

最佳JavaScript和NodeJS网络爬虫库
JavaScript 网络抓取库现在非常流行。虽然您可以使用任何编程语言进行网络抓取,但 JavaScript 在这方面占有重要地位。这有几个原因。一是 JavaScript 在开发人员中非常普遍,因为他们发现它是一种非常易于使用的语言。
此外,网络抓取涉及网站的客户端,遍历 DOM 元素。由于 Javascript 是一种客户端语言,因此它是一种比其他语言更好的网络抓取工具。JavaScript 也是一种非常用户友好的语言,可以与任何后端编程语言一起使用。
本文将讨论用于网络抓取的最佳 JavaScript 网络抓取库或 Node Js 库。我们将为每个库提供一个演示,以便您可以比较每个库完成相同抓取任务所需的工作量。
我们为演示选择了dev.to网站。在此URL中,您可以找到我们将抓取的标签列表。
如果查看页面源码,可以看到网页的DOM元素如下。

crayons-tag我们必须在带有该类的 div 元素内抓取带有类的标签的 innerHTML tag-card。让我们看看如何使用每个库来抓取此页面,以及它们的优缺点。
1.jQuery
jQuery是最流行的 JavaScript 库之一,可以轻松地操作 HTML 内容。因此,它也是一个很棒的 JS 网络抓取库。开始使用 jQuery 非常简单。您所要做的就是在网页上添加对 jQuery 库的引用。但是,与本文中提到的其他库不同,jQuery 不是节点库。所以它只适用于客户端,换句话说,适用于浏览器。
让我们用 jQuery 抓取 dev.to 标签。您的代码将如下所示。
<DOCTYPE HTML>
<head></head>
<body>
<!-- Scraped dev.to tags will be displayed here -->
<div class="demo-container"></div>
<!-- Specifying the jQuery library -->
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
<script>
$(document).ready(function() {
// Go to the dev.to tags page and get the HTML code
$.get("https://dev.to/tags", (html) => {
// Find elements with crayons-tag class inside the HTML page received
[...$(html).find(".crayons-tag")].forEach((el) => {
// Get the text(tag name) inside of each element with crayons-tag class
const text = $(el).text();
// Append each tag to a list
$("div.demo-container").append("<li>"+text+"</li>");
})
})
});
</script>
</body>
</HTML>
现在打开 HTML 文件以查看结果。恭喜!您已成功抓取标签列表。

使用 jQuery 作为 Javascript 爬虫库比使用任何其他库都容易。您无需安装任何东西。此外,许多开发人员已经熟悉 jQuery,因为它广泛用于处理客户端 JavaScript。因此,对于使用 jQuery 进行网页抓取的许多开发人员来说,没有什么新东西需要学习。
