
双轨敏捷:产品经理的介绍
双轨敏捷是一种有效的策略,能够在构建令人惊艳的产品的每一步中同时支持设计和开发团队。
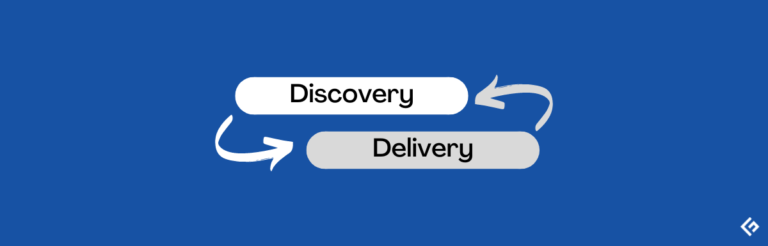
双轨敏捷是一种有效的策略,能够在构建令人惊艳的产品的每一步中同时支持设计和开发团队。
![5 种从 Python 列表中移除重复项的方法 方法一:使用 set() 函数 使用 set() 函数是最简单的方法之一。set() 函数可以将列表中的元素转化为集合,自动去除重复项,然后再将集合转化为列表。 示例代码: “`python my_list = [1, 2, 3, 4, 2, 3, 1] unique_list = list(set(my_list)) print(unique_list) “` 方法二:使用列表推导式 列表推导式是一种简洁的方法,可以根据指定的条件生成一个新的列表。 示例代码: “`python my_list = [1, 2, 3, 4, 2, 3, 1] unique_list = [x for i, x in enumerate(my_list) if x not in my_list[:i]] print(unique_list) “` 方法三:使用 OrderedDict 类 OrderedDict 是 collections 模块中的一个类,它可以按照元素的插入顺序来保留列表中的元素,并且去除重复项。 示例代码: “`python from collections import OrderedDict my_list = [1, 2, 3, 4, 2, 3, 1] unique_list = list(OrderedDict.fromkeys(my_list)) print(unique_list) “` 方法四:使用列表中的 index() 方法 index() 方法可以返回指定元素在列表中的索引值,通过遍历列表并使用 index() 方法来判断元素是否已经存在于列表中,从而实现去除重复项的目的。 示例代码: “`python my_list = [1, 2, 3, 4, 2, 3, 1] unique_list = [] for x in my_list: if x not in unique_list: unique_list.append(x) print(unique_list) “` 方法五:使用 filter() 函数和 lambda 表达式 filter() 函数可以根据指定的条件过滤列表中的元素,结合 lambda 表达式可以很方便地去除重复项。 示例代码: “`python my_list = [1, 2, 3, 4, 2, 3, 1] unique_list = list(filter(lambda x: x not in unique_list, my_list)) print(unique_list) “`](https://yaoweibin.cn/wp-content/uploads/2023/08/20230830115449-64ef2e092f70b-768x246.webp)
在本教程中,您将学习几种方法来从Python列表中删除重复的项,附带代码示例。

许多开发者,尤其是初学者,选择使用类似所见即所得的可视化HTML编辑器进行编码,因为它们易于使用并能与网站集成。

当我们提到“无服务器”计算时,很多人会认为在这个模型中没有服务器来促进代码执行和其他开发任务。实际上,这是不准确的。

信用卡盗刷是一种欺诈行为,盗刷者会在真实的卡片读取器上安装一个小设备来获取您的信用卡信息。这些设备可以

微服务架构提供了灵活性、可扩展性和能够在不影响其他部分的情况下修改、添加或删除软件组件的能力。

development stage, it is crucial to implement security measures to protect sensitive data and prevent unauthorized access.
在开发过程中采取措施来加强和保护您的网站后端安全。小企业、银行和许多行业都依赖于网络应用程序。从开发阶段开始,实施安全措施以保护敏感数据并防止未经授权的访问至关重要。

您是否正在寻找最好的住宅代理服务…

您是否正在寻找有关如何向 Win…

Cloudflare 错误 10…
