

最佳Java 网页爬虫库
什么是最好的 Java 网络抓取库?有这么多的选择,我们的审查将明确要考虑的内容以及您应该为您的用例实施哪些工具。此外,您将看到每一个的真实示例。
1.ZenRows
ZenRows是一个一体化库,允许开发人员通过单个 API 请求抓取数据。它绕过所有反抓取保护(验证码、蜜罐陷阱……)并为您节省代理成本。
👍优点:
- 易于使用:ZenRows 的 API 简单直观,允许任何技能水平的开发人员快速设置基本集成。
- 有据可查。
- 灵活且可扩展:您将获得 1,000 个免费 API 积分。之后,您只需为所需的和成功的请求付费。
- 可靠且安全:ZenRows 确保 99.9% 的正常运行时间并提供实时聊天支持。
👎缺点:
- 数据解析:您需要一个补充库(如 Jsoup)来执行 HTML 解析。
现在,让我们看看它是如何工作的。注册以进入 Request Builder 页面。然后,从仪表板中选择 Java。
接下来,输入目标 URL。对于这个例子,我们将使用ScrapeMe。此外,选择CSS Selector并添加产品类别名称,即.woocommerce-loop-product__title.
这将导致您在右侧看到的代码:
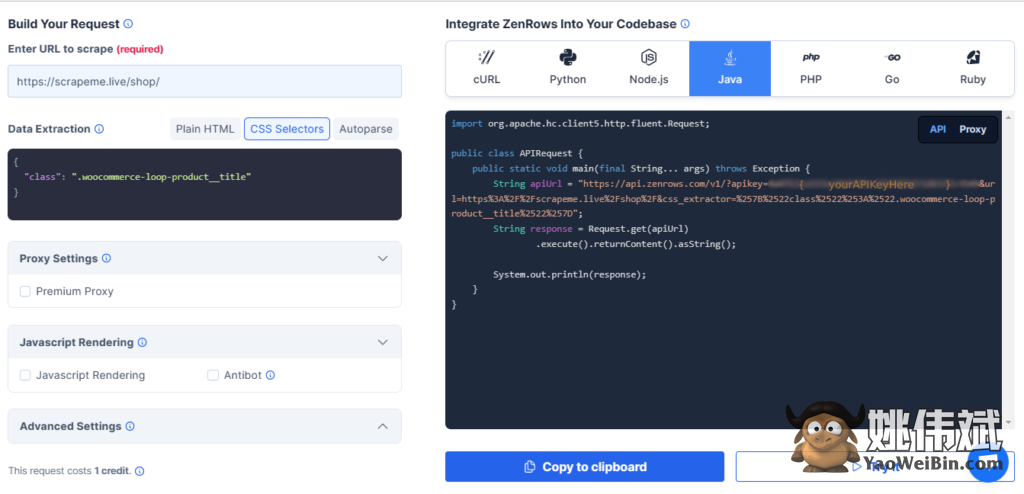
剩下要做的就是将此代码粘贴到您的文件中:
import org.apache.hc.client5.http.fluent.Request;
public class APIRequest {
public static void main(final String... args) throws Exception {
String apiUrl = "https://api.zenrows.com/v1/?apikey={ yourApiKeyHere }&url=https%3A%2F%2Fscrapeme.live%2Fshop%2F&css_extractor=%257B%2522class%2522%253A%2522.woocommerce-loop-product__title%2522%257D";
String response = Request.get(apiUrl)
.execute().returnContent().asString();
System.out.println(response);
}
}
结果将是带有woocommerce-loop-product__title类标题的产品项名称列表。

您现在已成功抓取所有项目名称。
2. Selenium
Selenium是一个流行的库,用于从动态网页(具有由 JavaScript 生成的元素的网页)中提取数据并像人一样进行交互(单击按钮、向下滚动等)。使用几行代码,您可以轻松创建一个脚本来控制浏览器并提取页面上的任何所需元素。
👍优点:
- 开源且免费使用。
- 广泛支持并提供良好的文档。
- 它允许动态抓取。
- 支持多种语言,包括 Java、C#、Perl 和 Python。
👎缺点:
- Selenium 是一个维护繁重的框架,难以扩展。
让我们测试一下!以下是如何使用 Selenium 从网页中抓取数据:
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class ExampleTitleScraper {
public static void main(String[] args) {
// Setting up the web driver
System.setProperty("webdriver.chrome.driver", "path/to/chromedriver");
WebDriver driver = new ChromeDriver();
// Navigating to the website
driver.get("https://www.example.com/");
// Scraping the title of the website
String title = driver.getTitle();
System.out.println("Website title: " + title);
// Closing the web driver
driver.close();
}
}
该脚本的输出应为“网站标题:示例域”
您现在知道如何使用 Selenium 提取有价值的信息了。
3. Gecco
Gecco是另一个高效的开源选项,适用于那些想要提取 Web 数据的人。该框架建立在Apache HttpClient库之上,它使用注释来定义请求过程。这有助于开发人员毫不费力地构建简单和复杂的爬虫。
一旦设置了 Gecco 类,您就可以轻松地一次爬取多个域,为身份验证要求注入定制的标头,甚至可以使用对象模型进行 HTML 页面的异步处理。
👍优点:
- 由于其高效的数据处理系统和多线程技术,每秒能够抓取数百个页面。
- 没有订阅费,因为这是一个开源 Java 网络爬虫库。
👎缺点:
- 与其他库(如 Scrapy 或 Apache Nutch)相比,自定义选项有限。
- 它不支持动态抓取。
让我们用 Gecco 做一些小型抓取吧!下面的脚本提取Angular主页的 h1 。
import com.geccocrawler.gecco.GeccoEngine;
import com.geccocrawler.gecco.annotation.*;
import com.geccocrawler.gecco.spider.HtmlBean;
