

什么是Google JAX?你需要了解的一切

Google JAX或J ust After E xecution是由Google开发的一种框架,用于加速机器学习任务。
您可以将其视为Python的库,有助于更快的任务执行、科学计算、函数转换、深度学习、神经网络等。
关于Google JAX
Python中最基本的计算包是NumPy包,其中包含了所有的聚合函数、向量运算、线性代数、n维数组和矩阵操作以及许多其他高级函数。
如果我们可以进一步加速使用NumPy进行的计算——尤其是对于大型数据集呢?
我们是否有一种可以在不进行任何代码更改的情况下同样适用于GPU或TPU等不同类型的处理器的方法呢?
如果系统可以自动且更高效地执行可组合的函数转换会怎样呢?
Google JAX是一个库(或框架,正如维基百科所说),它恰好可以做到这一点,或许还能做得更多。它是为了优化性能并高效执行机器学习(ML)和深度学习任务而构建的。Google JAX提供了以下变换特性,使其与其他ML库不同,并有助于深度学习和神经网络的高级科学计算:
- 自动微分
- 自动向量化
- 自动并行化
- 即时(JIT)编译
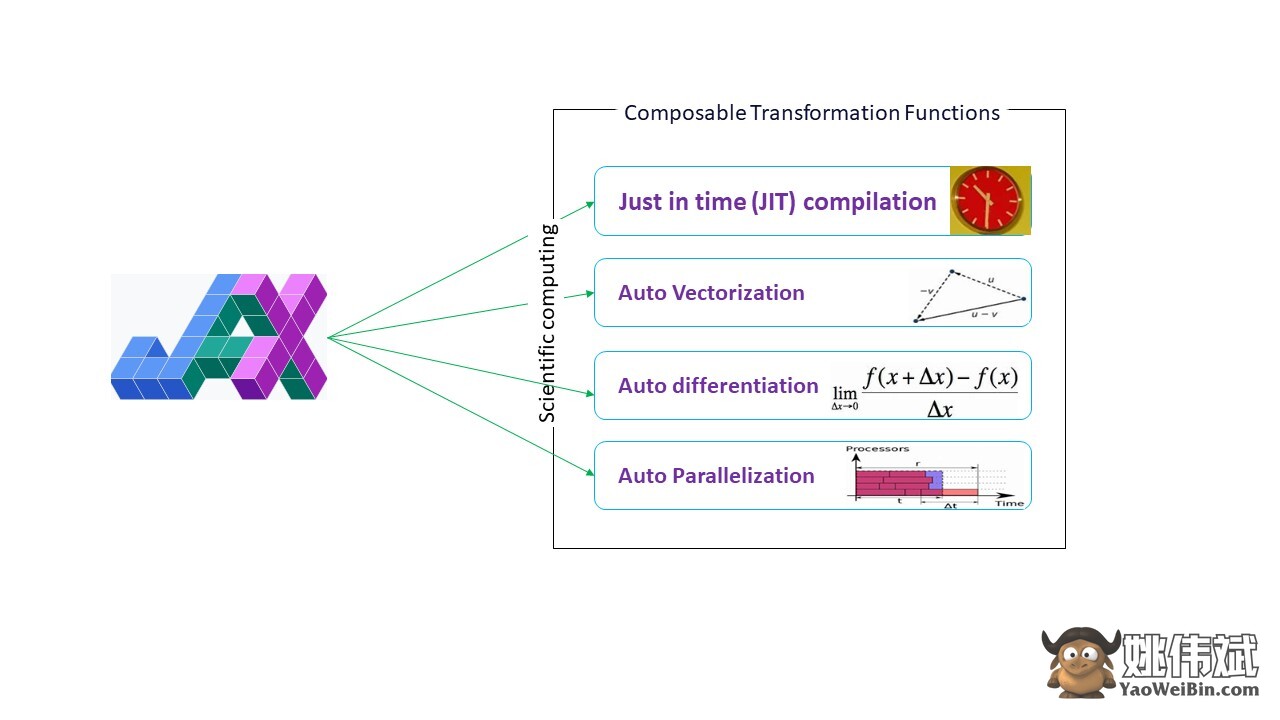
所有这些转换都使用XLA(加速线性代数)进行更高的性能和内存优化。XLA是一个特定领域的优化编译器引擎,用于执行线性代数并加速TensorFlow模型。在您的Python代码之上使用XLA不需要进行重大的代码更改!
