

5个原生AWS服务可以构建端到端无服务器平台

构建一个自动化软件系统意味着多年来需设置多个具有专用CPU配置、内存、存储和其他资源的服务器。然后,组建了一个管理员团队来管理这些系统。接着,开发团队接手基础架构并开始创建连接服务器的流程。
这个过程可能很复杂,因为它涉及到许多不同的团队共同努力达成共同目标。这些利益冲突可能会成为一个问题。
这也可能会非常昂贵。这要求您在您的payroll上拥有管理员。服务器持续运行,即使不使用也会消耗资源。
为了保持长期最佳性能,您需要一个自动缩放的解决方案,可以自动缩放服务器资源。

云平台有一个优点:它允许您创建一个没有服务器群集设置的端到端架构。从管理的角度来看,无需维护任何东西。
对于初创公司和项目的最小可行性产品(MVP)阶段来说,这是一个具有成本效益的选择。如果很难预测未来的生产负载和用户活动,这是一个很好的起点。这是确定群集服务器配置的挑战所在。
通过无服务器云服务的自动化过程是无服务器架构的独特之处。它连接服务并产生与传统群集服务器类似的结果。
以下是使用仅原生AWS服务构建此类架构的示例。
选择服务的无服务器流程
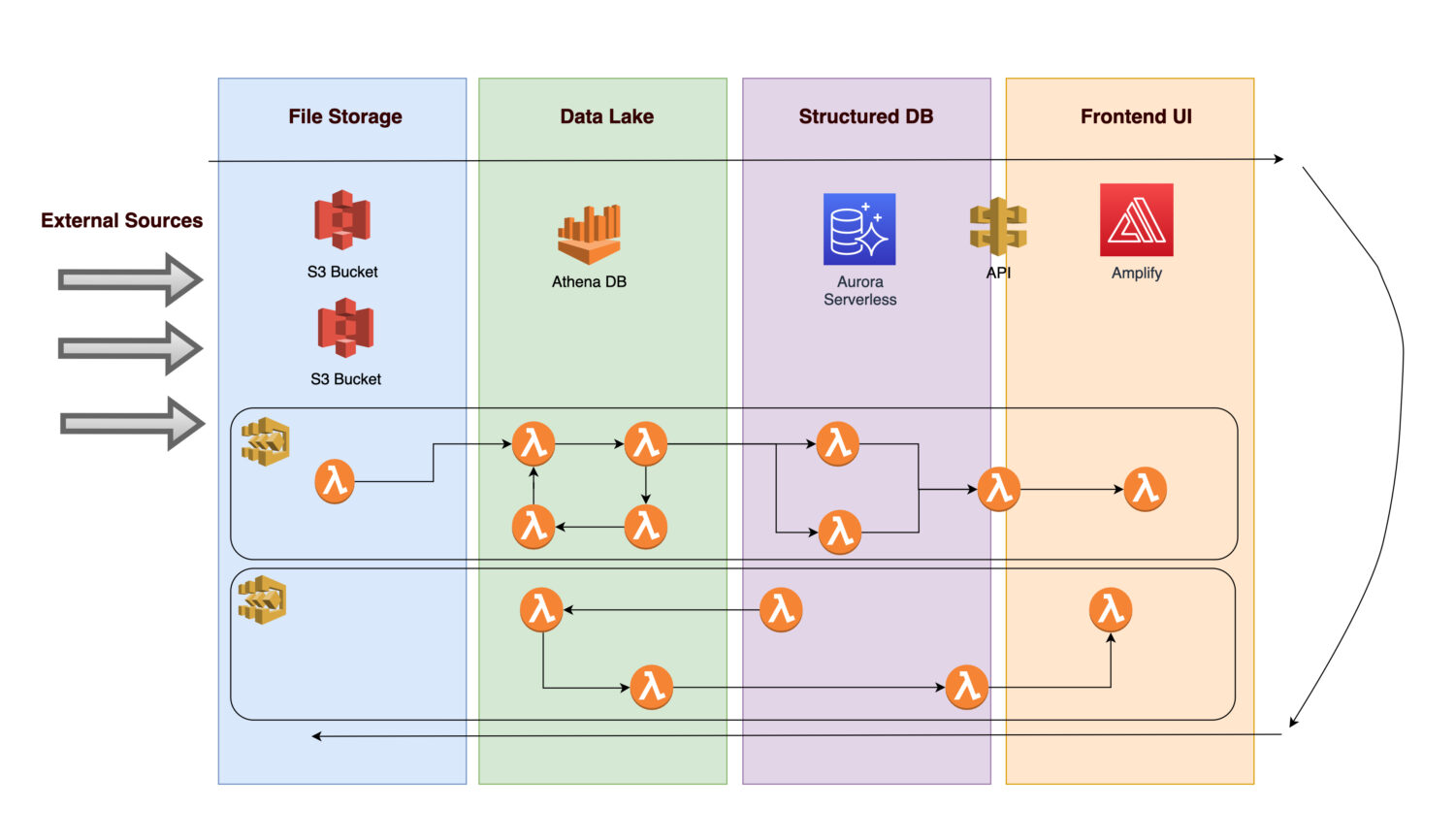
假设您想要创建一个平台,用于收集某些具体资产基础设施的各种数据和图片(或照片)(可以是任何制造或公用事业资产)。
- 为了将来的分析成为可能,需要首先摄取传入的数据。
- 在应用业务规则后,后端过程将计算结果保存为规范化信息存储在关系型数据库中。
- 一个应用前端显示规范化的干净数据,允许用户查看结果。
让我们看看这个架构可能包含哪些组件。
AWS S3存储桶

