

最好的Python库供数据科学家使用

这篇文章提及并阐述了一些最好的python库,供数据科学家和机器学习团队使用。
python是一个理想的语言,主要用于这两个领域,因为它提供了许多库。
这是因为python库的应用,如数据输入/输出(i/o)和数据分析等数据操作,数据科学家和机器学习专家用来处理和探索数据。
python库,它们是什么?
python库是一个包含了预编译代码(包括类和方法)的广泛集合,消除了开发人员需要从头实现代码的需要。
python在数据科学和机器学习中的重要性
它的语法简单,因此能够高效实现复杂的机器学习算法。此外,简单的语法缩短了学习曲线,使理解更容易。
python支持快速原型开发和平滑的应用测试。
python庞大的社区对于数据科学家在需要时能够迅速寻求解决方案非常有用。
python库有多有用?
python库在机器学习和数据科学中创建应用程序和模型方面非常有用。
这些库在帮助开发人员实现代码重用方面起到了很大的作用。因此,您可以导入一个相关的库,该库实现了程序中的特定功能,而不是重复造轮子。
机器学习和数据科学中使用的python库
数据科学家推荐数据科学爱好者必须熟悉的各种python库。根据它们在应用中的相关性,机器学习和数据科学专家应用不同的python库,分为用于部署模型、挖掘和抓取数据、数据处理和数据可视化的库。
本文介绍了数据科学和机器学习中常用的一些python库。
现在让我们来看看它们。
numpy
numpy python库,全称为numerical python code,是由优化的c代码构建而成。数据科学家喜欢它,因为它能进行深入的数学计算和科学计算。
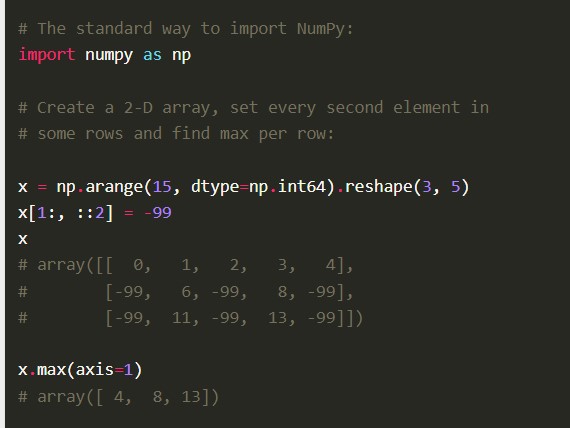
特点
- numpy具有高级语法,使有经验的程序员容易上手。
