如何在R中进行探索性数据分析(EDA)(附带示例)

学习一切关于探索性数据分析的内容,这是一种重要的过程,用于发现趋势和模式,并通过统计摘要和图形表示对数据集进行总结。
像任何项目一样,一个data science项目是一个需要时间、良好组织和严谨尊重多个步骤的长期过程。探索性数据分析(EDA)是这个过程中最重要的步骤之一。
因此,在本文中,我们将简要介绍什么是探索性数据分析以及如何使用R进行分析!
什么是探索性数据分析?
探索性data analysis在将数据集提交给应用程序(无论是纯粹的业务、统计还是机器学习)之前,研究和分析数据集的特征。

通过视觉方法(如图形表示和表格)对信息的性质和主要特点进行总结。这种实践通常事先进行,以评估这些数据的潜力,这些数据将在未来接受更复杂的处理。
因此,EDA可以:
- 为使用此信息制定假设;
- 探索数据结构中隐藏的细节;
- 识别缺失值、异常值或异常行为;
- 发现整体趋势和相关变量;
- 丢弃无关的变量或与其他变量相关的变量;
- 确定要使用的形式建模。
<h3描述性数据分析和探索性数据分析之间的区别是什么?
有两种类型的数据分析,描述性分析和探索性数据分析,尽管目标不同,但它们是相辅相成的。
第一种侧重于描述变量的行为,例如平均值、中位数、众数等。
探索性分析旨在识别变量之间的关系,提取初步见解,并将建模指向最常见的机器学习范式:分类、回归和聚类。
两者都可以处理图形表示;然而,只有探索性分析才寻求提供可操作的见解,即能够引发决策者采取行动的见解。
最后,虽然探索性数据分析旨在解决问题并提供将指导建模步骤的解决方案,但描述性分析仅旨在对所讨论的数据集进行详细描述。
| 描述性分析 | 探索性数据分析 |
| 分析行为 | 分析行为和关系 |
| 提供总结 | 导致具体规范和行动 |
| 将数据组织成表格和图形 | 将数据组织成表格和图形 |
| 没有重要的解释能力 | 有重要的解释能力 |
探索性数据分析的一些实际用途
#1. 数字营销
Digital Marketing已从创意过程演变为数据驱动的过程。营销组织使用探索性数据分析确定活动或努力的结果,并指导消费者投资和定位决策。
人口统计学研究、客户细分和其他技术使营销人员能够利用大量的消费者购买、调查和面板数据来理解和沟通战略市场营销。
Web探索性分析允许营销人员收集有关网站上的交互的会话级信息。 Google Analytics是营销人员用于此目的的免费和流行的分析工具。
在营销中经常使用的探索性技术包括营销组合建模、定价和促销分析、销售优化和探索性客户分析,例如细分。
#2. 探索性投资组合分析
探索性数据分析的一个常见应用是探索性投资组合分析。银行或贷款机构拥有一系列价值和风险不同的账户。
账户可能因持有人的社会地位(富人、中产阶级、穷人等)、地理位置、净资产和许多其他因素而不同。贷款人必须在每笔贷款的回报和违约风险之间取得平衡。然后问题就变成了如何对整个投资组合进行估值。
