

30+ Hadoop 面试问题及答案

根据福布斯的统计数据,多达90%的世界组织使用大数据分析来创建他们的投资报告。
随着Big Data的日益普及,与以往相比,Hadoop工作机会出现了激增。
因此,为了帮助您获得Hadoop专家角色,您可以使用我们在本文中为您整理的这些面试问题和答案来帮助您顺利通过面试。
也许了解Hadoop和大数据职位薪资范围等事实会激励您通过面试,对吗?🤔
- 根据indeed.com的数据,美国的大数据Hadoop开发人员平均工资为144,000美元。
- 根据itjobswatch.co.uk的数据,大数据Hadoop开发人员的平均工资为66,750英镑。
- 在印度,indeed.com的数据显示他们的平均薪资为16,00,000卢比。
利润丰厚,不是吗?接下来,让我们来了解一下Hadoop。
Hadoop是什么?
Hadoop是一个流行的框架,使用编程模型来处理、存储和分析大量数据。
默认情况下,它的设计允许从单个服务器扩展到多台提供本地计算和存储的机器。此外,它能够检测和处理应用程序层故障,从而实现高可用的服务,使Hadoop非常可靠。
让我们直接进入常见的Hadoop面试问题及其正确答案。
Hadoop的面试问题和答案

Hadoop中的存储单元是什么?
答案: Hadoop的存储单元称为Hadoop分布式文件系统(HDFS)。
网络附加存储与Hadoop分布式文件系统有何不同?
答案: HDFS是Hadoop的主要存储,是一个分布式文件系统,使用廉价硬件存储大文件。另一方面,NAS是一个文件级计算机数据存储服务器,为异构的客户端组提供对数据的访问。
NAS的数据存储在专用硬件上,而HDFS将数据块分布在Hadoop集群中的所有机器上。
NAS使用高端存储设备,成本较高,而HDFS使用的廉价硬件具有成本效益。
NAS将数据与计算分开存储,因此不适合MapReduce。相反,HDFS的设计使其可以与MapReduce框架一起工作。在MapReduce框架中,计算移动到数据而不是数据移动到计算。
解释Hadoop中的MapReduce和Shuffling
答案: MapReduce是Hadoop程序执行的两个不同任务,它们能够在Hadoop集群中的数百到数千台服务器上实现大规模可扩展性。Shuffling将Map器的输出传输给MapReduce中所需的Reducer。
简要介绍Apache Pig架构
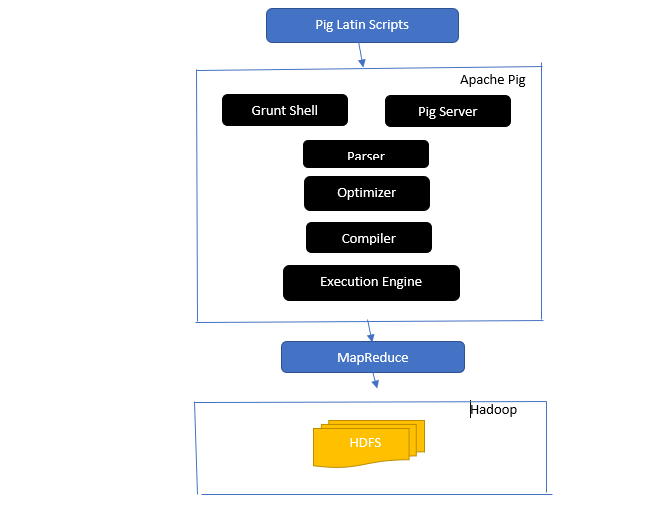
答案: Apache Pig架构具有一个Pig Latin解释器,使用Pig Latin脚本处理和分析大型数据集。
Apache Pig还包括一组数据集,对这些数据集执行诸如连接、加载、过滤、排序和分组等数据操作。
Pig Latin语言使用执行机制(如Shell,UDF和嵌入式)编写执行所需任务的Pig脚本。
Pig通过将这些编写的脚本转换为Map-Reduce作业系列,简化了程序员的工作。
Apache Pig架构组件包括:
- 解析器 – 它通过检查脚本的语法并执行类型检查来处理Pig脚本。解析器的输出表示Pig Latin的语句和逻辑运算符,称为DAG(有向无环图)。
- 优化器 – 优化器在DAG上实现逻辑优化,如投影和推送。
- 编译器 – 将优化后的逻辑计划从优化器编译成一系列MapReduce作业。
- 执行引擎 – 这是将MapReduce作业最终执行为所需输出的地方。
- 执行模式 – Apache Pig中的执行模式主要包括本地模式和MapReduce模式。
列出本地Metastore和远程Metastore之间的区别
答案: 本地Metastore中的Metastore服务运行在与Hive相同的JVM中,但连接到在同一台或远程机器上运行的其他进程中的数据库。另一方面,远程Metastore中的Metastore在其独立于Hive服务JVM的JVM中运行。
大数据的五个V是什么?
