

如何绕过Akamai反爬虫风控
Web 抓取是一种古老且仍然常用的数据提取技术。Akamai Bot Manager 和其他供应商试图减轻抓取可能导致的问题。他们的目标是阻止诸如 DDoS 或欺诈性身份验证尝试之类的攻击。出于教育目的,我们的目标是绕过 Akamai。
爬虫不是他们的主要目标,但无论如何都可能会阻止他们的内容。区分好的和坏的机器人不是一件容易的事。让我们看看他们是怎么做的以及如何做的,并学习如何绕过 Akamai Bot Manager!
什么是机器人检测软件
Bot 检测,也称为 Web 应用防火墙 (WAF) 或反爬虫保护,是一组对 Bot 进行分类和检测的技术。
过去,措施涉及检测高负载 IP 和检查标头。这使得防御系统能够阻止大部分的抓取流量。
随着这些技术的发展,抓取世界也在发展。许多爬虫试图绕过这些措施,导致机器人检测行业变得更好。
多年后,反抓取软件开始包括被动和主动方法。被动,如存储 IP 和僵尸网络并为每个请求识别它们。主动监控浏览器和用户活动,或将浏览历史记录提供给机器学习程序。
根据官方白皮书(第 13 页),Akamai 已在 2016 年进行行为分析。从那时起,他们一直在发展,所有机器人检测软件供应商也是如此。他们现在为网站所有者提供了一个机器人评分模型来微调他们的阻止攻击性。
Akamai Bot Manager 有什么作用?
Akamai Bot Manager 的主要目标是在最危险、最狡猾的机器人削弱客户信任之前阻止它们。这涵盖了各种各样的操作,包括网络抓取。
为了实现他们的目标,他们采取了多种行动。他们维护一个bot 目录,应用AI 来检测新型 bot,并且由于它们存在于许多大流量站点中,因此他们获得了集体智慧。
所有这些安全措施也适用于更具侵略性的攻击:DDoS、虚假帐户创建或具有网络钓鱼意图的复制站点。区分目的是一个关键方面。
机器人管理的两个关键方面是:
- 区分人类和机器人。
- 区分好机器人和坏机器人。
并非所有的机器人都是恶意的。没有人愿意将 Google 排除在外,他们也在抓取和抓取。那么,他们是怎么做到的呢?
Akamai Bot Manager 如何工作?
如上所述,他们使用各种各样的技术。在我们深入技术实施之前,我们将解释其中的一些。当然,还要学习如何绕过它们。
这些是绕过 Akamai Bot Manager 的活动部件:
- 僵尸网络。维护已知机器人的历史数据并提供给他们的系统。相同的 IP 范围、用户代理命名中的常见错误或类似模式。其中任何一个都可能泄露僵尸网络。一旦识别并记录下来,阻止该模式就会让人感到安全。没有人会那样浏览。
- 知识产权。阻止 IP 听起来像是最简单的方法。没那么简单。IP 不会经常更改所有权,但使用它们的人会经常更改。攻击者可能会使用属于普通 ISP 的 IP,掩盖其来源和意图。普通用户可能会在一周后获得该 IP 地址。到那时,它应该可以无障碍地访问内容。
- 验证码。区分人类和机器人的最佳程序,对吧?再次,一个有争议的。通过在每个会话中使用 CAPTCHA,一个站点会赶走多个用户。没有人愿意每隔一个请求就解决一次。作为一种防御策略,只有在流量可疑时才会出现验证码。
- 浏览器和传感器数据。注入一个 javascript 文件,该文件将监视并运行一些检查。然后将所有数据发送给服务器进行处理。稍后我们将看到它是如何完成的以及要发送什么数据。
- 浏览器指纹识别。与僵尸网络一样,常见的结构或模式可能会暴露您的身份。爬虫可能会改变并掩盖他们的请求。但有些细节(浏览器或硬件相关)很难隐藏。Akamai 将利用这一点。
- 行为分析。比较网站上的历史用户行为。检查模式和常见操作。例如,用户可以不时直接访问产品。但是,如果他们从不访问类别或搜索页面,则可能会触发警报。
刮擦检测不是黑色或白色。Akamai Bot Manager 结合了上述所有内容以及其他一些内容。然后,根据站点的设置,它会决定是否阻止用户。机器人检测服务混合使用服务器端和浏览器端检测技术。
如果我们想跳过 Akamai Bot Manager,我们必须首先了解它是如何使用它们的。或者面对“拒绝访问页面”:
 有没有请求被阻止?与我们一起避免 Akamai 的障碍。
有没有请求被阻止?与我们一起避免 Akamai 的障碍。我们只能猜测 Akamai 如何进行服务器端检测。但是我们可以看看他们的客户端。
Akamai 的 Javascript 挑战解释
![]()
正如我们在上图中看到的,脚本触发了一个带有巨大负载的 POST 请求。如果我们想绕过 Akamai Bot Detection,了解此有效负载至关重要。这并不容易。