- 由于其组成部分的优化的c代码,该库的性能相对较高。
- 它具有数值计算工具,包括傅里叶变换功能、线性代数和随机数生成器。
- 它是开源的,因此允许其他开发人员进行大量贡献。
numpy还具有其他综合特性,如数学运算的向量化、索引和实现数组和矩阵的关键概念。
pandas
pandas是一个著名的机器学习库,它提供了高级数据结构和众多工具,可以轻松有效地分析大规模数据集。这个库可以用非常少的命令来处理复杂的数据操作。
这个库包含了许多内置方法,可以对数据进行分组、索引、检索、拆分、重构和过滤,然后将它们插入到单维和多维表中。
pandas库的主要特点
- pandas可以将数据标签化并自动对齐和索引数据。
- 它可以快速加载和保存json和csv等数据格式。
它的数据分析功能和高度灵活性使其非常高效。
matplotlib
matplotlib是一个2d图形化python库,可以轻松处理来自多个来源的数据。它创建的可视化图形是静态的、动画的和交互式的,用户可以放大查看,因此非常适合可视化和创建图表。它还允许自定义布局和可视化样式。
它的文档是开源的,并提供了一个丰富的工具集,可以用于实现。
matplotlib导入了辅助类来实现年、月、日和周,使得操作时间序列数据更加高效。
scikit-learn
如果您正在考虑使用一个库来处理复杂的数据,那么scikit-learn应该是您的理想库。机器学习专家广泛使用scikit-learn。该库与numpy、scipy和matplotlib等其他库相关联。它提供了用于生产应用的监督和无监督学习算法。
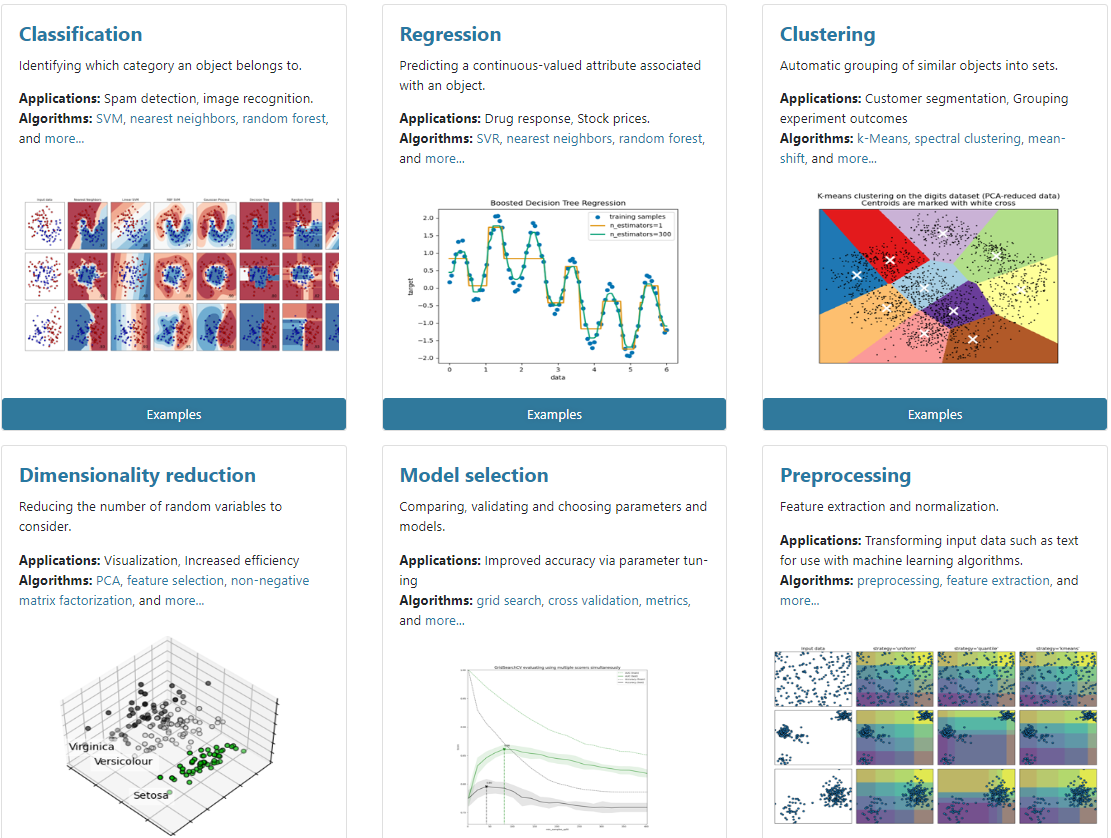
scikit-learn python库的特点
- 识别对象类别,例如在图像识别等应用中使用svm和随机森林等算法。
- 预测与任务相关联的连续值属性。
