

如何开始机器学习?
设计比人类更聪明的机器并不是什么新鲜事。
计算机科学最早对人类“智能”的攻击之一就是通过象棋游戏。许多人都认为象棋是人类智力和创造力的最终考验,而在1960年代到70年代,计算机科学界有不同的思潮。
一些人认为,电脑在下棋方面超过人类只是时间问题,而其他人则认为这永远不会发生。
卡斯帕罗夫对阵深蓝
人机大战中最轰动的事件之一是1996年国际象棋比赛,当时的世界冠军加里·卡斯帕罗夫(可能是有史以来最优秀的国际象棋选手)对阵由IBM专门为此比赛设计的超级计算机深蓝。

长话短说,卡斯帕罗夫在1996年的比赛中以4比2的成绩取得了胜利,但在1997年的复赛中以4.5比3.5的比分输掉了比赛,之后一度大量有关卡斯帕罗夫对IBM的直接作弊指控和争议引起了关注。
不管怎样,象棋和计算机科学的一个时代结束了。电脑被认为比任何人类都聪明。IBM满意地以复仇心态解散了深蓝并继续前进。
如今,任何国际象棋大师都无法击败运行在普通硬件上的任何常规国际象棋引擎。
机器学习不是什么?
在我们深入了解机器学习之前,让我们先澄清一些误解。机器学习并不是试图复制人脑。尽管像埃隆·马斯克等人持有耸人听闻的观点,但计算机科学研究人员坚称他们并不在寻找这个神圣的目标,而且离这个目标还远远不够。
简单来说,机器学习是将学习-by-example 过程应用于计算机的实践。这与依靠人类程序员思考所有可能情况并将规则硬编码到系统中的传统方法形成对比。
机器学习就是这样:将大量的数据输入到计算机中,让它通过示例(尝试→出错→比较→改进)进行学习,而不是依靠源代码。
机器学习的应用
那么,如果机器学习并不是黑魔法,也不会产生终结者,它有什么用处呢?

机器学习在传统编程无法解决的情况下发挥作用,这些情况通常可归类为以下两类。
- 分类
- 预测
如其名称所示,分类涉及正确标记事物,而预测旨在根据足够多的过去数值数据集纠正未来预测。
机器学习的一些有趣应用包括:
垃圾邮件过滤
Email spam是无处不在的,但试图阻止它可能是一场噩梦。什么是垃圾邮件?是特定关键词的存在吗?还是写作方式?想出一个程序上的详尽规则是很困难的。
这就是为什么我们使用机器学习。我们向系统展示数百万封垃圾邮件和非垃圾邮件,让它自己学会判断。这就是Gmail在2000年代初期掀起个人电子邮件革命的秘密!
推荐
今天,所有主要的电子商务公司都拥有强大的推荐系统。有时候,他们对我们“可能”会找到有用的东西的能力非常准确,尽管我们以前从未点击过该项。
巧合吗?一点也不!
机器学习正在此处努力工作,吞噬着一遍又一遍的数据,并试图预测我们多变的情绪和偏好。
聊天机器人
你是否遇到过一级客户支持,他们似乎有些机械,但又能进行有趣的闲聊呢?