反混淆挑战
您可以在此处下载该文件。要实时查看它,请访问KICKZ并在 DevTools 上查找该文件。
首先,在JavaScript Deobfuscator上运行内容。这会将奇怪的字符转换为字符串。然后,我们需要用这些字符串替换对初始数组的引用。
他们不使用直接名称声明变量或对象键来使事情变得更难。他们使用间接方式:用相应的索引引用该数组。
我们还没有找到可以确定更换过程的在线工具。但您可以执行以下操作:
_acxj从生成的代码中剪切变量。- 创建一个文件并放置该变量。
- 然后将其余代码放在另一个变量中。
- 替换(不完美)对数组的所有引用,请参见下面的代码。
- 审查,因为其中一些会失败。
var _acxj = ['csh', 'RealPlayer Version Plugin', 'then', /* ... */];
const code = `var _cf = _cf || [], ...`;
const result = code
.replace(/[_acxj[(d+)]]/g, (_, i) => `.${_acxj[i]}`)
.replace(/_acxj[(d+)]/g, (_, i) => JSON.stringify(_acxj[i]));
由于这是一种笨拙的尝试,因此需要进行一些手动调整。适当的替换需要更多细节和例外情况。下载我们的最终版本以查看其外观。
为了节省您的时间,我们已经这样做了。原始文件经常更改。这个结果现在可能不一样了。但它会帮助您了解哪些数据以及它们如何将 id 发送到服务器。
Akamai 的传感器数据
 您可以在上方看到发送以供处理的数据。我们可以以红色突出显示的项目为例。从它的内容,我们可以猜出前两个来自哪里:用户代理和屏幕尺寸。第三个看起来像一个 JSON 对象,但我们无法仅通过其键知道它代表什么。
您可以在上方看到发送以供处理的数据。我们可以以红色突出显示的项目为例。从它的内容,我们可以猜出前两个来自哪里:用户代理和屏幕尺寸。第三个看起来像一个 JSON 对象,但我们无法仅通过其键知道它代表什么。
第一个键cpen——存在于脚本中。快速查找文件会告诉我们这一点。所以 w引用它的行。
var t = [],
a = window.callPhantom ? 1 : 0;
t.push(",cpen:" + a);
这是什么意思?该脚本检查是否callPhantom存在。在 Google 上快速搜索告诉我们这是 PhantomJS 引入的一个特性。这意味着发送cpen:1可能是 Akamai 的警报。没有合法的浏览器实现该功能。
如果您检查下一行,您会看到它们一直在发送浏览器数据。window.opera,例如,如果浏览器不是 Opera,则永远不应该为真。或者mozInnerScreenY只存在于 Firefox 浏览器上。你看到一个模式吗?没有一个数据点是破坏交易的(好吧,也许是 PhantomJS 那个),但是当一起分析时它们揭示了很多!
调用的函数bd生成所有这些数据点。如果我们寻找它的用法,我们会找到许多变量串联在一起的一行。n + "," + o + "," + m + "," + r + "," + c + "," + i + "," + b + "," + bmak.bd(). 信不信由你,但这o就是屏幕的可用高度。
我们怎么知道呢?转到变量的定义。控制 + 单击或类似的 IDE 将带你到那里。
定义本身并没有告诉我们任何有用的信息:o = -1。但是请看下面的几行:
try {
o = window.screen ? window.screen.availHeight : -1
} catch (t) {
o = -1
}
您了解了Akamai为后端处理发送浏览器/传感器数据的内容和方式。
我们不会涵盖所有项目,但您明白了。对您感兴趣的任何数据点应用相同的过程。
但最关键的问题是:我们为什么要这样做?🤔
要绕过 Akamai 的防御,我们必须了解他们是如何做到的。然后,检查他们为此使用了哪些数据。有了这些知识,就可以找到无障碍访问页面的方法。
屏蔽您的传感器数据
如果您所有的机器都发送了类似的数据,Akamai 可能会对它进行指纹识别。这意味着他们检测并分组它们。相同的浏览器供应商、屏幕尺寸、处理时间、浏览器数据。有模式吗?检查你的数据。他们已经在这样做了。
假设是这样,如何避免呢?有几种方法可以掩盖它们,例如Puppeteer stealth。
他们是怎么做到的?它是开源的,我们可以看看逃避!
