13个数据科学家应了解的大数据工具

在信息时代,数据中心收集大量的数据。收集的数据来自各种来源,如金融交易、客户互动、社交媒体等等,并且更重要的是,数据积累得更快。
数据可以是多样化且敏感的,需要适当的工具来使其具有意义,因为它具有无限的潜力来现代化业务统计、信息并改变生活。

大数据工具和数据科学家在这些场景中非常突出。
这么多种类繁多的数据,使用传统的工具和技术如Excel来处理是困难的。Excel不是真正的数据库,并且对于存储数据有限制(65536行)。
数据分析在Excel中显示出较差的数据完整性。从长远来看,存储在Excel中的数据具有有限的安全性和合规性,非常低的disaster recovery率,而且没有适当的版本控制。
为了处理如此大量且多样化的数据集,需要一套独特的工具,称为数据工具,来检查、处理和提取有价值的信息。这些工具可以让您深入挖掘数据,找到更有意义的洞察和数据模式。
处理这种复杂的技术工具和数据自然需要独特的技能,这就是为什么数据科学家在大数据中发挥关键作用的原因。
大数据工具的重要性
数据是任何组织的基石,用于提取有价值的信息,进行详细的分析,创造机会,并规划新的业务里程碑和愿景。
每天都会产生越来越多的数据,这些数据必须高效、安全地存储并在需要时进行检索。这些数据的规模、种类和快速变化要求使用新的大数据工具、不同的存储和分析方法。
根据一项研究,到2027年,全球大数据市场预计将增长到1030亿美元,是2018年预期市场规模的两倍以上。
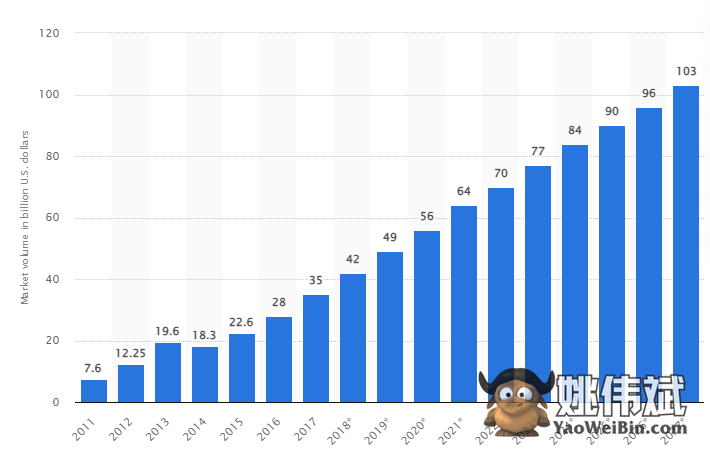
当今行业面临的挑战
术语“大数据”最近被用来指代数据集,这些数据集增长得如此之大,以至于传统的数据库管理系统(DBMS)难以处理。