嗯,那么你已经被机器学习所击败了!
从对话中学习并确定什么时候说什么话是一个新兴且令人兴奋的领域。
除草
在农业中,由机器学习驱动的机器人被用来有选择性地喷洒杂草和其他不受欢迎的植物。
否则,这将不得不通过手工完成,或者会非常浪费,因为系统会将产品与杀虫剂液体一起喷洒!
语音搜索
Voice-based interaction与计算机系统不再是科幻。如今,我们有像Alexa、Siri和Google Home这样的数字助手,可以口头接收指令而不会出错(嗯,几乎不会!)。
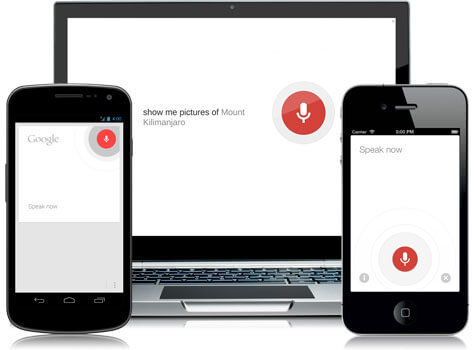
有人可能会争辩说,这是一个最好避免的发明,因为它让人类变得比以往任何时候都更懒,但你无法否认其有效性。
医学诊断
在医学诊断方面,基于机器学习的系统正开始在通过X射线等方面的病例中超越有经验的医生。
请注意,这并不意味着医生们很快就不再需要,而是医疗保健的质量将大幅提高,而成本将大幅下降(除非商业卡特尔决定否定这一点!)。
这只是机器学习的一些应用示例。如今,自动驾驶汽车、策略游戏机器人、折叠T恤机器、破解验证码和给黑白照片上色也都在发生。
机器学习的类型
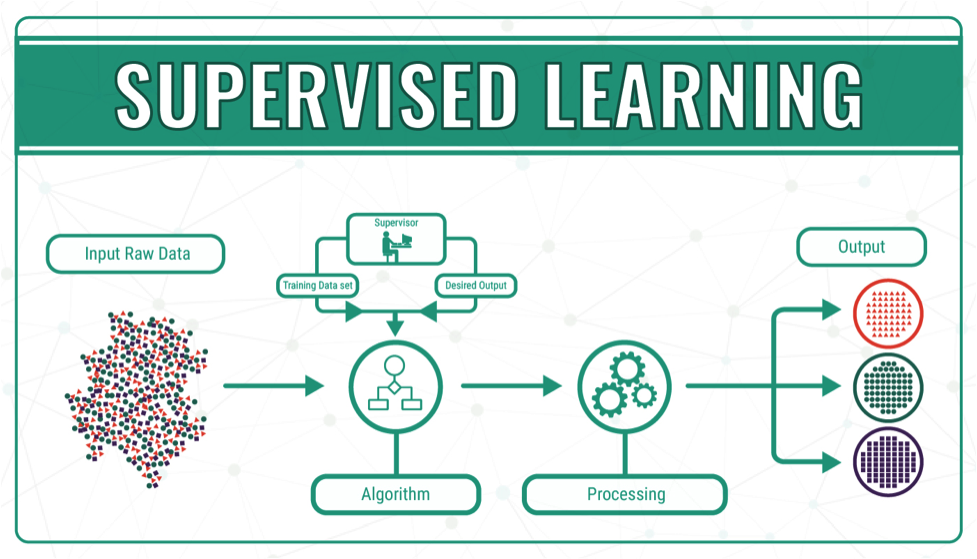
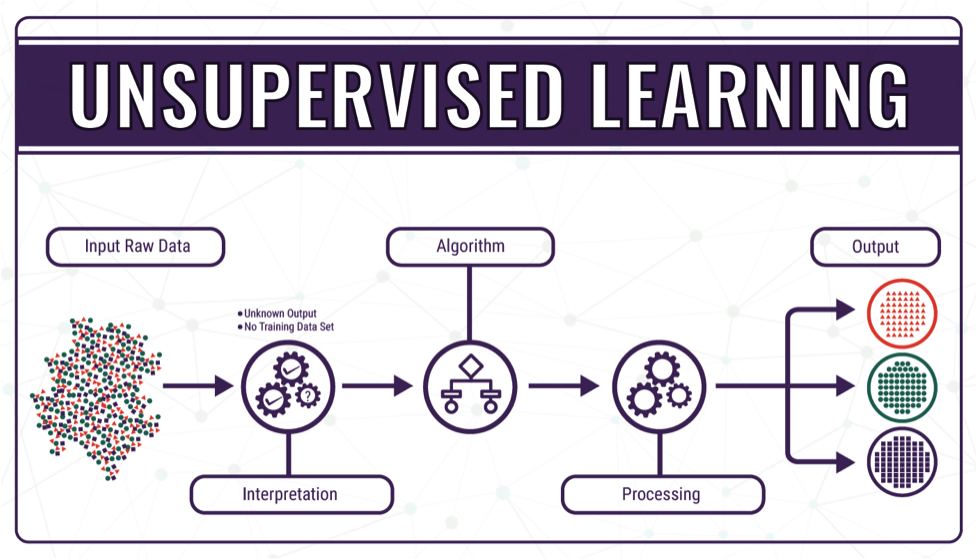
机器学习技术分为两种。
有监督学习,系统受人类判断的指导,和无监督学习,系统自己学习。换句话说,有监督学习中,我们有一个包含输入和预期输出的数据集,系统用来进行比较和自我纠正。然而,在无监督学习中,没有现有的输出来进行衡量,因此结果可能会变化很大。
无监督机器学习的一个令人兴奋且令人毛骨悚然的应用是机器人下棋,程序被教会游戏规则和获胜条件,然后被留给自己。程序会对自己进行数百万场比赛,从错误中学习并加强有利的决策。
如果你有一台足够强大的计算机,那么一个世界级的下棋AI可以在几个小时内制作出来!
以下图片简洁地说明了这些观点(来源:Medium):
机器学习的工具和库
数据科学专业人员使用许多机器学习工具和库来解决复杂的机器学习问题。以下是一些最好的库,你可以尝试使用:
#1. TensorFlow
TensorFlow是一种端到端的机器学习平台,被许多人喜爱用于创建生产级别的机器学习模型。你可以直接使用它的预训练模型,或者创建自己的模型并进行训练。
所以,现在你对机器学习充满热情,知道它如何帮助你征服世界,那么从哪里开始呢?