availHeight没有回避,所以我们将切换到hardwareConcurrency. 为了简单起见,我们选择了一个简单的。大多数规避都比较复杂。
假设您所有的生产机器都是一样的。这很常见——相同的规格、硬件、软件等。它们的并发性是相同的,例如,"hardwareConcurrency": 4.
这只是沧海一粟。但请记住,Akamai Bot Manager 处理数百个数据点。我们可以通过更换一些.
// Somewhere in your config.
// There should be a helper function called `sample`.
const options = {hardwareConcurrency: sample([4, 6, 8, 16])};
// The evasion itself.
// Proxy navigator.hardwareConcurrency getter and return a custom value.
utils.replaceGetterWithProxy(
Object.getPrototypeOf(navigator),
'hardwareConcurrency',
utils.makeHandler().getterValue(options.hardwareConcurrency)
)
代理充当中介。hardwareConcurrency在这种情况下,对于object 上的函数navigator。调用时,它不会返回原来的,而是将其替换为我们在选项中设置的那个。例如,它可以是典型值列表中的随机数。
我们用这种方法得到了什么?Akamai 会看到随机发送的hardwareConcurrency的不同值。假设我们针对多个参数执行此操作,则很难看出模式。Akamai 在每次访问时运行这不是一个复杂的过程吗?对每个人来说,好的部分是他们只做一次。然后设置 cookies 以避免再次运行所有进程。
避免持续挑战的 Cookie
为什么对你有好处?一旦获得 cookies,接下来的请求应该是未检查的。这意味着这些 cookie 将绕过 Akamai WAF!
为了安全起见,我们建议使用相同的 IP来模拟实际的用户会话。
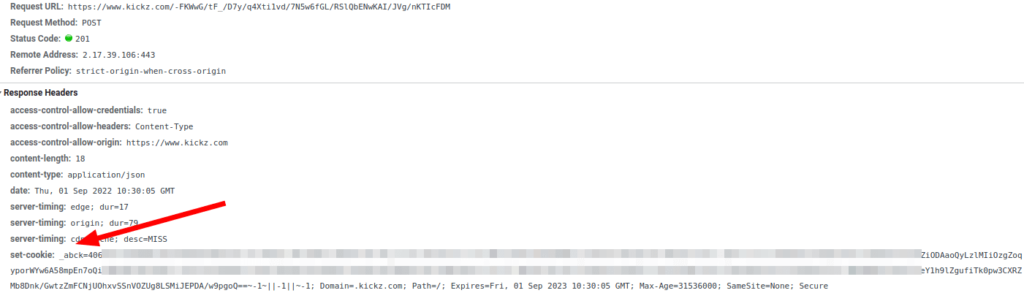
Akamai 使用的标准 cookie 是_abck、ak_bmsc、bm_sv和bm_mi。要找到有关这些的信息并不容易。由于cookie 政策,一些网站列出并解释了它们。
 请注意,这
请注意,这ak_bmsc只是 HTTP。这意味着您无法从 Javascript 访问其内容。您将需要检查传感器数据调用的响应标头。对于其他人,您可以检查标题或document.cookie在浏览器上调用。
哇,要承担的事情太多了。
现在让我们看看如何应用我们刚刚学到的要点来跳过 Akamai WAF。
如何绕过 Akamai Bot Manager
以下是一些有助于废弃 Akamai 受保护网站的典型做法,我们将绕过所有这些做法。他们的门槛并不相同。有些人可能更具侵略性。我们稍后会讨论它们。
- 关注 robots.txt
- 良好的旋转代理
- 使用无头浏览器
- HTTP 标头
- 无头浏览器的隐身技术
- 不要与 Javascript 挑战相矛盾
关注 robots.txt
这听起来可能很明显也很简单。它是。但是抓取被 robots.txt 阻止的内容可能会标记您的抓取工具。而且,如果 Akamai 发现了一种模式,您的所有请求可能会在一段时间后被阻止。请记住,Akamai Bot Manager 会从访问者及其行为中学习。
对蜜罐要格外小心。这些页面旨在引诱恶意机器人。例如,通过人类永远不会遵循的无形链接。他们可以标记您或减慢您的流程。
良好的旋转代理