数据的大小不断增加,今天的数据范围从几十TB到许多PB。这些数据集的大小超过了常见软件随时间处理、管理、搜索、共享和可视化的能力。
大数据的形成将导致以下几点:
- 质量管理和改进
- 供应链和效率管理
- 客户智能
- 数据分析和决策
- 风险管理和fraud detection
在本节中,我们将介绍最好的big data工具以及数据科学家如何使用这些技术来过滤、分析、存储和提取数据,当公司希望进行更深入的分析以改进和发展业务时。
Apache Hadoop
Apache Hadoop是一个开源的Java平台,用于存储和处理大量的数据。
Hadoop通过将大数据集(从TB到PB)进行映射,将分析任务分配给集群,并将其分成较小的块(64MB到128MB),从而实现更快的数据处理。
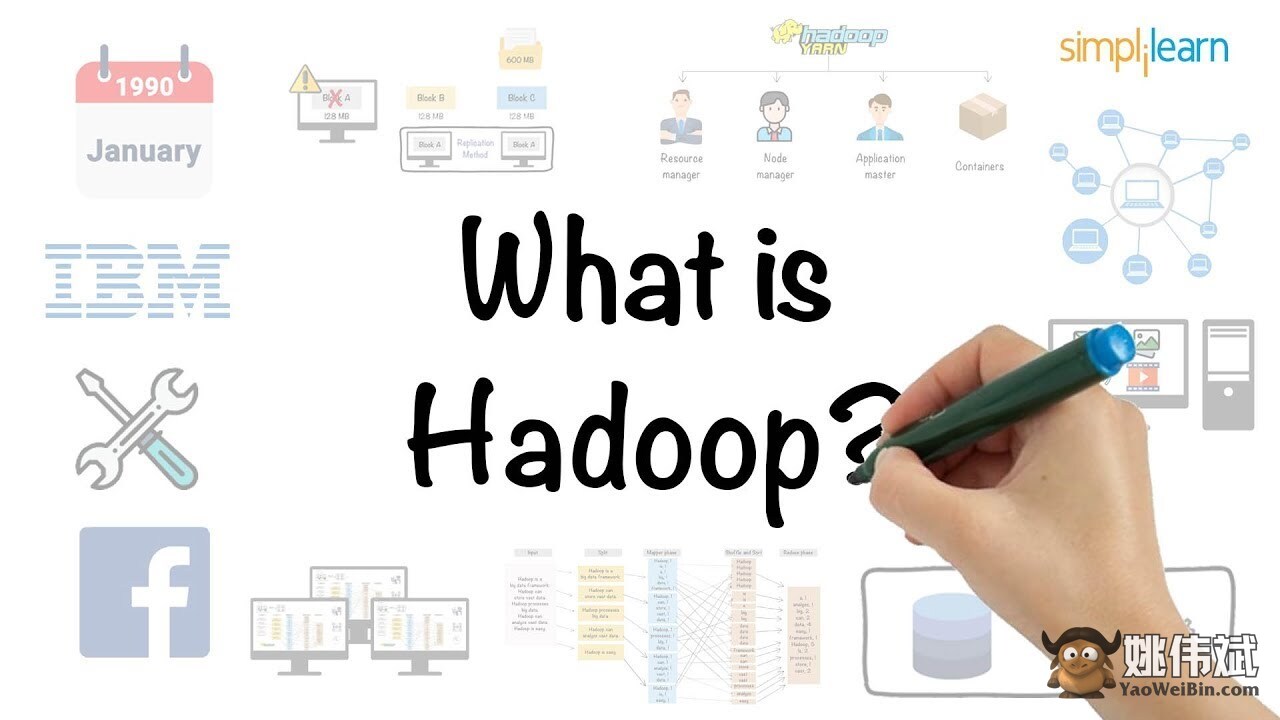
为了存储和处理数据,数据被发送到Hadoop集群,HDFS(Hadoop分布式文件系统)存储数据,MapReduce处理数据,YARN(另一种资源协商者)划分任务并分配资源。
它适用于来自各种公司和组织的数据科学家、开发人员和分析师进行研究和生产。
特点
- 数据复制:将该块的多个副本存储在不同节点中,以防错误发生时提供容错性。
- 高度可扩展:提供垂直和水平扩展性
- 与其他Apache模型、Cloudera和Hortonworks的集成
考虑参加这个精彩的在线课程。
Rapidminer
Rapidminer网站声称全球约有40,000个组织使用他们的软件来增加销售额、降低成本和避免风险。
该软件已获得多个奖项:Gartner Vision Awards 2021(数据科学和平台)、Forrester和Crowd的多模式预测分析和机器学习解决方案以及2025年春季G2报告中最用户友好的机器学习和平台。