下面我列出了一些网上的资源,可以帮助你在不需要计算机科学博士学位的情况下掌握机器学习技能!如果你不是机器学习研究人员,你会发现机器学习领域像编程一样实用和有趣。
所以,不要担心,无论你目前的水平如何,你都可以像一个好的机器学习程序一样自学并进步。 😛
#1. 编程
进入机器学习的第一个要求是学习编程。因为机器学习系统以形式存在。
Python是最推荐的一种语言,部分原因是它非常容易学习,部分原因是它有大量的库和资源生态系统。
official初学者指南是一个很好的开始,即使你对Python有一些了解。或者,参加这个Bootcamp course从零开始成为英雄的课程。
#2. Think Stats
一旦你完成了Python的基础知识,我的第二个建议是阅读两本优秀的书籍。它们是100%免费,可以作为PDF文件下载。Think Stats和Think Bayes是两本现代经典书籍,每个有志成为机器学习工程师的人都应该掌握。
#3. Udemy
这个阶段,我建议你从Udemy中选几门课程。互动、自学的方式会帮助你深入了解,并增强信心。
在开始之前,请确保查看课程预览、评论(特别是负面评论)和整体感觉。
你也可以在YouTube上找到很多免费的精彩教程。我推荐一个叫做Sentdex的频道,那里总是有很多有趣的内容,但他的方法不适合初学者。
#4. Andrew Ng
由Andrew Ng讲授的课程在Coursera上是机器学习基础知识最受欢迎的学习资源。

虽然它使用R编程语言,但它在对待这个主题和清晰解释方面是无与伦比的。因为这门课程,Andrew Ng在机器学习界取得了一定的神话般地位,人们崇敬他的终极智慧(我不是在开玩笑!)。
这不是针对初学者的课程,但如果你已经擅长数据处理,并且在进行学习时不介意进行一些副研究,这是最好的推荐。
#5. Udacity
通过参加Udacity的纳米学位,成为一名机器学习工程师。
需要大约3个月的时间完成课程,结束时,你应该对机器学习算法有一个很好的理解,知道如何进行建模和部署到生产环境。
结论
互联网上有无尽的资源,当你开始时,很容易迷失方向。大部分的资料和讨论都是数学上的挑战,或者缺乏结构,可能会在你开始之前打破你的信心。
所以,我想警告你不要自毁:保持你的目标适度,并采取最小步骤。机器学习不是你可以在一两天内掌握的东西,但很快你就会开始享受其中,并且谁知道,也许会成为专家!
玩得开心! 🙂