答案: 这五个V代表了大数据的主要特征。它们包括:
- 价值:大数据旨在为在数据操作中使用大数据的组织提供显著的好处,从高投资回报率(ROI)到洞察力发现和模式识别,从而带来更强的客户关系和更有效的业务等多个方面的好处。
- 多样性:这代表了收集的不同类型的数据的异质性。各种格式包括图片、视频、音频等。
- 容量:这定义了组织管理和分析的大量数据的数量和大小。这些数据呈指数增长。
- 速度:这是数据增长的指数速度。
- 真实性:真实性指数据的“不确定”或“不准确”程度,这是由于数据不完整或不一致导致的。
解释Pig Latin的不同数据类型。
答案: Pig Latin中的数据类型包括原子数据类型和复杂数据类型。
原子数据类型是在其他语言中使用的基本数据类型。它们包括以下内容:
- Int – 这个数据类型定义了一个有符号的32位整数。示例:13
- Long – Long定义了一个64位整数。示例:10L
- Float – 定义了一个带符号的32位浮点数。示例:2.5F
- Double – 定义了一个带符号的64位浮点数。示例:23.4
- Boolean – 定义了一个布尔值。包括:True/False
- Datetime – 定义了一个日期时间值。示例:1980-01-01T00:00.00.000+00:00
复杂数据类型包括:
- Map – Map表示键值对集合。示例:[‘color'#'yellow', ‘number'#3]
- Bag – 它是一组元组的集合,使用'{}'符号。示例:{(Henry,32),(Kiti,47)}
- Tuple – 元组定义了一个有序的字段集合。示例:(Age,33)
Apache Oozie和Apache ZooKeeper的角色是什么?
答案: Apache Oozie是一个Hadoop调度程序,负责将Hadoop作业调度和绑定在一起作为单个逻辑工作。
另一方面,Apache ZooKeeper在分布式环境中与各种服务协调。它通过简单地公开同步、分组、配置维护和命名等简单服务来节省开发人员的时间。Apache ZooKeeper还为队列和领导者选举提供现成的支持。
组合器、RecordReader和Partitioner在MapReduce操作中的作用是什么?
答案:Combiner的作用类似于一个小型reducer。它接收并处理来自map任务的数据,然后将数据的输出传递给reducer阶段。
RecordHeader与InputSplit通信,并将数据转换为适合mapper读取的键值对。
Partitioner负责决定所需的归约任务数量以汇总数据,并确认组合器输出如何发送到reducer。Partitioner还控制中间映射输出的键分区。
提到Hadoop的不同供应商特定发行版。
答案:扩展Hadoop功能的各个供应商包括:
- IBM开放平台。
- Cloudera CDH Hadoop发行版
- MapR Hadoop发行版
- Amazon Elastic MapReduce
- Hortonworks Data Platform(HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- Microsoft Azure的HDInsight – 基于云的Hadoop发行版。
HDFS为什么具有容错性?
答案:HDFS在不同的DataNodes上复制数据,使其具有容错性。将数据存储在不同的节点上,可以在一个节点崩溃时从其他节点检索数据。
区分联邦和高可用性。
答案:HDFS联邦提供了容错性,允许在一个节点崩溃时在另一个节点上保持连续的数据流。另一方面,高可用性将要求在第一台和第二台机器上分别配置活动NameNode和辅助NameNode的两台独立机器。
联邦可以拥有无限数量的不相关的NameNode,而高可用性中只有两个相关的NameNode,即活动和备用,它们持续工作。
联邦中的NameNode共享元数据池,每个NameNode都有自己的专用池。然而,在高可用性中,活动NameNode每次只运行一个,而备用NameNode则保持空闲,只偶尔更新其元数据。
如何查找块和文件系统健康的状态?
答案:您可以在根用户级别和个别目录中使用hdfs fsck /命令来检查HDFS文件系统的健康状态。
使用的HDFS fsck命令:
hdfs fsck / -files --blocks –locations> dfs-fsck.log命令的说明:
- -files:打印您正在检查的文件。
- –locations:在检查时打印所有块的位置。
检查块状态的命令:
hdfs fsck -files -blocks- :从此处开始检查。
- – blocks:在检查期间打印文件块
何时使用rmadmin-refreshNodes和dfsadmin-refreshNodes命令?
答案:这两个命令有助于在节点委托完成期间或节点委托完成后刷新节点信息。
dfsadmin-refreshNodes命令运行HDFS客户端并刷新NameNode的节点配置。另一方面,rmadmin-refreshNodes命令执行ResourceManager的管理任务。
什么是检查点?
答案:检查点是将文件系统的最新更改与最新的FSImage合并的操作,以便编辑日志文件保持足够小,以加快启动NameNode的过程。检查点发生在辅助NameNode中。
为什么我们使用HDFS处理具有大数据集的应用程序?
答案:HDFS提供了DataNode和NameNode架构,实现了分布式文件系统。
这两种架构可以在Hadoop的高可扩展集群上高效地访问数据。其NameNode将文件系统的元数据存储在RAM中,这导致内存的大小限制了HDFS文件系统文件的数量。
“jps”命令是用来做什么的?