@Gecco(matchUrl="https://angular.io", pipelines="consolePipeline")
public class Main implements HtmlBean {
@Text
@HtmlField(cssPath="h1") // css selectors
private String title;
public String getTitle() {
System.out.println("The title is: " + title);
return title;
}
public void setTitle(String title) {
this.title = title;
}
public static void main(String[] args) {
GeccoEngine.create() // Create an instance of GeccoEngine
.classpath("com.geccosample.gecco") // Specify the package where the HtmlBeans are located
.start("https://angular.io") // Start Gecco crawler engine
.thread(1)
.run(); // Run the engine and start crawling
}
}
这是我们的输出:
The title is: Deliver web apps with confidence.
4.Jsoup
Jsoup是一个开源的 Java 网络爬虫库,设计为HTML 解析器,用于从 HTML 和 XML 文档中提取和操作数据。它提供了一个非常方便的 API 用于抓取,使用最好的 DOM、CSS 和类似 jQuery 的方法。该框架支持操作属性、清理 HTML 标记,甚至将 HTML 转换为纯文本。
此外,Jsoup 实现了WHATWG HTML5规范,并将 HTML 解析为与现代浏览器相同的 DOM。
👍优点:
- Jsoup 提供了广泛的方法选择来帮助创建强大的脚本,允许开发人员以不同的方式与网站交互。
- 该库非常小(~800kb),因此它可以很容易地集成到其他项目中,同时对现有资源和文件的开销很小。
👎缺点:
- Jsoup 严重依赖外部第三方库,例如Apache Commons Codecs。
- 抓取期间节点遍历的性能滞后。对于具有多个需要遍历的节点的较大文档,此问题更为明显。
- 它不支持动态抓取。
让我们看一个如何使用 Jsoup 从Vue Storefront的主页检索标题的示例:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Main {
public static void main(String[] args) throws Exception{
// Request the entire page from the URL
// define a String variable and scrape the website with jsoup for product title and price
String url = "https://demo.vuestorefront.io/";
Document doc = Jsoup.connect(url).get();
String bannerTitle = doc.select("span.sf-banner__title").text();
// Print out output in console
System.out.println("Banner: " + bannerTitle);
}
}
输出是这样的:
Banner: DECORATE YOUR HOME WITH CAREFULLY CRAFTED ACCESSORIES
5. Jaunt
Jaunt是一个轻量级的快速抓取库,支持 HTML 和 XML 解析。它还包括一个无头浏览器组件,用于抓取静态网页。
它提供了对 HTML 文档的更轻松访问,并使开发人员能够使用类似于 jQuery 或 XPath 选择器的简单方法和语法来访问、搜索、阅读和修改网站内容。
👍优点:
- 该库被设计为轻量级且易于理解,这意味着它不需要任何特殊技能或高级编码知识。
- 它比大多数 Java 网络爬虫框架更快,因为它使用底层 JS 代码来实现其功能,从而能够以更少的步骤执行某些任务。
- Jaunt 提供大量文档、不断发展的社区论坛和常见问题解答,以帮助您解决任何不可预见的问题。
👎缺点:
- 无法抓取动态网页。
- 它不容易定制。
现在让我们尝试抓取 Vue Storefront 的标题。
import com.jaunt.*;
public class Scraper {
public static void main(String[] args) {
try {
UserAgent userAgent = new UserAgent();
userAgent.visit("https://demo.vuestorefront.io/");
String title = userAgent.doc.getTitle();
System.out.println("Title of the page: " + title);
} catch (JauntException e) {
System.err.println(e);
}
}
}
我们的输出如下所示:
Title of the page: Vue Storefront | Vue Storefront Demo
6.Jauntium