它是一个端到端的科学生命周期平台,可以无缝地集成和优化用于构建ML(机器学习)模型。它会自动记录准备、建模和验证的每个步骤,以确保完全透明。
它是一款付费软件,有三个版本:Prep Data、Create and Validate和Deploy Model。甚至还可以免费提供给教育机构使用,全球有超过4,000所大学使用RapidMiner。
特点
- 检查数据以识别模式并修复质量问题
- 使用无代码工作流设计师和1500多种算法
- 将机器学习模型集成到现有的业务应用程序中
Tableau
Tableau提供了灵活性,可以对平台进行可视化分析、解决问题,并赋予个人和组织权力。它基于VizQL技术(用于数据库查询的可视化语言),通过直观的用户界面将拖放转换为数据查询。

Tableau于2019年被Salesforce收购。它允许链接来自SQL数据库、spreadsheets或云应用程序(如Google Analytics和Salesforce)等来源的数据。
用户可以根据业务或个人的偏好购买其版本:Creator、Explorer和Viewer,因为每个版本都有其自己的特点和功能。
它非常适合分析师、数据科学家、教育部门和企业用户,用于实施和平衡数据驱动的文化,并通过结果进行评估。
特点
- 仪表板以可视元素、对象和文本的形式提供了完整的数据概览。
- 大量的数据图表选择:直方图、Gantt charts、图表、动态图表等等
- 逐行过滤器保护以保持数据的安全和稳定
- 其架构提供可预测的分析和预测
Learning Tableau很容易。
Cloudera
Cloudera为云和数据中心提供了一个安全的大数据管理平台。它利用数据分析和机器学习将复杂的数据转化为清晰的可操作洞察。
Cloudera为私有云和混合云、数据工程、数据流、数据存储、数据科学等提供解决方案和工具。

统一的平台和多功能分析增强了数据驱动的洞察发现过程。其数据科学提供与组织使用的任何系统的连接性,不仅限于Cloudera和Hortonworks(两家公司已合作)。
数据科学家可以通过交互式数据科学工作表管理自己的活动,如分析、策划、监控和电子邮件通知。默认情况下,它是一个符合安全性要求的平台,允许数据科学家轻松访问Hadoop data and run Spark查询。
该平台适用于各行各业的数据工程师、数据科学家和IT专业人员,如医院、金融机构、电信等。
特点
- 支持所有主要的私有和公共云,而数据科学工作台支持本地部署
- 自动化数据通道将数据转换为可用的形式,并将其与其他源集成
- 统一的工作流程允许快速构建、训练和实施模型
- Hadoop身份验证、授权和链接_16的安全环境
Apache Hive
链接_17是在Apache Hadoop之上开发的开源项目。它允许读取、写入和管理各种存储库中可用的大型数据集,并允许用户结合自己的函数进行自定义分析。

Hive专为传统存储任务而设计,不适用于在线处理任务。它的强大批处理框架提供了可伸缩性、性能、可伸缩性和容错性。
它适用于数据提取、预测建模和索引文档。不推荐用于查询实时数据,因为它会引入获取结果的延迟。
功能
- 支持MapReduce、Tez和Spark计算引擎
- 处理几个拍字节大小的大型数据集
- 与Java相比编码非常简单
- 通过将数据存储在Apache Hadoop分布式文件系统中提供容错性
Apache Storm
链接_18是一个免费、开源的平台,用于处理无限数据流。它提供了最小的处理单元,用于开发能够实时处理大量数据的应用程序。

Storm的处理速度足够快,每个节点每秒可以处理一百万个元组,并且操作简单。
Apache Storm允许您向集群中添加更多节点,从而增加应用程序的处理能力。通过添加节点来实现水平可扩展性,可以将处理能力增加一倍。
数据科学家可以使用Storm进行DRPC(分布式远程过程调用)、实时ETL(检索转换加载)分析、连续计算、在线机器学习等。它被设置为满足Twitter、Yahoo和Flipboard的实时处理需求。
功能
- 与任何链接_19兼容的使用非常简单
- 它集成到每个队列系统和每个数据库中
- Storm使用Zookeeper来管理集群,并且可以扩展到更大的集群大小
- 如果出现问题,保证数据保护,替换丢失的元组
Snowflake Data Science
对于数据科学家来说,最大的挑战是准备来自不同资源的数据,因为大部分时间都花在检索、 consolida、清洁和准备数据上。通过链接_20来解决这个问题。
它提供了一个高性能的单一平台,消除了ETL(加载转换和提取)导致的麻烦和延迟。它还可以与最新的机器学习(ML)工具和库(如Dask和Saturn Cloud)集成。