然而,主要缺点是您不能使用 jQuery 抓取某些站点。原因是 jQuery 发送受同源策略约束的 Ajax 请求。这意味着您无法使用 jQuery 请求从不同的域检索数据。总的来说,jQuery 适用于快速演示,但不适用于实际情况。
2.ZenRows
ZenRows API 是使用 NodeJS 的网络抓取框架的最佳选择之一。大多数爬虫在爬取大量数据时面临的最大问题是被网站屏蔽。Zenrows 提供了一个巨大的轮换代理池来解决这个问题,这样您就可以绕过遇到的任何阻塞。
此外,ZenRows 提供住宅代理,允许您以真实用户身份浏览。此 API 还有助于防止地理定位块,因为它提供了许多代理。通过使用高级代理,用户可以从不同的地理位置访问网站。
此外,ZenRows 可帮助您绕过反机器人程序和验证码。因此,您可以轻松地抓取网页中的 HTML 表单。
虽然 ZenRows 适用于几乎所有流行的编程语言,但使用 NodeJS 非常简单。首先,注册并免费获取您的API 密钥。注册后,您将看到以下界面。
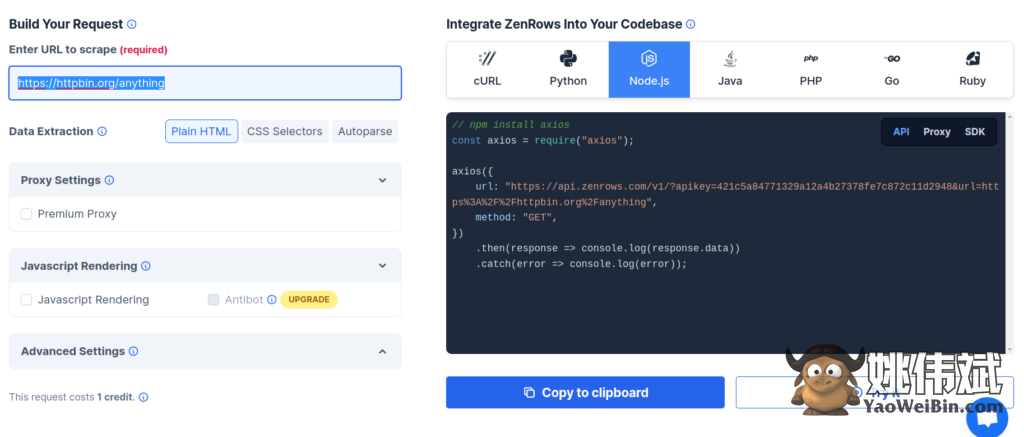
使用此接口比使用其他编程库要容易得多。您只需在输入字段中填写数据,ZenRows 就会为您编写必要的代码。
在相关字段中添加URL和CSS 选择器,如下所示。
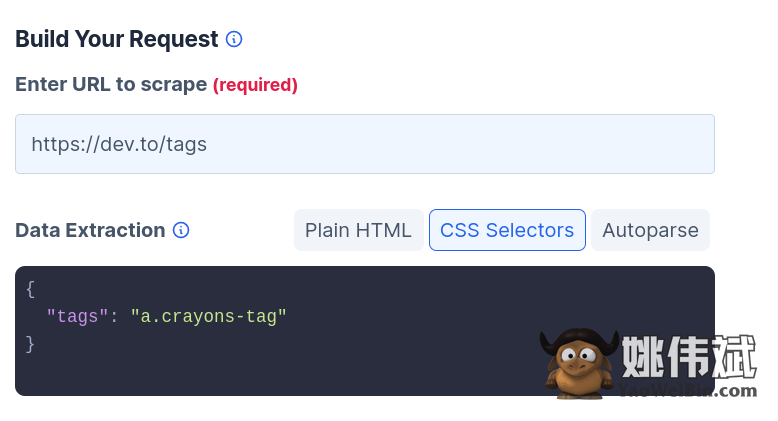
然后在右侧菜单中选择任意一种编程语言,选择SDK,如下图。
代码将根据您选择的编程语言而改变。

点击Try it,您将得到如下截图所示的结果
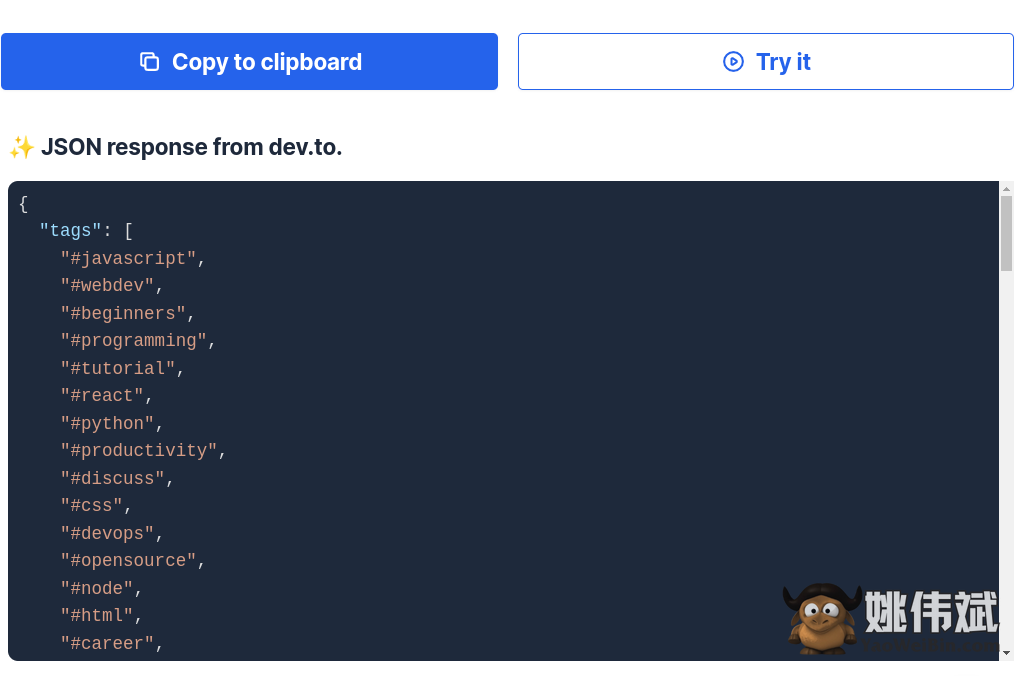
如果需要,您可以在本地计算机上运行此代码。您所要做的就是复制此代码并在您喜欢的 IDE 或文本编辑器(如 VS Code)上运行它。但是,请记住在使用以下命令运行代码之前安装 ZenRows。
npm install zenrows
这是一个基本的抓取场景。如果您想尝试更复杂的操作,ZenRows 还可以通过提供更高级的选项来帮助他们。
现在,让我们将 ZenRows 与其他最好的 JavaScript 库进行比较。
3. Axios 和 Cheerio
Axios是最流行的 JavaScript 网络抓取库之一,它可以发出 HTTP 请求。发送 HTTP 请求是抓取过程的一部分。Cheerio 是一个 Node.js 网络爬虫框架,可以与 Axios 完美配合以发送 HTTP 请求。
Cheerio是轻松遍历网页的绝佳工具。因此,我们将 Axios 和 Cheerio 的组合作为我们文章中的第三种解决方案。现在,让我们看看如何使用这两个库抓取 dev.to 标签。
首先,您必须使用以下命令安装这两个工具。
npm install axios cheerio
以下代码将从页面中抓取标签列表dev.to/tags。
const axios = require("axios");
const cheerio = require("cheerio");
const fetchTitles = async () => {
try {
// Go to the dev.to tags page
const response = await axios.get("https://dev.to/tags");
// Get the HTML code of the webpage
const html = response.data;
const $ = cheerio.load(html);
// Create tags array to store tags
const tags = [];
// Find all elements with crayons-tag class, find their innerText and add them to the tags array