Amazon S3存储桶是在云中存储文件或图片的好方法。S3存储桶的存储价格非常低。而且,引入S3存储桶生命周期策略进一步降低了这个价格。
这样的策略将自动将旧文件移动到不同类别的S3存储桶中,例如归档或深度归档访问。这些类别的访问时间速度也有所不同,但对于旧数据来说,这不是一个问题。它主要用于在紧急事件发生时访问已归档的数据,而不是用于标准操作需求。
- 您可以将数据组织到子文件夹中。
- 您应该设置适当的权限限制。
- 为存储桶添加标签,以便于识别,并可能在动态S3存储桶策略中使用。
- 存储桶是按设计无服务器的。它只是一个存储空间,用于存储数据。
S3存储桶按设计是无服务器的。它只是一个存储空间,用于存储数据。
AWS Athena数据库

Athena使创建AWS基本数据湖变得轻松。它是一个无需服务器的数据库,使用S3存储桶存储其数据。数据组织由结构化文件格式(例如parquet或逗号分隔值(CSV)文件)进行维护。S3存储桶保存文件,Athena在进程从数据库中选择数据时引用它们。
请注意,Athena不支持其他被视为标准的各种功能,例如更新语句。这就是为什么你需要将Athena视为一个非常简单的选项。
然而,它支持索引和分区。它也可以很容易地水平扩展,只需向基础架构添加新的存储桶即可。对于简单但功能齐全的数据湖创建,这在大多数情况下仍然足够。
为了良好的性能,选择最佳的数据设计并注重未来的使用是必不可少的。非常清楚地了解您希望如何选择数据是至关重要的。在已存在并且已经填充了大量数据的情况下重新创建表格是非常困难的。
如果您希望创建一个简单且易于随时间水平扩展的不可变数据池,Athena DB是一个很好的选择并符合您的目标。
AWS Aurora数据库
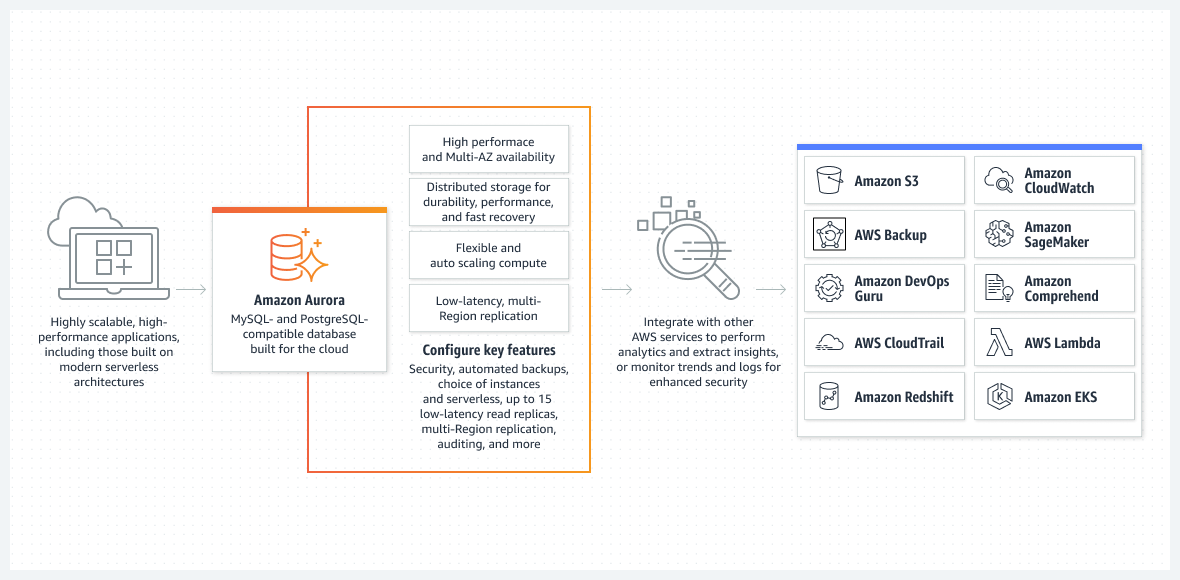
Athena DB擅长存储未经整理的数据。毕竟,这就是您希望存储原始内容以最大限度地提高其将来重用性的方式。然而,它在向前端应用程序提供选择结果时速度较慢。
从易于执行设置的角度来看,Aurora数据库在无服务器模式下运行是最佳选择之一。
Aurora远非是一个基本数据库。它是AWS中最先进的本地关系型数据库解决方案之一。它也是一个高度复杂的本地关系型数据库解决方案,每次发布都有所改进。
Aurora之所以独特,是因为它可以在无服务器模式下运行,这使其与其他关系型服务区别开来。以下是该模式的工作原理:
- 使用AWS控制台配置Aurora集群。您需要指定标准CPU和RAM级别以及自动缩放功能的最大间隔。这将影响Aurora集群可以动态添加或删除的性能。根据数据库的当前使用情况,AWS决定进行扩展或缩小。
- 除非用户或进程发起真实请求,否则Aurora集群不会启动。例如,当定期批处理开始时。或者如果应用程序执行后端API调用以从数据库检索数据。数据库将自动打开,并在请求处理完成后保持活动状态一段预定的时间。
- 如果数据库中没有更多的工作,Aurora集群将自动关闭。
再强调一次,无服务器Aurora DB只在需要进行真实工作时运行。如果没有处理任何工作,自动启动的集群将再次关闭。你所付费的是实际工作,而不是空闲时间。
无服务器Aurora由AWS完全管理,不需要管理员。
AWS Amplify
Amplify提供了一个无服务器平台,用于快速部署使用JavaScript和React库创建的前端应用程序。无需设置集群服务器。直接使用AWS控制台部署代码,或使用自动化的DevOps流水线。
您可以调用后端API以访问存储在数据库中的数据。这些调用允许您在前端应用程序中访问实际数据。主要的后端性能优化应该由团队完成。如果您在API调用中直接设计有效的选择语句,甚至可以进一步减少UI中慢响应的可能性。
AWS Step Functions