Snowflake为每个工作负载提供了专用的计算集群的独特架构,用于执行此类高级计算活动,因此数据科学和BI(商业智能)工作负载之间没有资源共享。
它支持来自结构化、半结构化(链接_21、Avro、ORC、Parquet或XML)和非结构化数据的数据类型。它使用数据湖策略来改善数据访问、性能和安全性。
数据科学家和分析师在金融、媒体与娱乐、零售、健康与生命科学、技术和公共领域等各个行业使用Snowflake。
功能
- 高数据压缩以减少存储成本
- 提供静止和传输数据的数据加密
- 具有低操作复杂性的快速处理引擎
- 通过表、图表和直方图视图提供集成数据分析
Datarobot
Datarobot是云计算领域的世界领导者,拥有AI (Artificial Intelligence)。它独特的平台旨在为包括用户和不同类型的数据在内的所有行业提供服务。
该公司声称该软件被财富50强的三分之一公司使用,并在各个行业提供超过一万亿的估算值。
Dataroabot使用自动化机器学习(ML),旨在帮助企业数据专业人员快速创建、调整和部署准确的预测模型。
它使科学家能够轻松获取许多最新的机器学习算法,并完全透明地自动化数据预处理。该软件还为科学家开发了专门的R和Python客户端,以解决复杂的数据科学问题。
它有助于自动化数据质量、特征工程和实施过程,以简化数据科学家的工作。这是一个高级产品,价格可根据要求提供。
特点
- 通过简化预测,提高企业的盈利能力
- 实施过程和自动化
- 支持Python、Spark、TensorFlow和其他来源的算法。
- API集成可让您选择成百上千个模型
TensorFlow
TensorFlow是一个基于社区的AI(人工智能)库,使用数据流图构建、训练和部署机器学习(ML)应用程序。这使开发人员能够创建大型分层神经网络。

它包括三个模型——TensorFlow.js、TensorFlow Lite和TensorFlow Extended(TFX)。它的javascript模式用于在浏览器和Node.js上同时训练和部署模型。它的lite模式用于在移动和嵌入式设备上部署模型,而TFX模式用于准备数据、验证和部署模型。
由于其强大的平台,无论使用哪种编程语言,都可以将其部署在服务器、边缘设备或Web上。
TFX包含用于实施可扩展的ML管道并提供强大的整体性能任务的机制。像Kubeflow和Apache Airflow这样的数据工程管道支持TFX。
Tensorflow平台适合初学者、中级和专家,可以使用Keras训练一个generative adversarial network来生成手写数字的图像。
特点
- 可以在本地、云端和浏览器中部署ML模型,而不受语言限制
- 使用内置API轻松构建模型,以便快速重复模型
- 其各种附加库和模型支持研究活动以进行实验
- 使用多级抽象轻松构建模型
Matplotlib
Matplotlib是用于Python编程语言的可视化动态数据和图形图形的全面社区软件。其独特的设计结构使得只需几行代码即可生成可视化数据图形。
有各种第三方应用程序,如绘图程序、GUI、颜色映射、动画等,设计成与Matplotlib集成。
它的功能可以通过许多工具进行扩展,如Basemap、Cartopy、GTK-Tools、Natgrid、Seaborn等。
它的最佳特点包括使用结构化和非结构化数据绘制图形和地图。
Bigml
Bigml是一个集体、透明的平台,面向工程师、数据科学家、开发人员和分析师。它将数据转化为可操作的模型。
它有效地创建、实验、自动化和管理ML工作流,为各个行业的智能应用做出贡献。

