

如何创建Pandas DataFrame【含例子】

学习使用pandas DataFrame的基础知识:pandas中的基本数据结构,一个强大的数据操作库。
如果你想开始使用Python进行数据分析,pandas是你应该学习的第一个库之一。从从多个来源导入数据,如CSV文件和数据库,到处理缺失数据并分析它以获取洞察力 – pandas可以让你做到所有这些。
要开始使用pandas分析数据,你应该了解pandas中的基本数据结构:数据帧。
在本教程中,您将学习pandas数据帧的基础知识以及创建数据帧的常用方法。然后,您将学习如何从数据帧中选择行和列以获取子集数据。
为了实现所有这些以及更多内容,让我们开始吧。
安装和导入Pandas
由于pandas是一个第三方数据分析库,所以您应该先安装它。建议在virtual environment中为您的项目安装外部包。
如果您使用Anaconda distribution of Python,您可以使用conda进行包管理。
conda install pandas您还可以使用pip安装pandas:
pip install pandas⚙pandas库需要NumPy作为其依赖项。因此,如果NumPy尚未安装,它也将在安装过程中安装。
安装pandas后,您可以将其导入到您的工作环境中。通常情况下,pandas以别名pd导入:
import pandas as pdPandas中的DataFrame是什么?

pandas中的基本数据结构是数据帧。数据帧是一个带有标签索引和命名列的二维数据数组。数据帧中的每一列称为pandas 系列,共享一个公共索引。
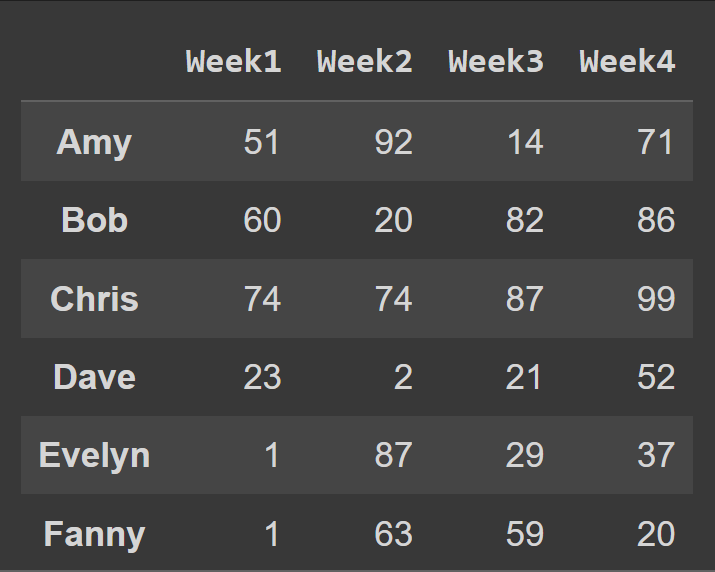
下面是一个示例数据帧,我们将在接下来的几分钟内从头创建。这个数据帧包含六个学生在四个星期内花费的金额数据。

学生的姓名是行标签。列名为'Week1'到'Week4'。请注意,所有列共享相同的行标签集,也称为索引。
如何创建Pandas DataFrame
有几种方法可以创建pandas数据帧。在本教程中,我们将讨论以下方法:
- 从NumPy数组创建数据帧
- 从Python字典创建数据帧
- 通过读取CSV文件创建数据帧
从NumPy数组创建
让我们从一个NumPy array创建一个数据帧。
让我们创建一个形状为(6,4)的数据数组,假设在任何给定的星期,每个学生的花费在0到100美元之间。 NumPy的random模块中的randint()函数返回给定区间[low,high)内的随机整数数组。
import numpy as np
np.random.seed(42)
data = np.random.randint(0,101,(6,4))
print(data)array([[51, 92, 14, 71],
