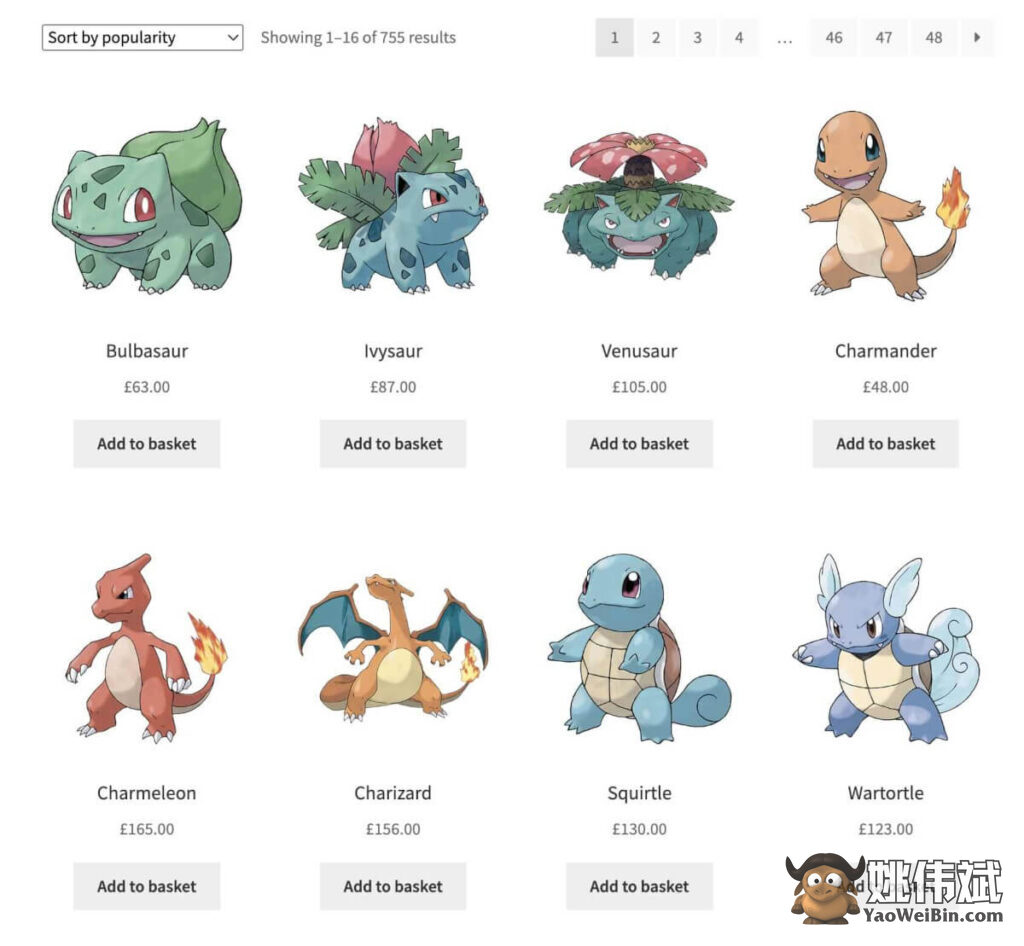
我们将抓取的产品列表
开始之前
- 您知道如何使用任何编程语言进行开发。最好是用 JavaScript 编写。
- 您知道如何使用CSS 选择器来访问DOM元素。
- 您需要在计算机上安装 Node 和 npm。如果您需要这方面的帮助,可以参考下载并安装 Node.js 和 npm。
Axios 网页抓取的目的是什么?
有时,您可以以结构化方式(例如 JSON 格式)从 Web API 获取所需的数据。在许多情况下,访问某些数据的唯一方法是从公共网站获取数据。这可能是一项成本高昂且耗时的任务,但 Axios 网络抓取允许您自动执行此过程,以便您可以有效地从网站获取数据和内容。
如果您是一位长期使用 Axios 的前端开发人员,您可能想知道是否可以使用 Axios 来抓取网站。这实际上是一个好主意,因为它在浏览器和 Node.js 上运行,对 Typescript 有很好的支持,有可靠的文档,并且网络上有很多示例。
初始设置
为您的 Axios 网页抓取项目创建一个新文件夹。我将其命名为scraper,但我相信您可以想出一个更有想象力的名字。在该文件夹中打开终端,然后执行以下命令来设置新的 npm 包并在其上安装 Axios。
npm init -y npm install axios
使用您最喜欢的 IDE 或代码编辑器,在该文件夹的根目录下创建一个名为的新文件index.js,并将以下代码粘贴到其中:
const axios = require('axios');
axios.get('https://scrapeme.live/shop/')
.then(({ data }) => console.log(data));
我们需要调整我们的package.json文件才能运行我们的代码。在脚本部分中,我们将添加一个新脚本以便能够运行我们的index.js文件。您的package.json文件应类似于以下内容:
{
"name": "scraper",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1",
"start": "node index.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^0.27.2"
}
}
在终端上输入npm start以运行代码。如果成功,您将在终端上看到打印的网页的所有 HTML。

那很简单!但不是很有用,因为我们想要的信息都与网站的其他内容混在一起。这就是Cheerio派上用场的地方。它是一个库,为我们提供了专为服务器设计的核心 jQuery 的高效实现。
奇瑞欧是做什么的?
在 Axios 网页抓取的上下文中,Cheerio 对于选择特定 HTML 元素并提取其信息非常有用。然后,您可以根据需要组织或转换该信息。在我们的例子中,我们将使用它来获取目标网站上产品的名称和价格。
将 Cheerio 与 Axios 结合使用
首先,通过在我们一直使用的同一文件夹中运行以下命令来安装它:
npm install cheerio
现在我们需要告诉cheerios我们对哪条信息感兴趣。为此,请使用浏览器开发工具(例如使用Chrome)检查网页:

正如您所看到的,包含产品名称的元素使用 class 属性woocommerce-loop-product__title。让我们修改我们的index.js文件,使其看起来像这样选择这些元素。
const axios = require('axios');
const cheerio = require('cheerio');
axios.get('https://scrapeme.live/shop/')
.then(({ data }) => {
const $ = cheerio.load(data);
const pokemonNames = $('.woocommerce-loop-product__title')
.map((_, product) => {
const $product = $(product);
return $product.text()
})
.toArray();
console.log(pokemonNames)
});
您准备好运行代码来进行第一次 Axios 网络抓取了吗?如果答案是肯定的,请运行代码,如果一切顺利,您将在屏幕上看到一个不错的产品列表。
让我们稍微修改一下代码以获取产品的价格。首先,我们将定位 DOM 中包含产品名称和价格的父元素。li.product似乎已经足够了。
在本例中,我们想要的类属性是woocommerce-Price-amount,因此我们应该在文件中添加一段代码index.js,如下所示:
const axios = require('axios');
const cheerio = require('cheerio');
axios.get('https://scrapeme.live/shop/')
.then(({ data }) => {
const $ = cheerio.load(data);
const pokemons = $('li.product')
.map((_, pokemon) => {
const $pokemon = $(pokemon);
const name = $pokemon.find('.woocommerce-loop-product__title').text()
const price = $pokemon.find('.woocommerce-Price-amount').text()
return {'name': name, 'price': price}
})
.toArray();
console.log(pokemons)
});
运行此命令将输出使用 Axios 网络抓取检索到的产品的不错列表。

您要抓取的网站是什么?
我们刚刚使用的技术对于简单的网站来说效果很好。然而,其他人会尝试阻止 Axios 网络抓取。在这些情况下,让我们的请求看起来与实际浏览器执行的请求类似是很有用的。
网站所做的最基本的验证之一是检查用户代理标头。这是一个字符串,用于通知服务器有关请求用户代理的操作系统、供应商和版本的信息。编写用户代理字符串有不同的方法。例如,就我而言,我得到:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36
此“演示卡”通知网站正在运行 macOS Catalina 的英特尔 Mac 上通过 Chrome 浏览器版本 104 访问该网站。
要使用 Axios 发送附加标头,我们可以将附加config参数传递给请求方法。我们可以检查 Axios 是否正在使用httpbin发送这些标头。因此,让我们headers.js在项目的根文件夹中创建一个名为的新文件,其中包含以下内容:
const axios = require('axios');
const config = {
headers: {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
},
};
axios.get('https://httpbin.org/headers', config)
.then(({ data }) => {
console.log(data)
});
我们还需要在文件中创建一个新命令package.json。您可以将其命名为 headers,如以下代码片段所示:
{
"name": "scraper",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1",
"start": "node index.js",
"headers": "node headers.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^0.27.2",
"cheerio": "^1.0.0-rc.12"
}
}
使用命令在终端上运行它npm run headers,我们发送的标头应该出现在屏幕上:

为了更好地避免网站阻止您的脚本,最好除了用户代理之外还发送其他标头。您可以使用浏览器访问httpbin以检查它发送的所有标头。它应该返回类似这样的内容:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Host": "httpbin.org",
"Sec-Ch-Ua": ""Chromium";v="104", " Not A;Brand";v="99", "Google Chrome";v="104"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": ""macOS"",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-630ce94f-289bc1c678d8cd7153e42f5a"
}
}
您可以开始添加其中一些标头,以检查您尝试抓取的网站是否有良好的结果。如果您想查看我们使用的示例的完整代码,您可以在这个Axios 抓取存储库中找到它。
避免阻塞
请记住,标头检查并不是网站用来识别爬虫和抓取工具的唯一方法。例如,如果您从同一 IP 地址发出过多请求,您也可能会被阻止或禁止。在这种情况下,您可以命令 Axios 使用代理服务器,该服务器将充当 Axios 网页抓取脚本和网站主机之间的中介。
另一个常见问题是目标网站是单页应用程序。例如,当您使用 Axios 抓取 React 网站时。在这种情况下,Axios 会抓取服务器发送的 HTML 代码,但这可能不包含您需要的数据,因为该数据是由最终用户浏览器上运行的 Javascript 代码获取的。在这些情况下,使用无头浏览器或网页抓取 API可能是更好的解决方案。
提示:有关如何配置 Axios 以使用代理以及如何使用无头浏览器进行抓取的更多信息,请阅读我们有关使用 Javascript 和 NodeJS 进行网页抓取的指南。
结论
正如我们在本教程中看到的,网络抓取可能很简单,也可能很困难,具体取决于您尝试抓取的网站。有时,您只需要:
- 使用 Axios 发出请求。
- 在回调中获取数据。
- 用Cheerios 选择相关部件。
- 使用普通 Javascript 格式化信息。
但如果目标网站实施了反抓取措施,则需要使用更先进的技术。其中一些技术包括添加 HTTP 标头或使用代理。
如果您更愿意专注于从抓取的数据中生成价值,而不是尝试绕过反机器人系统,请尝试将Web 抓取 API与 Axios 结合使用。