$("a.crayons-tag").each((_idx, el) => tags.push($(el).text()));
return tags;
} catch (error) {
throw error;
}
};
// Print all tags in the console
fetchTitles().then(titles => console.log(titles));
您将获得如下所示的输出。
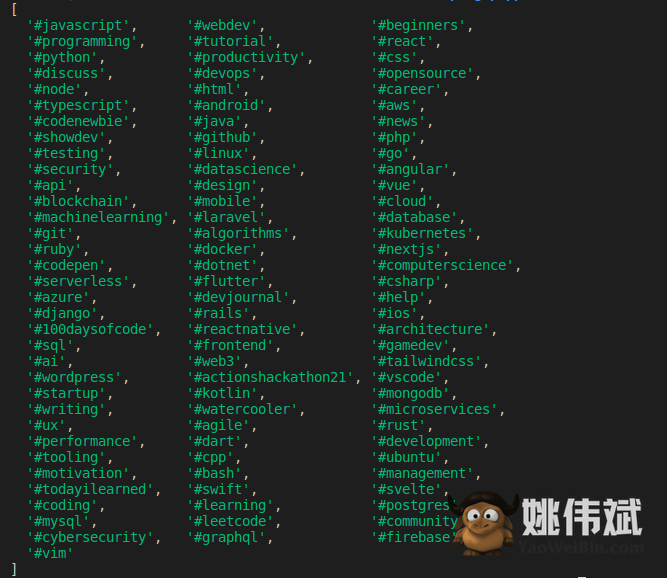
我们列表中接下来的两个解决方案是 Puppeteer 和 Playwright。正如您将了解到的,它们都使用无头浏览器。无头浏览器很重,因为它们必须启动一个真正的浏览器。因此,Axios 和 Cheerio 的这种组合在性能上是非常快的。
主要缺点是您无法抓取动态内容。另一个缺点是你必须学会使用两个库。
我们列表中的下一个是 Node js 抓取库。
4.Puppeteer
Puppeteer是最流行的用于测试自动化的NodeJS 库之一。它提供了一个高级 API,可以通过开发工具协议自动执行大多数 Chrome 浏览器任务。您还可以将 Puppeteer 用作 JavaScript 网络爬虫框架,因为它可以自动执行浏览器任务。最重要的是,Puppeteer 可用作无头浏览器。如果我们想要抓取动态 Ajax 页面或嵌套在 JS 元素中的数据,无头浏览器是最佳选择。
让我们看看如何使用 Puppeteer 抓取 dev.to 站点中的标签。
首先,使用以下命令安装 Puppeteer Nodejs 网络抓取库。
npm install puppeteer
然后您可以使用以下代码抓取标签列表。
const puppeteer = require("puppeteer");
async function tutorial() {
try {
// Specify the URL of the dev.to tags web page
const URL = "https://dev.to/tags";
// Launch the headless browser
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Go to the webpage
await page.goto(URL);
// Perform a function within the given webpage context
const data = await page.evaluate(() => {
const results = [];
// Select all elements with crayons-tag class
const items = document.querySelectorAll(".crayons-tag");
items.forEach(item => {
// Get innerText of each element selected and add it to the array
results.push(item.innerText);
});
return results;
});
// Print the result and close the browser
console.log(data);
await browser.close();
} catch (error) {
console.error(error);
}
}
tutorial();
您的输出将类似于下面的屏幕截图。