一个好的 IP 地址可能无法绕过 Akamai 防御,但一个坏的 IP 地址将被自动拒绝。不更改 IP 的代理也是如此。在一些请求之后,其 Bot Manager 将阻止它。这只是时间问题。
好的代理有两个属性(非排他性):
- 旋转。他们会在每次请求或短时间后更改 IP。
- 产地。它确定这些 IP 的来源。Akamai Bot Manager 很难阻止普通 4G 提供商使用的 IP。很难区分机器人和人类。通常的例子是数据中心或住宅。
使用无头浏览器
正如我们所见,必须通过 Javascript 挑战。没有浏览器你不能通过它。静态抓取——curl、js 中的 axios 或 python 中的请求——从长远来看是行不通的。有些站点可能会运行几次但并不可靠。
输入无头浏览器,例如Selenium。他们执行真正的浏览器,如 Chrome,没有图形界面。这意味着他们将下载并运行 Akamai 挑战赛。
结合良好的代理,它看起来就像一个真正的用户。尽管如此,机器人检测软件还是可以区分它们。
HTTP 标头
浏览器默认发送一组标头,更改它们时要小心。如果您为 Chrome 和 Safari 添加相同的标头,Akamai 会发现有问题。
只改变你需要的最少的。并始终检查整个集合是否有意义。假设您想将 Google 添加为引荐来源网址。您可以添加referer: https://www.google.com/.
简单吧?好吧,没那么快。默认情况下,Chrome 会发送sec-fetch-site: none. 但如果来自谷歌,浏览器将添加sec-fetch-site: cross-site.
一个小细节,是的。但真正的浏览器永远不会失败的事情。
无头浏览器的隐身技术
我们已经在上面看到了这些是如何工作的。这些做法包括修改浏览器响应特定挑战的方式。Akamai 的检测软件会查询浏览器、硬件和许多其他东西。为了避免模式和指纹识别,隐身模式会覆盖其中的一些。它增加了变化并掩盖了浏览器。
其中一些行为是可检测的。您将必须测试并检查正确的组合。每个站点可以有不同的配置。
好消息是您已经了解 Akamai 如何决定阻止哪些请求。或者至少您知道他们为此收集了哪些数据。
不要与 Javascript 挑战相矛盾
同样,这听起来很明显,但一些数据点可能来自另一个数据点或重复。如果您决定屏蔽一个而忘记另一个,Akamai 机器人检测将看到它。并采取行动,或者至少在内部进行标记。
在传感器数据示例图像中,我们可以看到它发送窗口大小。大多数数据点都是相关的:实际屏幕、可用尺寸、内部尺寸和外部尺寸。
例如,内部永远不应大于外部。随机值在这里不起作用。您需要一组实际尺寸。
绕过 Akamai 的最简单方法
有时,让其他人来做繁重的工作是个好计划。ZenRows 旨在绕过 Akamai Bot Manager或任何其他反抓取系统。它允许您抓取内容,而不必担心自己跳过 Akamai 或其他人。ZenRows 提供 API 和 Proxy 两种模式,选择最适合您的。
专注于构建您的数据提取系统。充分利用您的数据。忘记处理我们谈到的所有复杂部分。
结论
这真是一段旅程!我们知道它很深入,但机器人检测是一个复杂的话题。
绕过 Akamai 僵尸程序检测或其他防御系统的要点是:
- 具有新鲜和旋转 IP 的良好代理。
- 关注 robots.txt。
- 使用隐身模式的无头浏览器。
- 了解 Akamai 的挑战,以便您能够适应规避。
有关更新信息,您可以查看他们的网站。它解释了它们涵盖的方面以及一些一般信息,但并不深入。不多,但如果有任何变化,它可以指导您。
如果您喜欢它,您可能会对我们关于如何绕过 Cloudflare 的文章感兴趣。





![Python 网页抓取初学者指南 [2023 年循序渐进]](https://yaoweibin.cn/wp-content/uploads/2023/07/Python网页抓取-768x510.jpg)