- 特征提取。
- 降低考虑的随机变量数量的维度。
- 将相似的对象聚类到集合中。
scikit-learn库在从文本和图像数据集中提取特征方面非常高效。此外,还可以在未见数据上检查监督模型的准确性。它提供了众多可用的算法,可以进行数据挖掘和其他机器学习任务。
scipy
scipy(scientific python code)是一个机器学习库,提供了应用于数学函数和算法的模块,具有广泛的适用性。它的算法可以解决代数方程、插值、优化、统计和积分。
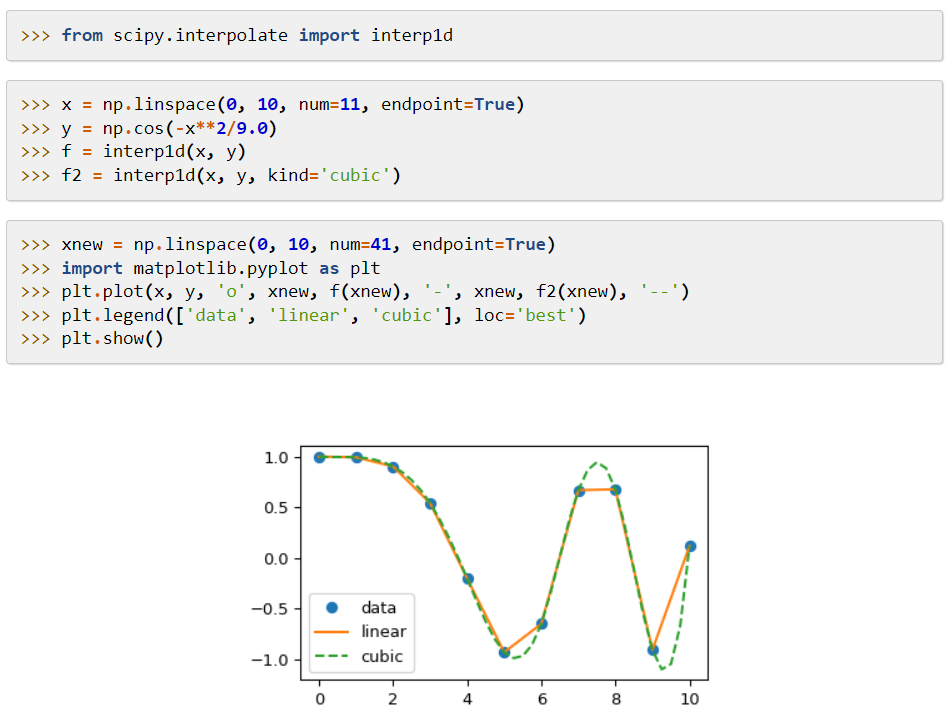
它的主要特点是扩展了numpy,添加了解决数学函数和提供稀疏矩阵等数据结构的工具。
scipy使用高级命令和类来操作和可视化数据。它的数据处理和原型系统使其成为一个更加有效的工具。
此外,scipy的高级语法使得任何经验水平的程序员都可以轻松使用。
scipy唯一的缺点是它仅关注数值对象和算法,因此无法提供任何绘图功能。
pytorch
这个多样化的机器学习库高效地利用gpu加速来实现张量计算,创建动态的计算图和自动梯度计算。torch库是一个开源的机器学习库,是基于c语言开发的,并构建了。
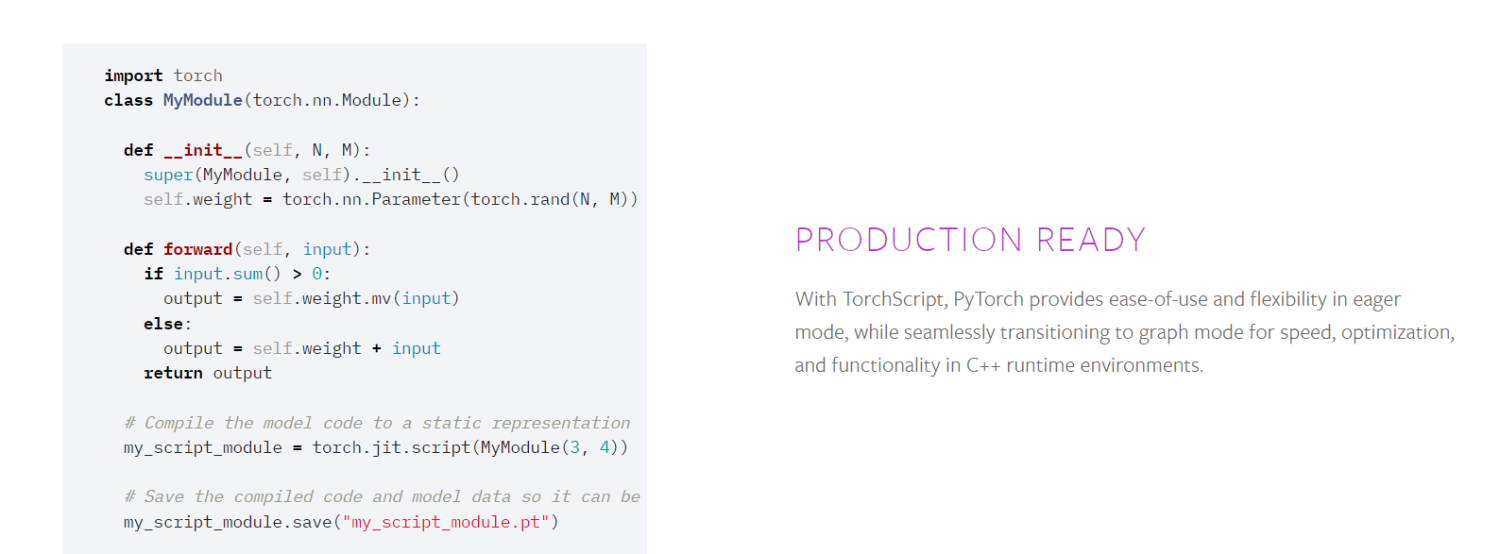
主要特点包括:
- 由于在主要云平台上得到良好支持,提供了无摩擦的开发和平滑的扩展。
- 稳健的工具和库生态系统支持计算机视觉开发和其他领域,如自然语言处理(nlp)。
- 它通过torch script提供了从急切模式到图模式的平滑过渡,同时使用torchserve加快了进入生产环境的速度。
- torch分布式后端允许在研究和生产中进行分布式训练和性能优化。
您可以在开发nlp应用程序中使用<pytorch。
keras
keras是一个开源的机器学习python库,用于实验深度神经网络。