[60, 20, 82, 86],
[74, 74, 87, 99],
[23, 2, 21, 52],
[ 1, 87, 29, 37],
[ 1, 63, 59, 20]])要创建pandas数据帧,您可以使用DataFrame构造函数,并将NumPy数组作为data参数传入,如下所示:
students_df = pd.DataFrame(data=data)现在,我们可以调用内置的type()函数来检查students_df的类型。我们看到它是一个DataFrame对象。
type(students_df)
# pandas.core.frame.DataFrame“`python
print(students_df)
“`
我们可以看到,默认情况下,我们有范围索引,从0到numRows – 1,列标签为0,1,2,…,numCols -1。然而,这会降低可读性。为数据框添加描述性的列名和行标签会有所帮助。
让我们创建两个列表:一个用于存储学生姓名,另一个用于存储列标签。
“`python
students = [‘Amy', ‘Bob', ‘Chris', ‘Dave', ‘Evelyn', ‘Fanny']
cols = [‘Week1', ‘Week2', ‘Week3', ‘Week4']
“`
在调用DataFrame构造函数时,可以分别将index和columns设置为要使用的行标签和列标签的列表。
“`python
students_df = pd.DataFrame(data=data, index=students, columns=cols)
“`
现在我们有了具有描述性行和列标签的students_df数据框。
“`python
print(students_df)
“`
要获取数据框的一些基本信息,例如缺失值和数据类型,可以在数据框对象上调用info()方法。
“`python
students_df.info()
“`
从Python字典创建
您还可以从Python字典创建pandas数据框。
在这里,data_dict是包含学生数据的字典:
- 学生的姓名是键。
- 每个值是学生从第一周到第四周的花费金额的列表。
“`python
data_dict = {}
students = [‘Amy', ‘Bob', ‘Chris', ‘Dave', ‘Evelyn', ‘Fanny']
for student, student_data in zip(students, data):
data_dict[student] = student_data
“`
要从Python字典创建数据框,使用from_dict,如下所示。第一个参数对应于包含数据的字典(data_dict)。默认情况下,键用作数据框的列名。由于我们想将键设置为行标签,所以将orient= 'index'。