最低风险的贷款可能是给非常富有的人,但富人人数非常有限。另一方面,许多贫困人口可以贷款,但风险更大。
探索性数据分析解决方案可以将时间序列分析与许多其他问题结合起来,以决定何时向这些不同的借款人分段贷款或贷款利率。对于一个投资组合部分的会员收取利息以弥补该部分成员之间的损失。
#3. 探索性风险分析
银行正在开发预测模型,以提供关于个人客户风险评分的确定性。旨在预测个人的拖欠行为,并广泛用于评估每个申请人的信用。
此外,风险分析在科学界和保险行业也得到了广泛应用。在金融机构中也广泛用于在线支付网关公司分析交易是否真实或欺诈。
为此,他们使用客户的交易历史记录。它在信用卡购买中更常用;当客户交易量突然增加时,如果他发起了交易,客户会收到确认电话。它还有助于减少因此类情况而导致的损失。
使用R进行探索性数据分析
使用R进行EDA的第一步是下载R基础和R Studio(IDE),然后安装和加载以下软件包:
#安装软件包
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#加载软件包
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
在本教程中,我们将使用一个内置于R中并提供美国经济的年度经济指标数据的经济数据集,并将其简化为econ:
econ <- ggplot2::economics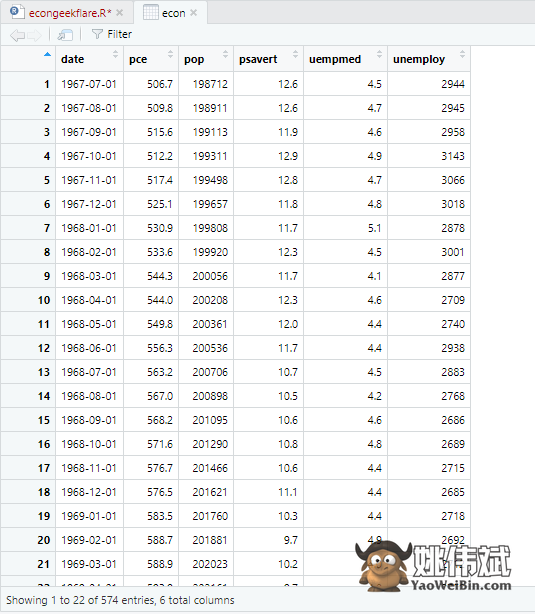
为了进行描述性分析,我们将使用skimr软件包,该软件包以简单和清晰的方式计算这些统计数据:
#描述性分析
skimr::skim(econ)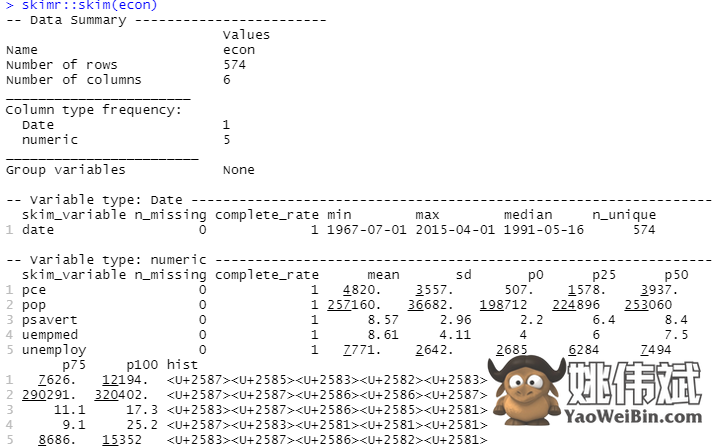
您还可以使用summary函数进行描述性分析:
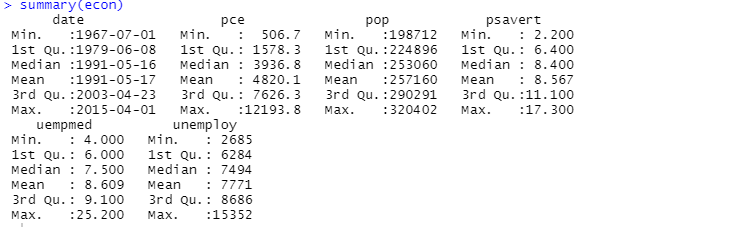
这里的描述性分析显示数据集中有547行和6列。最小值是1967-07-01,最大值是2015-04-01。类似地,它还显示了平均值和标准差。
现在你对econ数据集的内容有了基本的了解。让我们绘制变量uempmed的直方图,以更好地查看数据:
#失业率的直方图
econ %>%
ggplot2::ggplot() +
ggplot2::aes(x = uempmed) +
ggplot2::geom_histogram() +
labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
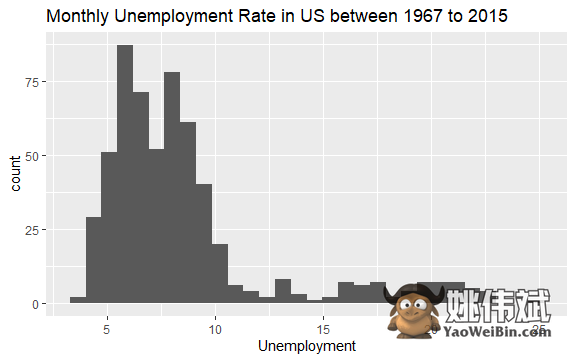
直方图的分布显示,其右侧有一个延长的尾部;也就是说,此变量可能有一些更“极端”值的观察结果。问题是:这些值发生在什么时期,变量的趋势如何?