这个可编程的ML(机器学习)平台可以帮助进行排序、时间序列预测、关联检测、回归、聚类分析等。
它具有单个和多个租户的完全可管理版本,并且可以在任何云提供商上进行部署,使企业能够轻松为每个人提供访问大数据的权限。
它的价格从30美元起,对于小型数据集和教育目的免费,并在600多所大学中使用。
由于其强大的工程化机器学习算法,它适用于制药、娱乐、汽车、航空航天、医疗保健、物联网等各个行业。
特点
- 通过单个API调用自动化耗时且复杂的工作流程。
- 它可以处理大量数据并执行并行任务。
- 该库受到流行的编程语言的支持,如Python、Node.js、Ruby、Java、Swift等。
- 其精细的详细信息使审计和监管要求的工作变得容易。
Apache Spark
它是最大的开源引擎之一,被许多大型公司广泛使用。根据该网站的说法,Spark被财富500强公司的80%所使用。它与大数据和机器学习的单节点和集群兼容。

它基于先进的SQL(结构化查询语言)来支持大量数据并处理结构化表和非结构化数据。
Spark平台以其易用性、庞大的社区和闪电般的速度而闻名。开发人员使用Spark在Java、Scala、Python、R和SQL中构建应用程序和运行查询。
特点
- 批处理和实时处理数据
- 支持大量的PB级数据而无需降采样
- 可以将多个库(如SQL、MLib、Graphx和Stream)组合成单个工作流程。
- 可以在Hadoop YARN、Apache Mesos、Kubernetes以及云中工作,并且可以访问多个数据源。
Knime
Konstanz Information Miner是一个直观的开源平台,用于数据科学应用。数据科学家和分析师可以使用简单的拖放功能创建可视化工作流程,无需编码。
服务器版本是用于自动化、数据科学管理和管理分析的交易平台。KNIME使数据科学工作流程和可重用组件对所有人都可访问。
特点
- 非常灵活,可以集成来自Oracle、SQL、Hive等的数据
- 可以从多个源(如SharePoint、Amazon Cloud、Salesforce、Twitter等)访问数据
- 使用ml进行模型构建、性能调优和模型验证。
- 通过可视化、统计、处理和报告提供数据洞察。
大数据的5个V的重要性是什么?
大数据的5个V帮助数据科学家理解和分析大数据以获取更多洞察。它还有助于提供对企业有用的更多统计信息,以便做出明智的决策并获得竞争优势。
Volume(体积):大数据基于体积。量子体积确定数据的规模。通常包含以TB、PB等为单位的大量数据。基于体积大小,数据科学家计划各种工具和数据集分析的集成。
Velocity(速度):数据收集的速度至关重要,因为一些公司需要实时数据信息,而其他公司则更喜欢按数据包处理数据。数据流越快,数据科学家就能够评估更多数据并向公司提供相关信息。
Variety(多样性):数据来自不同的来源,而且重要的是,并非以固定格式存在。数据以结构化(数据库格式)、半结构化(XML/RDF)和非结构化(二进制数据)格式可用。基于数据结构,使用大数据工具来创建、组织、过滤和处理数据。
准确性:数据准确性和可信的来源定义了大数据的背景。数据集来自于各种来源,例如计算机、网络设备、移动设备、社交媒体等。因此,数据必须经过分析后才能发送到目标地。
价值:最后,一家公司的大数据价值是多少?数据科学家的角色是最好地利用数据,展示数据见解如何为业务增加价值。
结论 👇
上述大数据列表包括付费工具和开源工具。每个工具都提供简要信息和功能。如果您想了解详细信息,可以访问相关网站。
希望获取竞争优势的公司利用大数据和相关工具,如人工智能(AI)、机器学习(ML)和其他技术,采取战术行动来进行研究、营销、未来规划等。
大数据工具在大多数行业中都得到应用,因为生产力的微小变化可能会转化为巨大的节省和利润。希望上面的文章给您提供了大数据工具及其重要性的概述。
您可能还喜欢:
Online courses to learn the basics of Data Engineering。