让我们详细探讨每个功能。
Google JAX的特性
Google JAX带有重要的可组合变换函数,以提高性能并更高效地执行深度学习任务。例如,自动微分可以获得函数的梯度并找到任意阶导数。类似地,自动并行化和JIT可以并行执行多个任务。这些转换对于机器人技术、游戏甚至研究等应用至关重要。
一个可组合的变换函数是一个纯函数,它将一组数据转换为另一种形式。它们被称为可组合,因为它们是自包含的(即这些函数与程序的其余部分没有依赖关系)且是无状态的(即相同的输入总是产生相同的输出)。
Y(x) = T: (f(x))
在上述公式中,f(x)是应用变换的原始函数。Y(x)是应用变换后的结果函数。
例如,如果您有一个名为'total_bill_amt'的函数,并且希望将结果作为函数转换,您可以简单地使用您希望使用的转换,比如梯度(grad):
grad_total_bill = grad(total_bill_amt)
通过使用类似grad()的函数转换数值函数,我们可以轻松地获得它们的高阶导数,在深度学习优化算法(如梯度下降)中广泛使用,从而使算法更快更高效。同样地,通过使用jit(),我们可以即时编译Python程序。
#1. 自动微分
Python使用autograd函数来自动区分NumPy和本地Python代码。JAX使用改进版的autograd(即grad)并结合XLA(加速线性代数)来执行自动区分并找到GPU(图形处理单元)和TPU(张量处理单元)的任意阶导数。
关于TPU,GPU和CPU的快速说明:CPU或中央处理单元管理计算机上的所有操作。GPU是一个附加处理器,增强计算能力并运行高端操作。TPU是专为复杂和繁重工作负载(如AI和深度学习算法)而开发的强大单元。
与autograd函数相同,它可以通过循环、递归、分支等进行区分,JAX使用grad()函数进行反向传播。此外,我们可以使用grad对函数进行任意阶的区分:
grad(grad(grad(sin θ))) (1.0)
更高阶的自动区分
正如我们之前提到的,grad在找到函数的偏导数方面非常有用。我们可以使用偏导数来计算深度学习中与神经网络参数相关的成本函数的梯度下降,以最小化损失。
计算偏导数
假设一个函数有多个变量x、y和z。通过保持其他变量不变来找到一个变量的导数称为偏导数。设我们有一个函数
f(x,y,z) = x + 2y + z2
用例展示偏导数
x的偏导数将是∂f/∂x,它告诉我们在其他变量保持不变时函数如何改变。如果我们手动执行此操作,我们必须编写一个程序来进行区分,为每个变量应用它,然后计算梯度下降。对于多个变量,这将变得复杂且耗时。