使用 Puppeteer Javascript 抓取框架进行网页抓取的步骤非常简单明了。然而,如您所见,Puppeteer 需要比 jQuery 和 ZenRows更长的代码。
与其他流行的 JS 库相比,Puppeteer 最好的一点是它允许您轻松访问任何动态网站的数据。它还使您能够浏览网页的分页或任何其他特殊页面结构。
Puppeteer 作为 JavaScript 抓取库的主要缺点是它需要比其他库更多的技术知识。此外,当你使用 Puppeteer 时,你需要更昂贵的基础设施,因为它需要启动浏览器,不像 ZenRows,它会为你做这件事。最后,从上面的代码可以看出,即使是一个小任务,你也要写很多行代码。
5.Playwright
Playwright也是一个Node JS 网络抓取库。它主要是为测试而构建的。然而,它自动执行浏览器任务的能力也使其成为网络抓取的理想选择。Playwright 节点抓取库还附带无头浏览器支持。
如您所见,Playwright 是微软推出的一款产品,旨在与 Google 的 Puppeteer 竞争。Playwright 优于 Puppeteer 的是它的跨浏览器支持。它包括用于 Chrome 和 Edge 的 Chromium、用于 Firefox 的 Gecko 和用于 Safari 的 Webkit。Puppeteer和Playwright在表演方面几乎是一样的。
运行以下命令来安装 Playwright。
npm install playwright
然后我们可以使用以下代码抓取标签列表。
const playwright = require("playwright");
async function main() {
// Launch the headless browser
const browser = await playwright.chromium.launch({
headless: true,
});
// Go to the dev.to/tags page
const page = await browser.newPage();
await page.goto("https://dev.to/tags");
// Find all elements with crayons-tag class, get their innerText and add them to the data array
const data = [];
const tags = await page.$$("div.tag-card");
for (let tag of tags) {
const title = await tag.$eval(".crayons-tag", el => el.textContent);
data.push(title);
}
// Print the result
console.log(data);
await browser.close();
}
main();
该代码非常不言自明。输出将如下所示。
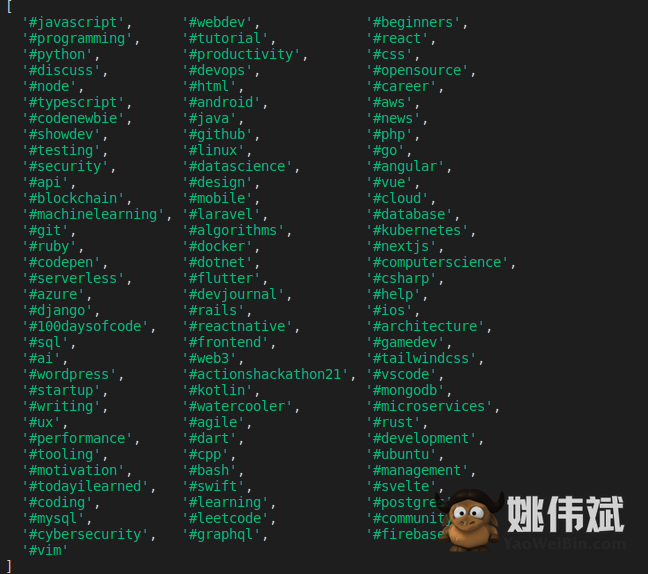
Playwright 相对于其他顶级 JS 库的缺点是它仍然是一个新库。许多开发人员还没有意识到这一点。因此,与本文中提到的其他工具相比,支持可能是最少的。此外,如果您不是一个精明的开发人员,您可能无法将它用于复杂的场景。
哪个 JavaScript 网络抓取库最适合你?
这个问题的答案此刻就有些明显了。您可以自由使用很酷的 JavaScript 库。但是,您需要先学习它们。此外,您必须付出一些努力来完成一些事情。最大的问题是找到解决方法来防止您的 IP 地址被阻止或绕过验证码。






