使用Python进行网络抓取:逐步指南

网络爬虫是从网站提取信息并将其用于特定用途的概念。
假设您想从网页中提取一个表格,将其转换为JSON文件并使用该JSON文件构建一些内部工具。借助网络爬虫的帮助,您可以通过定位网页中的特定元素来提取所需的数据。使用Python进行网络爬虫是一个非常受欢迎的选择,因为Python提供了多个库,如BeautifulSoup或Scrapy,可以有效地提取数据。

掌握高效提取数据的技能对于开发人员或data scientist也非常重要。本文将帮助您了解如何有效地抓取网站并获取所需内容以根据您的需求进行操作。对于本教程,我们将使用BeautifulSoup包。它是Python中用于抓取数据的一种流行包。
为什么使用Python进行网络爬虫?
在构建网络爬虫时,许多开发人员首选Python。有许多原因可以解释为何选择Python,但在本文中,我们将讨论三个首要原因。
库和社区支持:Python有几个出色的库,如BeautifulSoup、Scrapy、Selenium等,提供了很多强大的函数来高效抓取网页。它构建了一个出色的网络爬虫生态系统,而且因为全球范围内已经有许多开发人员使用Python,所以在遇到困难时,您可以很快获得帮助。
自动化:Python以其自动化能力而闻名。如果您正在尝试构建依赖于抓取的复杂工具,那么仅仅进行网络爬虫是远远不够的。例如,如果您想构建一个追踪在线商店商品价格的工具,您需要添加一些自动化功能,以便它可以每天跟踪价格并将其添加到数据库中。Python让您能够轻松地自动化这些流程。
数据可视化:数据科学家经常需要从网页中提取数据。借助像Pandas这样的库,Python可以更轻松地从原始数据中实现数据可视化。
Python中的网络爬虫库
Python中有几个可用于简化网络爬虫的库。让我们讨论这里最受欢迎的三个库。
#1. BeautifulSoup
这是一个非常受欢迎的网络爬虫库之一。自2004年以来,BeautifulSoup一直帮助开发人员抓取网页。它提供了简单的方法来导航、搜索和修改解析树。Beautifulsoup本身还会对传入和传出的数据进行编码。它得到了良好的维护,并拥有一个伟大的社区。
#2. Scrapy
这是另一个用于数据提取的流行框架。在Github上,Scrapy已经获得了超过43000个星标。它也可以用于从API中抓取数据。它还有一些有趣的内置支持,比如发送电子邮件。
#3. Selenium
Selenium不是主要用于网络爬虫的库。它是一个浏览器自动化工具包。但是我们可以很容易地扩展它的功能以便抓取网页。它使用WebDriver协议来控制不同的浏览器。Selenium已经在市场上存在了近20年。但是使用Selenium,您可以轻松地自动化并从网页中抓取数据。
Python网络爬虫的挑战
在尝试从网站抓取数据时,可能会遇到许多挑战。存在诸如网络缓慢、反爬虫工具、基于IP的封锁、验证码阻止等问题。这些问题在尝试抓取网站时可能会引发严重的问题。
但是您可以通过以下一些方法有效地绕过挑战。例如,在大多数情况下,当在特定时间间隔内发送的请求超过一定数量时,网站会阻止。为了避免IP阻止,您需要编写您的爬虫代码,以便在发送请求后冷却。

开发人员还倾向于为爬虫设置蜜罐陷阱。这些陷阱通常对肉眼不可见,但却可以被爬虫爬取。如果您正在爬取设置了这种蜜罐陷阱的网站,您需要相应地编写您的爬虫代码。
