

如何抓举网页实时数据
人们从网站上抓取实时数据的用例和原因各不相同,要么是为了跟踪数据更新,如股票价格、加密货币汇率和足球比分,要么是为了了解最新的商店库存。
在本文中,我们将讨论什么是实时网络抓取、如何抓取数据以及最适合您项目的实时网络抓取工具。
什么是实时网页抓取?
实时网络抓取是使用抓取工具和爬虫从网页抓取数据的过程,几乎与网站发生变化的时间相同。
实时网络抓取背后的想法是能够在数据发生变化时立即捕获数据,无论这种变化是在几分钟还是几秒钟之内。我们可以使用服务使用的实时 API 或通过解析 HTML 并克服我们将讨论的限制来处理实时 Web 抓取。
离线和实时网页抓取有什么区别?
离线网络抓取的工作原理是下载您想要抓取的网站的一部分,然后对其进行解析以提取数据并将其保存在数据库、CSV 或 JSON 文件中。实时网络抓取通过使用实时 API 或在很短的时间内解析 HTML 来工作,从而可以在数据发生变化时立即提取数据。
那么实时抓取网页最快的方法是什么?最佳解决方案是使用服务的实时数据 API。但是很多站点不提供 API 或者它受到了很好的保护,但是我们可以通过解析具有 2-5 阈值的 HTML 来获取实时数据,但这不是最佳解决方案。
实时网络抓取有什么好处?
实时网络抓取的好处在于能够获取额外的实时数据并将其用于商业或个人目的。例如,抓取实时股票数据可用于进行交易分析和决策,企业使用实时数据来管理产品和优化运营。
Web 抓取实时数据的其他一些用例包括:
- 改善客户服务。
- 保持存货盘点。
- 股票分析。
- 为营销人员提高营销活动绩效。
Web 抓取实时数据所涉及的挑战
是否可以一直向网站发送请求并在每次收到新响应时更新数据?是的,但是有一些限制:
1次
发送请求和解析 HTML 可能需要一些时间,因此如果整个过程需要 2 或 3 分钟,则数据可能会在不到一分钟或更短的时间内发生变化,从而使提取的数据过时。
Web 从超链接抓取实时数据也很慢,因为爬虫在向超链接发送请求时采取了另一个步骤,使其使用更多的功率和时间。
2.防火墙阻断
向服务器发送太多请求可能会提醒防火墙,从而阻止请求。尽管这应该不是问题,因为我们有关于如何在不被阻止的情况下从网站抓取数据的指南。
3.它会使主机站点崩溃
多次请求 Web 资源可能会在 Web 源主机上造成额外的负载,甚至可能导致网站崩溃。
4.代理失败
当涉及到实时网络抓取时,代理可能会带来不同的问题,例如停机时间和列入黑名单的 IP 地址等问题,因此建议使用可靠的代理服务器。
5.反机器人
一些网站安装了反机器人程序,可以阻止网络抓取工具,使其难以抓取,这可能会限制我们的输出。这些反机器人包括速率限制、指纹识别、蜜罐和 CAPTCHA。
如何实时抓取数据
我们已经了解了基础知识和优势,是时候开始使用 Python 进行实时网络抓取了。让我们尝试抓取 coinmarketcap.com,这是一个可靠的加密货币价格网站。您还可以使用此方法从 Twitter 等网页上进行实时数据抓取。
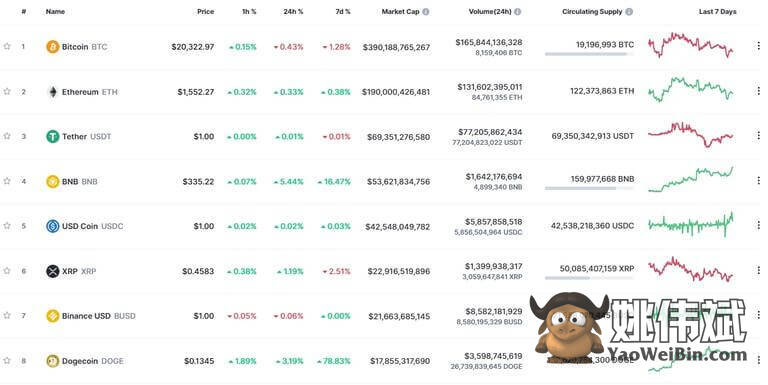
要获取页面上的数据,我们可以解析 HTML 并提取数据,也可以使用前端的实时 API。但是让我们尝试了解数据是如何从 API 呈现到网站的。首先从前端向 API 发送请求,然后 API 使用上表中呈现的 JSON 数据进行响应。