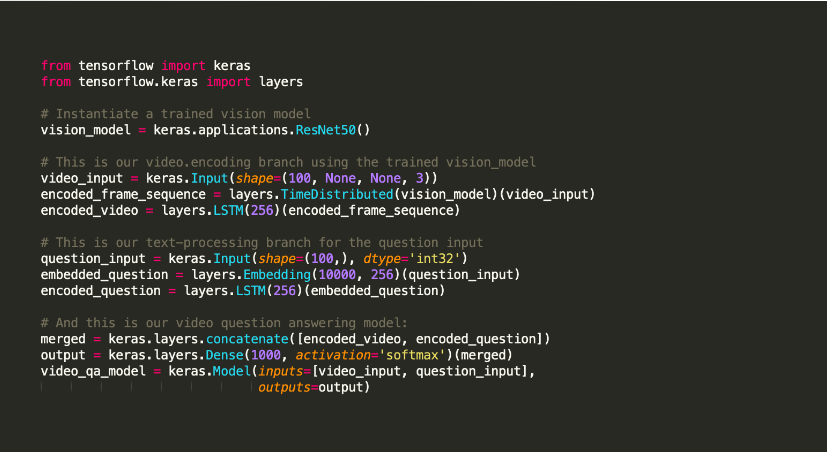
它以提供支持模型编译和图形可视化等任务的实用工具而闻名。它使用tensorflow作为后端,或者您可以在后端使用theano或类似cntk的神经网络。这个后端基础设施帮助它创建用于实现操作的计算图。
该库的主要特点
- 它可以在中央处理器和图形处理器上高效运行。
- 由于基于python,使用keras进行调试更加容易。
- keras是模块化的,因此更具表现力和适应性。
- 您可以通过直接将其模块导出到javascript,并在浏览器上运行来在任何地方部署keras。
keras的应用包括神经网络构建模块,如层和目标等工具,以及有助于处理图像和文本数据的其他工具。
seaborn
seaborn是另一个在统计数据可视化中有价值的工具。
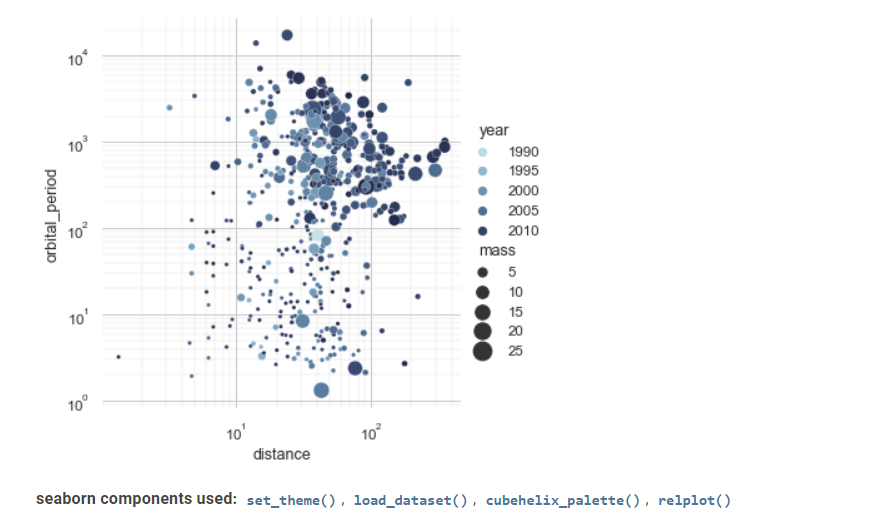
它的高级界面可以实现引人注目且信息丰富的统计图形绘制。
plotly
plotly是一个基于plotly js库构建的3d网络可视化工具。它对各种图表类型(如折线图、散点图和箱形图)有广泛的支持。
它的应用包括在jupyter笔记本中创建基于web的数据可视化。
plotly适用于可视化,因为它可以使用其悬停工具指出图表中的异常值或异常情况。您还可以自定义图表以适应您的偏好。
plotly的缺点是它的文档已经过时,因此对于用户来说,使用它作为指南可能会很困难。此外,它有许多工具用户需要学习。跟踪所有这些工具可能是具有挑战性的。
plotly python库的特点
- 它提供的3d图表允许多点交互。
- 它具有简化的语法。
- 您可以在保持代码私密性的同时共享您的数据点。
simpleitk
simpleitk是一个图像分析库,提供了与insight toolkit(itk)的接口。它基于c++,是开源的。