Captcha是爬虫面临的另一个严重问题。大多数网站现在使用验证码来保护机器人访问他们的页面。在这种情况下,您可能需要使用验证码解决器。
使用Python爬取网站
正如我们讨论的那样,我们将使用BeautifulSoup来爬取一个网站。在本教程中,我们将从Coingecko爬取以太坊的历史数据,并将表格数据保存为JSON文件。让我们继续构建爬虫。
第一步是安装BeautifulSoup和Requests。在本教程中,我将使用Pipenv。Pipenv是Python的虚拟环境管理器。如果您愿意,您也可以使用Venv,但我更喜欢Pipenv。讨论Pipenv超出了本教程的范围。但是,如果您想了解如何使用Pipenv,请关注this guide。或者,如果您想了解Python虚拟环境,请关注this guide。
通过运行命令pipenv shell在项目目录中启动Pipenv shell。它将在您的虚拟环境中启动一个子shell。现在,要安装BeautifulSoup,请运行以下命令:
pipenv install beautifulsoup4要安装requests,请运行类似于上述命令的命令:
pipenv install requests安装完成后,将必要的包导入到主文件中。创建一个名为main.py的文件,并像下面这样导入包:
from bs4 import BeautifulSoup
import requests
import json下一步是获取历史数据页面的内容,并使用BeautifulSoup中的HTML解析器对其进行解析。
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data')
soup = BeautifulSoup(r.content, 'html.parser')在上面的代码中,使用requests库中提供的get方法访问页面。然后将解析的内容存储在名为soup的变量中。
现在开始原始的爬取部分。首先,您需要正确地在DOM中定位表格。如果您打开this page并使用浏览器中提供的开发者工具进行检查,您会看到该表格具有这些类table table-striped text-sm text-lg-normal。
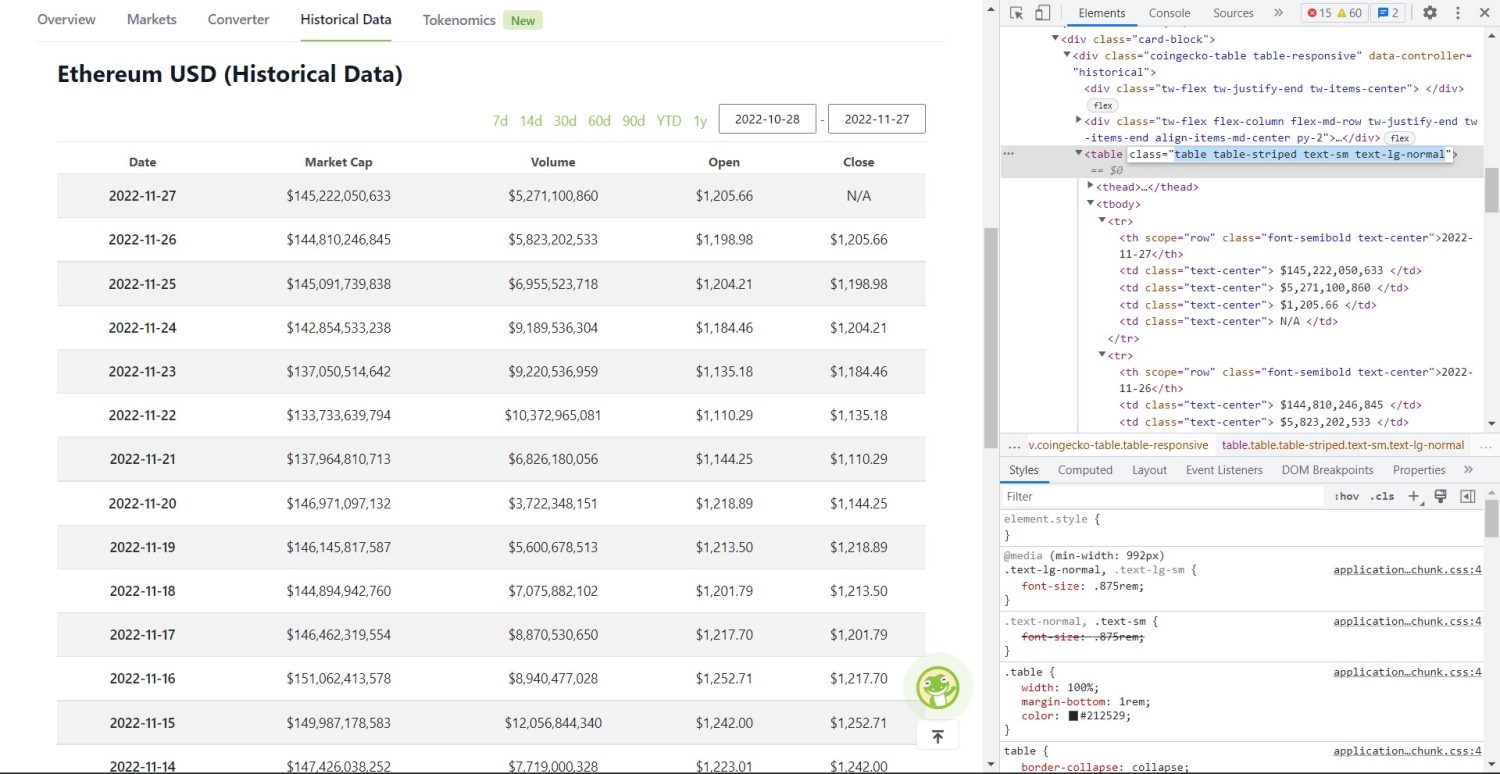
为了正确地定位这个表格,您可以使用find方法。
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)在上面的代码中,首先使用soup.find方法找到表格,然后使用find_all方法搜索表格内的所有tr元素。将这些tr元素存储在名为table_data的变量中。该表格有一些th元素用于标题。为保留标题,初始化了一个名为table_headings的变量,用于将标题存储在一个列表中。
然后对表格的第一行运行for循环。在该行中,搜索所有带有th的元素,并将它们的文本值添加到table_headings列表中。使用text方法提取文本。如果现在打印table_headings变量,您将能够看到以下输出:
['日期', '市值', '交易量', '开盘价', '收盘价']下一步是爬取其余的元素,为每一行生成一个字典,然后将行追加到列表中。