“`python
students_df = pd.DataFrame.from_dict(data_dict, orient='index')
print(students_df)
“`
要将列名更改为周数,请将列设置为cols列表:
“`python
students_df = pd.DataFrame.from_dict(data_dict, orient='index', columns=cols)
print(students_df)
“`
从CSV文件读入Pandas数据框
假设学生数据在一个CSV文件中可用。您可以使用read_csv()函数将数据从文件读入pandas数据框中。通用语法为pd.read_csv('file-path'),其中file-path是CSV文件的路径。我们可以将names参数设置为要使用的列名列表。
“`python
students_df = pd.read_csv(‘/content/students.csv', names=cols)
“`
现在我们知道如何创建数据框,让我们学习如何选择行和列。
从Pandas数据框中选择列
有几种内置的方法可用于从数据框中选择行和列。本教程将介绍从数据框中选择列、行和行和列的最常见方法。
选择单个列
要选择单个列,可以使用df_name[col_name],其中col_name是表示列名的字符串。
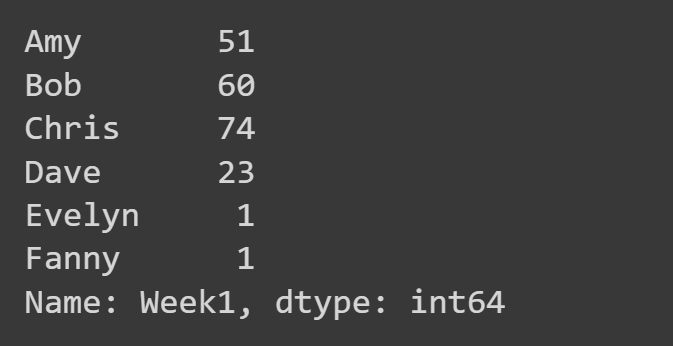
在这里,我们仅选择‘Week1’列。
“`python
week1_df = students_df[‘Week1']
print(week1_df)
“`
选择多个列
要从数据框中选择多个列,请将所有列名的列表传递给select函数。
odd_weeks = students_df[['Week1','Week3']]
print(odd_weeks)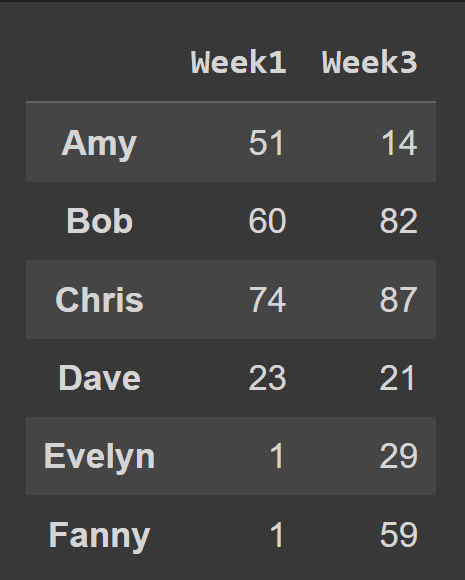
除了这种方法之外,还可以使用iloc()和loc()方法来选择列。我们稍后会编写一个示例。
从Pandas DataFrame选择行

使用iloc()方法
要使用iloc()方法选择行,请将与所有行对应的索引作为列表传递。
在这个例子中,我们选择了奇数索引的行。
odd_index_rows = students_df.iloc[[1,3,5]]
print(odd_index_rows)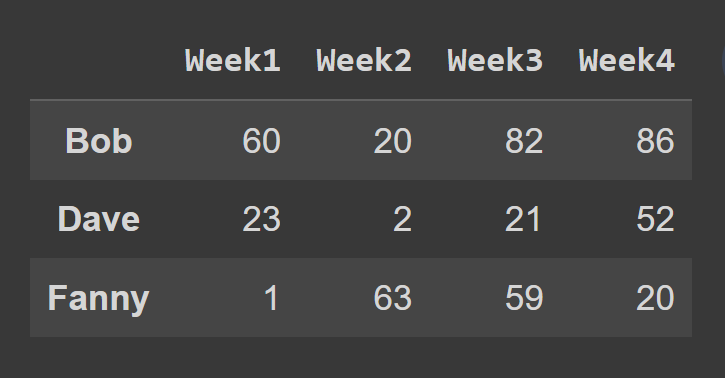
接下来,我们选择数据框的子集,其中包含索引为0到2的行,默认情况下排除终点3。
slice1 = students_df.iloc[0:3]
print(slice1)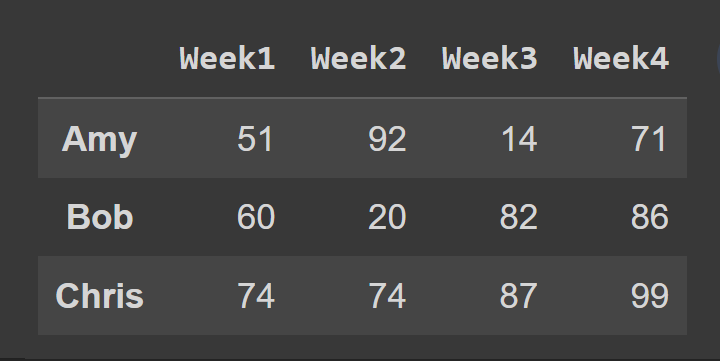