自动区分将函数分解为一组基本运算,如+、-、*、/或sin、cos、tan、exp等,并使用链式法则计算导数。我们可以在正向和反向模式下进行。
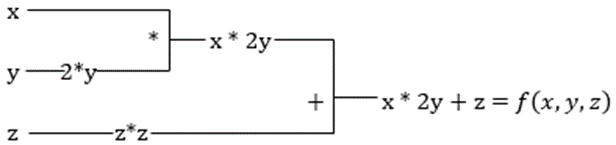
这还不是全部!所有这些计算发生得非常快(想象一下类似上面的百万个计算及其所需的时间!)。XLA负责速度和性能。
#2. 加速线性代数
让我们看看之前的方程。如果没有XLA,计算将需要三个(或更多)内核,其中每个内核将执行一个较小的任务。例如:
内核k1 –> x * 2y(乘法)
k2 –> x * 2y + z(加法)
k3 –> 缩减
如果使用XLA执行相同的任务,一个单独的内核将通过融合中间操作来处理所有操作。基本运算的中间结果被流式传输而不是存储在内存中,从而节省内存并提高速度。
#3. 即时编译
JAX内部使用XLA编译器来提高执行速度。XLA可以提升CPU、GPU和TPU的速度。所有这些都可以通过JIT代码执行来实现。要使用此功能,我们可以通过导入使用jit:
from jax import jit
def my_function(x):
…………一些代码行
my_function_jit = jit(my_function)另一种方法是在函数定义上使用jit进行装饰:
@jit
def my_function(x):
…………一些代码行这段代码要快得多,因为变换将返回编译后的代码版本给调用者,而不是使用Python解释器。这对于矢量输入(如数组和矩阵)特别有用。
这对所有现有的Python函数也是适用的,例如NumPy包中的函数。在这种情况下,我们应该导入jax.numpy as jnp而不是NumPy:
import jax
import jax.numpy as jnp
x = jnp.array([[1,2,3,4], [5,6,7,8]])一旦你这样做了,核心JAX数组对象DeviceArray将替代标准的NumPy数组。DeviceArray是惰性的,即值在加速器中保留,直到需要。这也意味着JAX程序不会等待结果返回给调用(Python)程序,从而实现异步调度。
#4. 自动向量化(vmap)
在典型的机器学习世界中,我们有包含百万甚至更多数据点的数据集。很可能,我们需要对每个或大多数这些数据点执行一些计算或操作–这是一个非常耗时和占用内存的任务!例如,如果你想在数据集中找到每个数据点的平方,你首先想到的是创建一个循环并逐个取平方–烦死人!
如果我们将这些点创建为向量,我们可以通过使用我们喜欢的NumPy对数据点进行向量或矩阵操作来一次完成所有平方。如果你的程序可以自动完成这个过程–你还能要求什么呢?这正是JAX所做的!它可以自动将所有数据点向量化,以便你可以轻松地对它们执行任何操作–使你的算法更快,更高效。