答案:Java虚拟机进程状态(JPS)命令用于检查特定的Hadoop守护进程是否正在运行,包括NodeManager、DataNode、NameNode和ResourceManager。需要以root身份运行此命令以检查主机上的操作节点。
Hadoop中的“推测执行”是什么?
答案:这是Hadoop中的主节点在检测到慢任务时,不是修复该任务,而是在另一个节点上启动同一个任务的备份任务(推测任务)。推测执行可以节省大量时间,特别是在密集工作负载环境中。
Hadoop可以运行在哪三种模式下?
答案:Hadoop可以运行在以下三个主要节点上:
- 独立节点是默认模式,使用本地文件系统和单个Java进程运行Hadoop服务。
- 伪分布式节点使用单个节点的Hadoop部署来执行所有Hadoop服务。
- 完全分布式节点使用独立节点来运行Hadoop主节点和从节点的服务。
什么是UDF?
答案:用户定义函数(UDF)允许您编写自定义函数,用于在链接_6期间处理列值。
什么是DistCp?
答案:DistCp(分布式复制)是一个用于大规模集群内或集群间数据复制的实用工具。使用MapReduce,DistCp有效地实现对大量数据的分布式复制,以及错误处理、恢复和报告等其他任务。
解释Hive中的元数据存储。
答案:Hive元数据存储是一种将Apache Hive元数据存储在关系数据库(如MySQL)中的服务。它提供了元数据的元数据服务API,允许对元数据进行快速访问。
定义RDD。
答案:RDD即弹性分布式数据集,是Spark的数据结构,也是一个在不同集群节点上计算的不可变分布式数据集合。
如何在YARN作业中包含本地库?
答案:您可以通过在命令中使用-Djava.library. path选项或者使用以下格式在.bashrc文件中设置LD_LIBRARY_PATH来实现:
mapreduce.map.env
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs
解释HBase中的“WAL”。
答案:Write Ahead Log(WAL)是HBase中将MemStore数据更改记录到基于文件的存储的恢复协议。如果RegionalServer崩溃或在刷新MemStore之前,WAL可以恢复这些数据。
YARN是Hadoop MapReduce的替代品吗?
答案:不,YARN不是Hadoop的替代品。相反,一种强大的技术叫作Hadoop 2.0或MapReduce 2支持MapReduce。
HIVE中的ORDER BY和SORT BY有什么区别?
答案:虽然两个命令在Hive中都以有序的方式获取数据,但使用SORT BY命令得到的结果可能只是部分排序。
此外,SORT BY命令需要一个reducer来对行进行排序。用于生成最终输出的这些reducer也可能是多个。在这种情况下,最终输出可能只是部分排序的。
另一方面,ORDER BY命令只需要一个reducer来实现完全有序的输出。您还可以使用LIMIT关键字来减少总排序时间。
什么是Spark和Hadoop之间的区别?
答案:虽然Hadoop和Spark都是分布式处理框架,但它们的主要区别在于它们的处理方式。Hadoop适用于批处理,而Spark适用于实时数据处理。
此外,Hadoop主要通过读写文件到HDFS来进行数据处理,而Spark使用弹性分布式数据集(Resilient Distributed Dataset)的概念来在内存中处理数据。
根据延迟性而言,Hadoop是一个高延迟的计算框架,没有交互模式来处理数据,而Spark是一个低延迟的计算框架,可以交互地处理数据。
比较Sqoop和Flume。
答案:Sqoop和Flume是Hadoop工具,用于收集从各种来源收集的数据并将数据加载到HDFS中。
- Sqoop(SQL-to-Hadoop)从数据库中提取结构化数据,包括Teradata、MySQL、Oracle等,而Flume适用于从数据库源提取非结构化数据并加载到HDFS中。
- 在事件驱动方面,Flume是事件驱动的,而Sqoop不是由事件驱动的。
- Sqoop使用基于连接器的架构,连接器知道如何连接到不同的数据源。Flume使用基于代理的架构,其代码是负责获取数据的代理。
- 由于Flume的分布式特性,它可以轻松地收集和聚合数据。Sqoop适用于并行数据传输,这将导致输出为多个文件。
解释BloomMapFile。
答案:BloomMapFile是一个扩展MapFile类的类,它使用动态布隆过滤器为键提供快速的成员测试。
列出HiveQL和PigLatin之间的区别。
答案:HiveQL是一种类似于SQL的声明性语言,而PigLatin是一种高级过程化数据流语言。
什么是数据清洗?
答案:数据清洗是一个重要的过程,用于消除或修复数据集中已识别的数据错误,包括不正确、不完整、损坏、重复和格式错误的数据。
该过程旨在提高数据质量,并提供更准确、一致和可靠的信息,以便组织内进行高效决策。
总结💃
随着当前大数据和Hadoop工作机会的激增,您可能希望提高自己进入其中的机会。本文的Hadoop面试问题和答案将帮助您在即将到来的面试中脱颖而出。
接下来,您可以查看good resources to learn Big Data and Hadoop。
祝您好运!👍