使用loc()方法
要使用loc()方法选择数据框的行,请指定要选择的行对应的标签。
some_rows = students_df.loc[['Bob','Dave','Fanny']]
print(some_rows)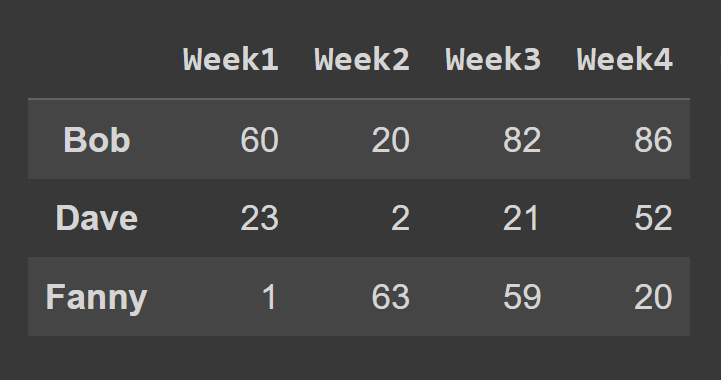
如果数据框的行使用默认范围0, 1, 2,一直到
numRows-1 进行索引,那么使用iloc()和loc()是等价的。
从Pandas DataFrame选择行和列
到目前为止,您已经学会了如何从pandas数据框中选择行或列。但是,有时您可能需要选择一部分行和列的子集。那么如何做呢?您可以使用我们讨论过的iloc()和loc()方法。
例如,在下面的代码片段中,我们选择了索引2和3上的所有行和列。
subset_df1 = students_df.iloc[:,[2,3]]
print(subset_df1)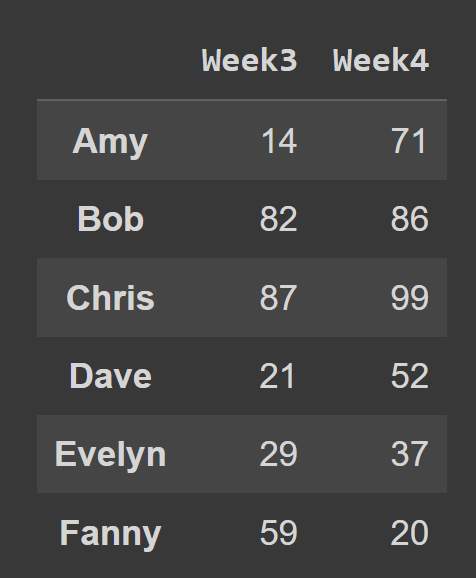
使用start:stop创建从start到stop但不包括stop的切片。所以当您忽略start和stop值时,切片从头开始,并延伸到数据帧的末尾,选择所有行。
使用loc()方法时,必须传入要选择的行和列的标签,如下所示:
subset_df2 = students_df.loc[['Amy','Evelyn'],['Week1','Week3']]
print(subset_df2)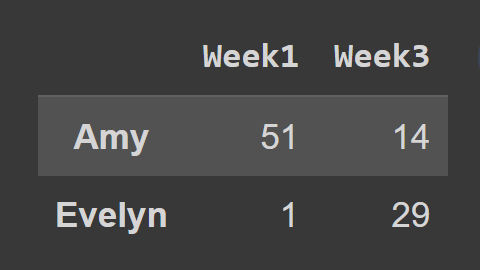
在这里,数据框subset_df2包含了Amy和Evelyn在Week1和Week3的记录。
结论
这里是本教程中你学到的内容的快速回顾:
- 安装pandas后,您可以使用别名
pd导入它。要创建一个pandas数据帧对象,您可以使用pd.DataFrame(data)构造函数,其中data指的是包含数据的N维数组或可迭代对象。您可以通过设置可选的索引和列参数来指定行和索引、列标签。 - 使用
pd.read_csv(文件路径)将文件的内容读入一个数据帧。 - 您可以在数据帧对象上调用
info()方法来获取关于列、缺失值数量、数据类型和数据帧大小的信息。 - 要选择单个列,使用
df_name[列名],要选择多个列,特定列,使用df_name[[col1,col2,...,coln]]。 - 您还可以使用
loc()和iloc()方法选择列和行。 - 虽然
iloc()方法接受要选择的行和列的索引(或索引切片),而loc()方法接受行和列标签。
您可以在此教程中找到使用的示例: this Colab notebook。
接下来,请查看这个单页的清单: collaborative data science notebooks。