Jauntium是一个开源库,可让您自动化 Web 浏览器。它是Jaunt 和 Selenium 的组合,旨在克服各自的不足。
凭借其维护良好且简单的 API,Jauntium 可用于抓取各种类型和规模的网站,包括动态单页应用程序。它还支持自动页面导航和有助于解析复杂数据结构的自定义数据解析器。
👍优点:
- Selenium 的所有功能都可以自动化任何现代浏览器。
- 用户友好(类似 Jaunt 的)架构。
- 它使您的程序能够处理表格和表单,而不必过多依赖 XPath 或 CSS 选择器。
- 流畅的 DOM 导航和搜索链接。
👎缺点:
- 与 Jaunt 相比相对较慢,因为它加载整个页面内容,包括 JavaScript 内容。
- 它严重依赖于其他库,如 Selenium 和 Jaunt。
让我们使用 Jauntium从商店中获取第一本书:
import org.openqa.selenium.chrome.ChromeDriver;
import com.jauntium.Browser;
import com.jauntium.Element;
public class ScrapeExample {
public static void main(String[] args) throws Exception {
System.setProperty("webdriver.chrome.driver", "path/to/chromedriver.exe");
Browser browser = new Browser(new ChromeDriver());
// Visit the webpage containing book
browser.visit("http://books.toscrape.com/");
// Identify the div that contains all the book elements
Element containerDiv = js.findFirst("<div class=row>");
// Locate the element for first book
Element firstBook = containerDiv.findFirst("<article class=product_pod>");
// Extract name and price of the first book
String name = firstBook.findFirst("<h3>").getTextContent();
String price = firstBook.findFirst("<p class=price_color>").getTextContent();
System.out.println("The name of the first book is: " + name);
System.out.println("The price of the first book is: " + price);
}
}
找到下面的输出:
The name of the first book is: A Light in the ... The price of the first book is: £51.77
7. WebMagic
WebMagic是一个流行的 Java 网络抓取库,它为开发人员提供了一种可扩展且快速的方法来提取结构化信息。通过自动调度等可插拔组件,支持分布式爬取和数据处理。
该框架的主要目标是使网络抓取工具简单直观。它支持广度优先和深度优先搜索算法,允许用户创建具有多种爬行策略的蜘蛛。
👍优点:
- WebMagic 有一个简单的 API,使所有技能水平的专业人士都可以使用它。
- 旨在高效和快速。
- 能够从多个页面同时处理和提取大量数据。
- 这个 Java 抓取库提供内置支持来处理常见的 Web 抓取任务,例如登录和处理 cookie 或重定向。
👎缺点:
- 它不是浏览器自动化工具,这意味着它不能像人类那样与网页交互。
- 该库不执行 JavaScript,只能抓取页面的初始 HTML。
下面是一个如何使用 WebMagic 抓取 an 的示例h1:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class Main implements PageProcessor{
Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public void process(Page page){
// Extract the footer link
String footer = page.getHtml().xpath("//*[@id="colophon"]/div/div[1]/a").get();
System.out.println("This is a footer information: " + footer);
}
public Site getSite(){ return site; }
public static void main(String[] args){
Spider PriceScraper = Spider.create(new Main()).addUrl("https://scrapeme.live/shop/");
PriceScraper.run();
}
}
备注:JAR 文件可以在 Maven Central Repository 网站上找到。
这是输出:
This is a footer information: Built with Storefront & WooCommerce.