simpleitk库的特点
- 其图像文件i/o支持并可以转换多达20种图像文件格式,如jpg、png和dicom。
- 它提供了许多图像分割工作流滤波器,包括otsu、水平集和分水岭。
- 它将图像解释为空间对象,而不是像素数组。
其简化的接口可用于各种编程语言,如r、c#、c++、java和python。
statsmodel
statsmodel估计统计模型,实现统计检验和使用类和函数探索统计数据。
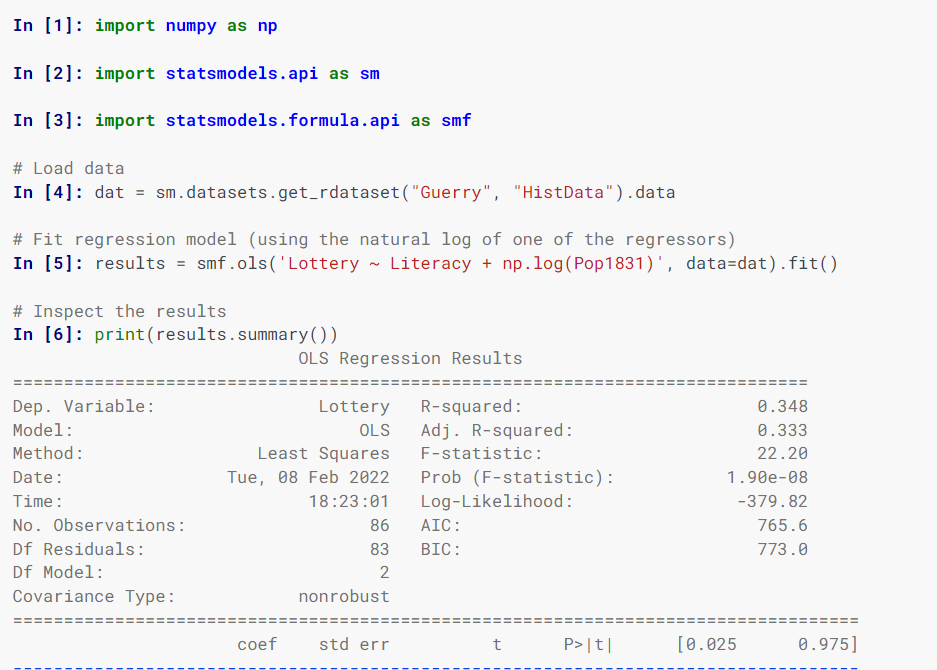
使用r风格的公式、numpy数组和pandas数据框来指定模型。
scrapy
这个开源包是从网站中检索(抓取)和爬行数据的首选工具。它是异步的,因此相对较快。 scrapy具有高效的架构和功能。
不足之处在于,它的安装对于不同的操作系统有所不同。此外,您不能在使用js构建的网站上使用它。另外,它只能与python 2.7或更高版本一起使用。
数据科学专家在数据挖掘和自动化测试中应用它。
特点
- 它可以将订阅以json、csv和xml导出并存储在多个后端中。
- 它具有从html/xml源收集和提取数据的内置功能。
- 您可以使用定义良好的api来扩展scrapy。
pillow
pillow是一个python图像处理库,用于操作和处理图像。
它为python解释器添加了图像处理功能,支持各种文件格式,并提供了出色的内部表示。
由于pillow的存在,可以轻松访问存储在基本文件格式中的数据。
总结
这就是我们对一些最好的python库进行数据科学家和机器学习专家的探索。
正如本文所示,python还有更多有用的机器学习和数据科学包。python还有其他可以应用于其他领域的库。
您可能想了解一些最佳数据科学笔记本。
祝学习愉快!