JAX使用vmap函数进行自动向量化。考虑以下数组:
x = jnp.array([1,2,3,4,5,6,7,8,9,10])
y = jnp.square(x)仅通过上述操作,平方方法将对数组中的每个点执行。但如果你执行以下操作:
vmap(jnp.square(x))由于数据点现在在执行函数之前自动向量化,而不是标量乘法,循环被推入到基本的操作级别中–从而产生矩阵乘法而不是标量乘法,从而提高性能。
#5. SPMD编程(pmap)
SPMD–或单一程序多个数据编程在深度学习环境中非常重要–你经常需要在多个GPU或TPU上的不同数据集上应用相同的函数。JAX具有一个名为pump的函数,允许在多个GPU或任何加速器上进行并行编程。像JIT一样,使用pmap的程序将由XLA编译,并在系统中同时执行。这种自动并行化对于正向和反向计算都起作用。
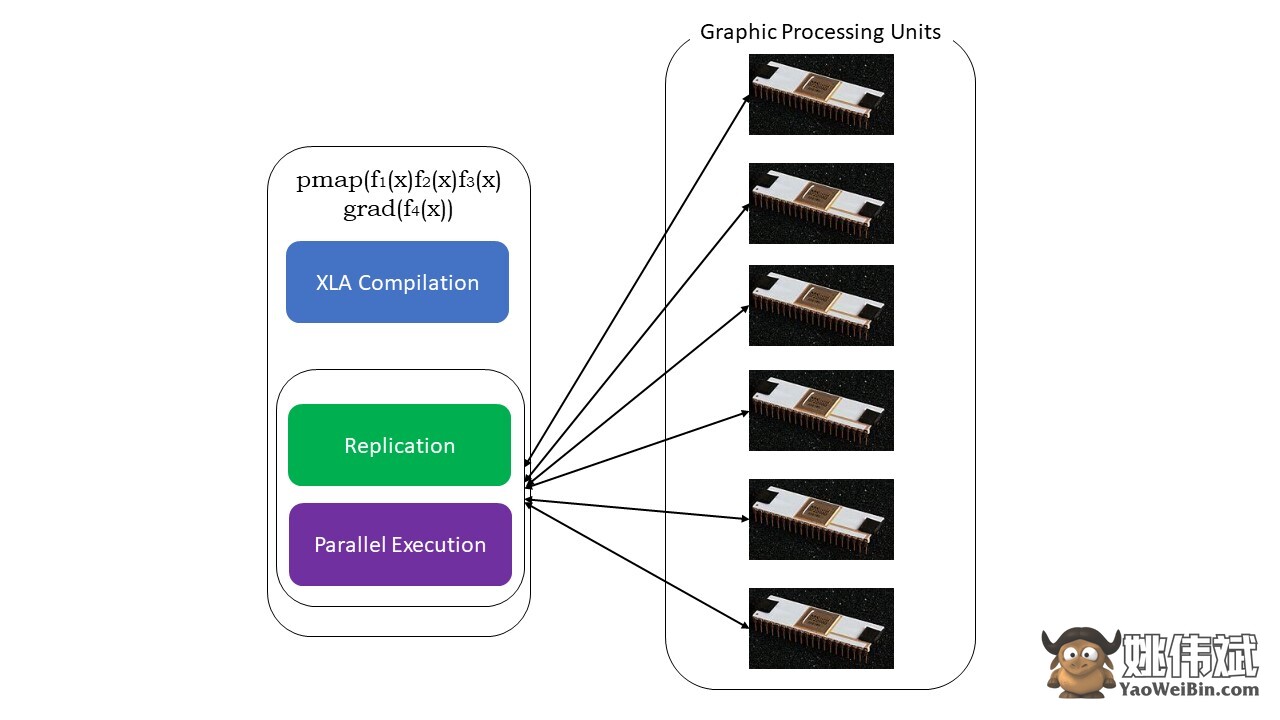
我们还可以在任何顺序上一次性应用多个转换到任何函数上:
pmap(vmap(jit(grad (f(x)))))
多个可组合的转换
Google JAX的局限性
Google JAX的开发人员对加速算法考虑得很周到,同时引入了所有这些令人惊叹的变换。科学计算函数和包与NumPy类似,因此您不必担心学习曲线。然而,JAX有以下限制:
- Google JAX仍处于早期开发阶段,尽管其主要目的是性能优化,但对于CPU计算并没有太大的好处。NumPy似乎表现更好,使用JAX可能只会增加开销。
- JAX仍处于研究或早期阶段,需要更多的微调才能达到像TensorFlow这样的框架的基础设施标准,后者更为成熟并具有更多预定义的模型、开源项目和学习资料。
- 目前,JAX不支持Windows操作系统-您需要使用虚拟机使其正常工作。
- JAX仅适用于纯函数-那些没有任何副作用的函数。对于具有副作用的函数,JAX可能不是一个好选择。
如何在Python环境中安装JAX
如果您的系统上设置了Python,并且想在本地机器(CPU)上运行JAX,请使用以下命令:
pip install --upgrade pip
pip install --upgrade "jax[cpu]"如果您想在GPU或TPU上运行Google JAX,请按照链接3的说明进行操作。要设置Python,请访问链接4的页面。
结论
Google JAX非常适用于编写高效的深度学习算法、机器人技术和研究。尽管存在一些限制,但它与Haiku、Flax等其他框架广泛配合使用。当您运行程序并查看使用和不使用JAX执行代码的时间差异时,您将能够欣赏到JAX的作用。您可以从阅读链接5开始,该链接非常全面。