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)这是代码的关键部分。对于table_data变量中的每个tr,首先搜索th元素。th元素是表格中显示的日期。这些th元素存储在变量th中。同样,所有td元素存储在td变量中。
初始化一个空字典data。初始化完成后,我们循环遍历td元素的范围。对于每一行,首先我们使用第一个th的第一个项目更新字典的第一个字段。代码table_headings[0]: th[0].text为日期和第一个th元素分配了一个键值对。
在初始化第一个元素之后,其他元素使用data.update({table_headings[i+1]: td[i].text.replace('n', '')})进行赋值。在这里,首先使用text方法提取td元素的文本,然后使用replace方法替换所有的n。然后将值分配给table_headings列表的第i+1个元素,因为第i个元素已经被赋值。
然后,如果data字典的长度大于零,我们将字典追加到table_details列表中。您可以打印table_details列表进行检查。但我们将把值写入JSON文件。让我们看看这部分代码,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('数据保存到json文件中...')我们在这里使用json.dump方法将值写入名为table.json的JSON文件。写入完成后,我们将数据保存到json文件中...打印到控制台。
现在,使用以下命令运行文件,
python run main.py一段时间后,您将能够在控制台中看到数据保存到JSON文件...的文本。您还将在工作文件目录中看到一个名为table.json的新文件。该文件将类似于以下JSON文件:
[
{
"日期": "2022-11-27",
"市值": "$145,222,050,633",
"交易量": "$5,271,100,860",
"开盘价": "$1,205.66",
"收盘价": "N/A"
},
{
"日期": "2022-11-26",
"市值": "$144,810,246,845",
"交易量": "$5,823,202,533",
"开盘价": "$1,198.98",
"收盘价": "$1,205.66"
},
{
"日期": "2022-11-25",
"市值": "$145,091,739,838",
"交易量": "$6,955,523,718",
"开盘价": "$1,204.21",
"收盘价": "$1,198.98"
},
// ...
// ...
]您已成功使用Python实现了一个网络爬虫。要查看完整的代码,您可以访问这个GitHub repo。
结论
这篇文章讨论了如何实现一个简单的Python抓取。我们讨论了如何使用BeautifulSoup从网站快速抓取数据。我们还讨论了其他可用的库以及为什么Python是许多开发人员抓取网站的首选。
你也可以查看这些web scraping frameworks。

![如何使用VMware Fusion安装Kali Linux?[逐步指南]](https://yaoweibin.cn/wp-content/uploads/2023/08/20230831173426-64f0cf2241f96-768x394.webp)