识别变量趋势最直接的方法是通过折线图。下面我们生成一张折线图并添加平滑线:
#失业的折线图
econ %>%
ggplot2::autoplot(uempmed) +
ggplot2::geom_smooth()
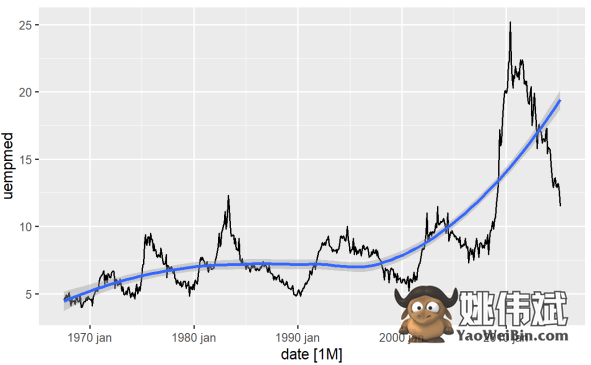
通过这个图表,我们可以发现在最近的时期,从2010年的观察中,失业率有上升的趋势,超过了之前几十年的历史观察数据。
另一个重要的问题,特别是在计量经济建模的情况下,是系列的平稳性;也就是说,均值和方差是否随时间恒定?
当变量不满足这些假设时,我们说该系列具有单位根(非平稳),从而变量所遭受的冲击产生了永久效应。
对于所讨论的变量,失业期限似乎是如此。我们已经看到了变量的波动性发生了相当大的变化,这对于涉及周期的经济理论有着重要的影响。但是,离开理论,我们如何实际检查变量是否平稳?
预测包含一个优秀的函数,可以应用一些检验,如ADF、KPSS等,这些检验可以返回使系列平稳所需的差异数量:
#使用ADF测试检查平稳性
forecast::ndiffs(
x = econ$uempmed,
test = "adf")
这里大于0.05的p值显示数据是非平稳的。
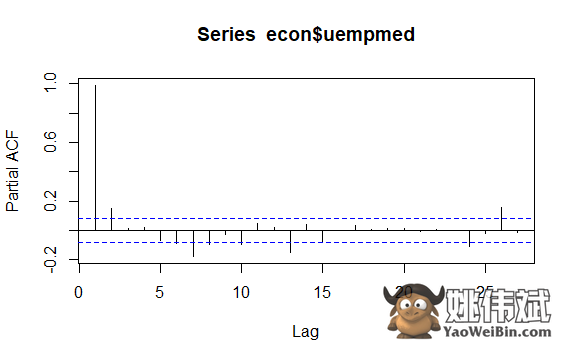
时间序列中的另一个重要问题是识别系列滞后值之间的可能相关性(线性关系)。ACF和PACF自相关图帮助进行识别。
由于系列没有季节性但有一定趋势,初始自相关倾向于较大和正值,因为接近时间的观察结果也接近数值。
因此,趋势时间序列的自相关函数(ACF)倾向于具有缓慢减小的正值随着滞后增加。
#失业残差
checkresiduals(econ$uempmed)
pacf(econ$uempmed)
结论
当我们接触到相对干净的数据时,即已经清理过的数据,我们立即想要深入进行模型构建阶段以得出第一批结果。但是我们必须抵制这种诱惑,开始进行探索性数据分析,这是简单的但有助于我们从数据中得出有力见解的方法。
您还可以探索一些学习资源,了解更多信息 statistics for Data Science。