8.Apache Nutch
Apache Nutch是一个开源的 Java 网络爬虫软件,具有高度可扩展性。它为高效爬取提供了一个高性能、可靠、灵活的架构。它可以帮助您创建一个可以索引多个网站、博客文章、图像和视频的搜索引擎。
该库已与Apache Solr集成,为 Web 搜索应用程序提供最全面的解决方案。通过其可扩展性和灵活性,它允许开发人员抓取整个 Web 或特定页面。
👍优点:
- Nutch 是免费和开源的,允许开发人员根据需要定制和扩展软件。
- 它可以扩展,因此您可以轻松索引数百万页。
- 该框架具有高度可扩展性,因为开发人员可以添加自己的插件来进行解析、数据存储和索引。
👎缺点:
- 无法抓取基于 JavaScript 或 AJAX 的网站。
- 它需要大量的设置时间和资源。
Apache Nutch 是如何抓取网站的?让我们检查:
import org.apache.hadoop.conf.Configuration;
import org.apache.nutch.crawl.Crawl;
import org.apache.nutch.fetcher.Fetcher;
import org.apache.nutch.util.NutchConfiguration;
public class NutchScraper {
public static void main(String[] args) throws Exception {
// Initialize Nutch instance.
String url = "https://demo.vuestorefront.io/";
Configuration conf = NutchConfiguration.create();
Crawl nutch = new Crawl(conf);
// Crawl the given URL
nutch.crawl(url);
Fetcher fetcher = new Fetcher(conf);
fetcher.fetch(url);
System.out.println("Title of website is: " + fetcher.getPage().getTitle());
}
}
这是脚本输出:
Title of the website is: Vue Storefront | Vue Storefront Demo
9. HtmlUnit
HtmlUnit是一个 Java 框架,用于模拟 Web 浏览器和自动化任务,例如填写表单、单击按钮和在页面之间导航。
👍优点:
- 该库没有 GUI,这使得它非常适合在服务器或持续集成环境中运行抓取和自动化任务。
- 它可以很容易地嵌入到其他 Java 应用程序中,这对于那些想在现有项目中添加抓取功能的人来说非常有用。
- 适用于任何技能水平的专业人士,因为它的 API 简单易用。
- 它支持范围广泛的 Web 技术,包括 HTML、CSS 和 JavaScript。
👎缺点:
- 无法始终如一地模拟真实浏览器的行为,这可能会导致在抓取依赖 JavaScript 的页面时出现问题。
- 它仅支持基本的身份验证技术,因此任何具有更复杂登录技术的网站可能需要不同的自动化工具。
这是一个例子:
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitScraper {
public static void main(String[] args) throws Exception{
// Create a new web client and open a webpage.
WebClient webclient = new WebClient();
HtmlPage page = webclient.getPage("https://angular.io");
// Get h1 which has a class name of 'hero-headline no-title no-toc no-anchor'
DomNodeList<DomElement> element = page.getByXPath("//div[@class='hero-headline no-title no-toc no-anchor']");
System.out.println(element.asText());
}
}
输出显示h1内容:
Deliver web apps with confidence
10. Htmleasy
Htmleasy是一个开源 Java 库,旨在使开发人员更轻松地解析和生成 HTML。它在底层 HTML 结构之上提供了一个简单直观的界面,自动交易复杂性以获得易用性。
👍优点:
- 便于使用。
- 它提供了极大的灵活性,同时仍然很直观。
- 开源。
- 它适用于任何现代版本的 Java。
👎缺点:
- 文档不完整。
- 对于小型项目来说,它可能有点矫枉过正,因为它的大尺寸对于简单的任务来说可能并不实用。
Htmleasy 是如何工作的?请参阅以下定位购物:
import com.htmeasy; // Importing HTMLEasy library
import java.util; // Import util package for ArrayList
public class ShoppingScraper {
public static void main(String args) {
// Set url of web page we want to scrape from
String url = "https://www.shopping.com/products?KW=laptop";
// Get content from the web page using the HTMLEasy get() function with the URL defined above