我们要做的是在我们的爬虫中模仿浏览器中发生的事情,这意味着我们将直接从 API 获取数据作为 JSON。为此,我们将通过单击 F12 检查页面,然后选择网络选项卡下的 Fetch/XHR 选项卡。重新加载页面会显示 API 和发送的请求。
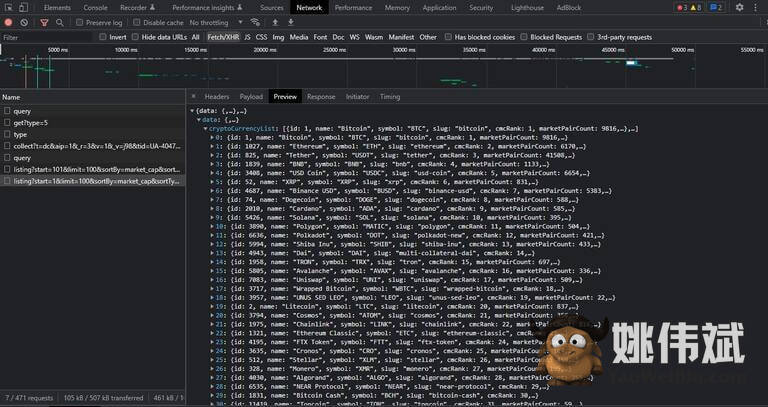
正如你所看到的,我们得到了所有的 JSON 格式的数据,只需右键单击它并复制链接地址。
在本教程中,我们将使用 Python、Pandas 和 Requests。如果还没有安装 Python 库,可以使用pip install requests pandas.
现在到 Python 代码,让我们导入 requests 库并向我们之前获得的地址发送一个简单的请求。
import requests
url = "https://api.coinmarketcap.com/data-api/v3/cryptocurrency/listing?start=1&limit=100&sortBy=market_cap&sortType=desc&convert=USD,BTC,ETH&cryptoType=all&tagType=all&audited=false&aux=ath,atl,high24h,low24h,num_market_pairs,cmc_rank,date_added,max_supply,circulating_supply,total_supply,volume_7d,volume_30d,self_reported_circulating_supply,self_reported_market_cap"
response = requests.request("GET", url)
data = response.json()
发送请求后,让我们使用该.json()方法将数据转换为 JSON。我们还可以添加有效负载和请求标头,以便网站将我们识别为普通网络浏览器而不是机器人。
# ...
data = response.json()
res = []
for p in data["data"]["cryptoCurrencyList"]:
res.append(p)
让我们通过选择 访问包含数据的数组cryptoCurrencyList,它是 的子项data。遍历所有项目后,我们现在可以将结果追加到数组中res。
由于 Pandas Library 同时支持 JSON 和 CSV 文件,我们可以使用它将结果导出为文件.csv。
import pandas as pd
# ...
df = pd.json_normalize(res)
df.to_csv("result.csv")
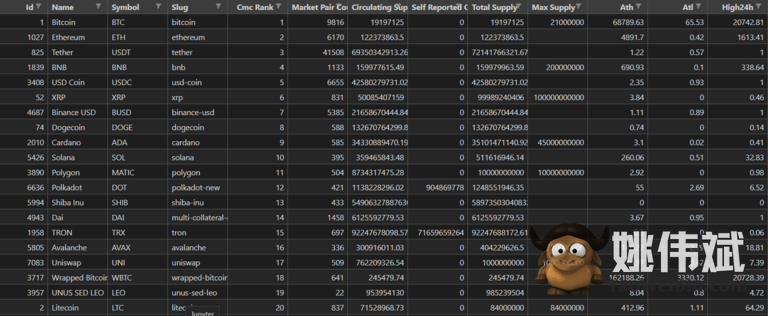
这里我们使用 方法json_normalize,将半结构化的 JSON 数据规范化为一个平面表,然后我们将文件保存为 CSV。
使用 Python 从 Coinmarketcap 抓取的实时数据表。
结论
在本教程中,我们了解了实时抓取的基础知识,然后继续使用 Python 库从 coinmarketcap 抓取一些实时数据。
回顾一下,根据数据的使用情况,正确完成的实时网络抓取对企业和个人都是有益的,但一些限制包括:
- 如果实时爬虫很慢,数据就会过时。
- 防火墙和反机器人有时会让爬虫非常头疼。
- 代理故障可能导致刮板故障。