即使系统的所有主要组件都是无服务器的,也不能保证完全无服务器的架构。只有组件之间的所有批处理过程都是无服务器的才可能实现这一点。
AWS Step functions提供了AWS云上的最佳解决方案。一系列相连的AWS Lambda函数组成了步骤函数。这些函数创建了一个具有清晰起止状态的流程图。Lambda函数通常由Python或其他编程语言编写,它们是可执行的代码片段,可以处理所需的任何操作。
以下是一个执行步骤函数的示例:
- AWS在新文件进入S3文件夹时会自动触发一个Lambda函数。在解析文件后,Lambda将其加载到Athena中。Lambda在关闭之前将其结果存储在S3存储桶中的CSV格式文件(或跟踪表中的数据库)中。
- 接下来的Lambda将使用这个结果执行下一步操作。这可能包括调用一个链接并将新数据的子集转换为规范化表格。最后一步可以是将数据加载到Aurora数据库。
- 步骤函数将这些Lambda函数链接在一起形成一个批处理流程。甚至可以在根步骤函数的步骤中执行另一个步骤函数。通过这种方式,可以覆盖许多场景。
这种无服务器流程有一个主要缺点:每个Lambda函数最长只能运行15分钟。因此,将流程分成较小的Lambda函数可以减少这个问题。
可以在一个步骤中同时调用多个Lambda函数,这基本上意味着并行执行具有多个Lambda的步骤。只需等待所有并行Lambda处理完成,然后继续执行下一个Lambda处理。
最后的话
无服务器架构提供了一个独特的机会来创建一个覆盖整个系统环境的云平台。这个平台具有横向可扩展性,并且在此过程中的运营成本很低。
对于预算有限的项目来说,这是一个完美的解决方案。特别是当没有人了解生产负载的实际情况时,它是一个很好的探索选项。尤其是在成功吸引所有用户之后,项目团队仍然可以获取整个系统运行情况的总体视图。您可以获得所有这些好处,而无需接受任何妥协。
对于所有涉及高CPU使用率的情况,这种覆盖范围可能不足够。然而,AWS云在无服务器用例方面不断发展。在决定下一个AWS云项目的无服务器选项之前,进行彻底的研究通常是一个好主意。
接下来,查看最佳的链接。
![10 Python数据结构[例子解释]](https://yaoweibin.cn/wp-content/uploads/2023/09/20230912052235-64fff59bd0062-768x246.webp)