HtmlContent html = HtmlEasy.get(url);
// Create an array list to store products and their details from web page HTML content
List<Map<String, String>> products = new ArrayList<>();
// Iterate through each product container ('h3') found on the HTML page by class name (using query selector) and store relevant details in our Array List
for (HtmlElement product : html.getElementsByClassName("topOfferCard card") ) {
// Create hash map to store individual product details (title, image link and price)
Map<String, String> itemDetails = new HashMap<>();
// Get & store product title by selecting 'a' tag
itemDetails.put("title: ", product.selectFirst(".topDealName card-link").innerText());
products.add(itemDetails); // add our hashmap of item details to our arraylist
}
// Print all the items scraped from the webpage
System.out.println(products);
}
}
这是一个产品列表作为输出:

结论
如您所见,有多种优秀的 Java 网络抓取库可供选择。有这么多选项,评估和选择最适合您需求的选项的过程变得更加困难和重要。
| ZenRows | Selenium | Gecco | Jsoup | Jaunt | Jauntium | WebMagic | Apache Nutch | HTMLUnit | Htmleasy | |
|---|---|---|---|---|---|---|---|---|---|---|
| 代理配置 | 自动 | 手动 | – | 手动 | – | 手动 | – | 手动 | – | |
| 动态内容 | √ | √ | – | – | – | √ | – | – | √ | √ |
| 文档 | √ | √ | – | √ | √ | √ | √ | √ | √ | – |
| 反机器人绕过 | √ | – | – | – | – | – | – | – | – | – |
| 基础架构可扩展性 | 自动 | √ | √ | √ | √ | √ | – | √ | √ | √ |
| HTML 自动解析 | √ | – | – | √ | – | √ | – | √ | √ | √ |
| 使用方便 | 简单 | 中等 | 中等 | 简单 | 中等 | 中等 | 中等 | 难的 | 中等 | 简单 |
虽然一个值得考虑的好选择是ZenRows来处理反机器人绕过(包括旋转代理、无头浏览器、验证码等),但这里是我们检查过的所有 Java 网络抓取工具的简要总结:
- ZenRows:它提供基于 API 的 Web 数据提取,而不会被反机器人保护阻止。
- Selenium:一个著名的用于浏览器自动化的 Java 库,它通过 DOM 识别元素。
- Gecco:凭借其多功能性和易于使用的界面,您可以抓取整个网站或其中的一部分。
- Jsoup:一个用于解析 HTML 和 XML 文档的 Java 网络爬虫库,侧重于易用性和可扩展性。
- Jaunt:一个抓取和自动化库,用于提取数据和自动化 Web 任务。
- Jauntium:该框架允许您使用几乎所有现代网络浏览器进行自动化。
- WebMagic:它提供了一组 API,可用于以声明和高效的方式抓取 Web 数据。
- Apache Nutch:开源网络爬虫,专为涉及数百万页面的大型项目而设计。它支持在 Hadoop 集群或其他云计算框架上进行分布式处理。
- HtmlUnit:一个 Java 爬虫库,用于模拟浏览器、管理 cookie 和发出 HTTP 请求。在使用非浏览器客户端(例如 RESTful 应用程序)测试场景时很有用。
- Htmleasy:简单的网页解析器。
常见问题
哪些库用于 Java 中的网页抓取?
一些最常用的 Java 网络抓取库包括 Selenium、ZenRows、Jsoup 和 Jaunt。它们分别提供无头浏览、反机器人绕过和数据解析。
什么是好的 Java 抓取库?
为 Java 选择一个好的抓取库取决于项目的性质。您可以选择像 Selenium 这样的浏览器自动化工具、像 Jsoup 这样的数据解析器,或者像 ZenRows 这样的反机器人绕过 API。有时,它们的组合会带来最好的结果。
什么是最流行的 Web 抓取 Java 库?
Jsoup 是最流行的 Java 网络抓取库的一个很好的候选者。
它是一种功能强大且用途广泛的工具,用于从不同类型的页面(如 HTML 和 XML 文档)中提取结构化数据。
哪个 Java Web 抓取库最适合您?
最好的 Java 抓取库取决于您的特定需求和要求。例如,Selenium 非常适合自动化 Web 浏览器,Jsoup 擅长数据提取,而 ZenRows 将允许您在不被阻止的情况下进行抓取。





