12个最佳的协作数据科学笔记本【Jupyter替代品】

在这篇文章中,你将找到一些最好的数据科学笔记本,以提升团队的工作流程。这些数据科学笔记本有助于更好的协作,并可作为Jupyter笔记本的替代品。
在本指南中,我们将讨论经典Jupyter笔记本在数据科学项目中的使用。然后,我们将介绍其他笔记本。另外,我们还将列举这些笔记本的特点。
让我们开始吧。
数据科学的Jupyter笔记本
Jupyter notebook是一个用于数据科学项目的交互式基于Web的平台。除了提供Python、Scala和R等编程语言的内核外,Jupyter笔记本还具有其他有价值的功能。
以下是Jupyter的一些特点:
- 添加数学方程、富文本和媒体
- 支持数据收集、清洗、分析和可视化
- 构建和解释机器学习模型
我们还为您准备了一份关于Jupyter notebooks for data science的指南。它将介绍Jupyter笔记本的特点,并帮助您设置工作环境。
然而,当您开始扩展并作为团队处理大型data science projects时,您可能还希望考虑其他选择。
现在让我们看看其他可以考虑的data science笔记本。它们提供与Jupyter笔记本相同的功能,并且还能促进无缝协作,并提供更多的灵活性和定制化。
如果您有兴趣学习Python和Jupyter,请查看此链接。
请转到以下部分了解更多信息。
Deepnote
Deepnote是一个基于云的Jupyter笔记本环境。它旨在允许团队有效地进行协作。
您可以免费开始并作为个人建立自己的数据科学作品集。或者您可以作为团队的一部分来工作。
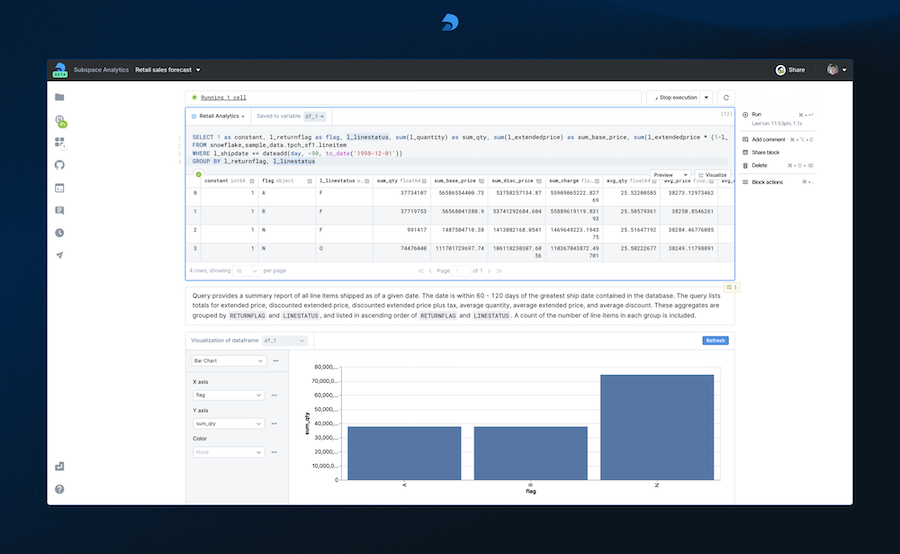
现在,让我们列出Deepnote的一些有用功能:
- 提供从BigQuery、Snowflake和PostgreSQL等数据库查询数据的功能
- 在同一个笔记本界面中使用SQL和Python,而无需切换应用程序
- 支持Python、Julia和R等流行的编程语言
- 支持PyTorch和TensorFlow等深度学习框架
- 通过创建自定义环境或从DockerHub导入现有环境来确保团队之间的可复制性
Apache Zeppelin
Apache Zeppelin是一个基于Web的笔记本,可在浏览器中进行交互式和协作式的数据分析。这些笔记本非常适合作为团队进行大数据分析。
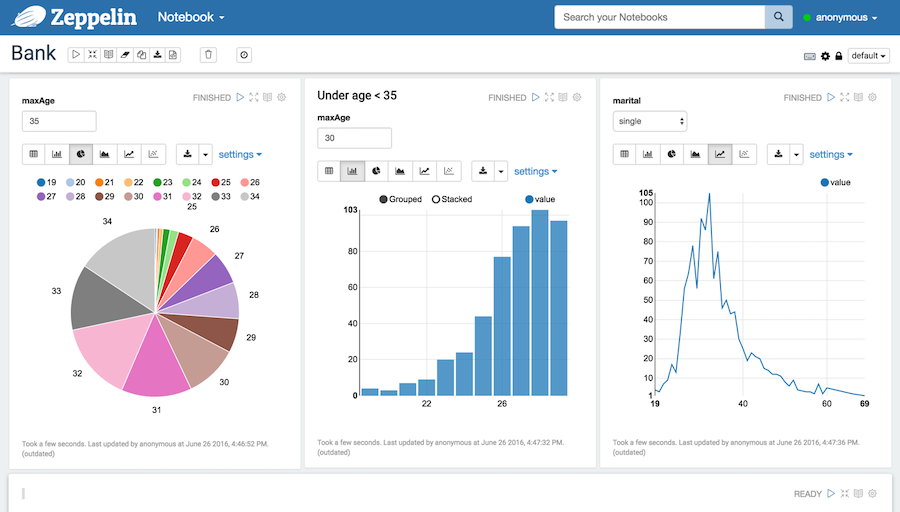
以下是Apache Zeppelin笔记本的特点概述:
- 多用途笔记本,可用于数据科学流程的各个阶段
- 支持Python、SQL、R、Shell、Apache Spark和Apache Flink等多种语言和框架
- 内置Apache Spark集成,用于大数据分析
- 提供创建动态输入表单的功能
Mode Notebooks
Mode Notebooks是Mode Analytics的旗舰产品,可以在团队之间进行协作,并遵循数据叙事的最佳实践。
在大多数数据科学项目中,数据收集阶段涉及从数据库中查询所需数据。Mode Notebooks允许您使用SQL查询连接的数据源中的数据。
Mode笔记本的一些有用功能包括:
- 提供编写SQL查询数据库的功能
- 对获取的数据进行数据分析
- 使用Mode笔记本扩展现有分析
- 创建可共享的Python和R笔记本
总之,如果您的工作流程以编写SQL查询开始,则Mode笔记本是一个很好的选择。然后,您可以扩展到使用Python和R进行分析。
JetBrains Datalore
JetBrains Datalore也为团队的数据科学需求提供了强大的Jupyter笔记本环境。
在开发方面,Datalore包括了编码辅助功能,具有智能代码编辑器。它还允许团队使用多个数据源。此外,还提供了增强的协作和报告功能。
以下是Datalore功能的全面概述:
- 用于Python、Scala和SQL等语言的编程环境
- 与不同的数据源一起工作,并将数据和文件上传到云端
- 在笔记本环境中挂载S3存储桶
- 在工作区中报告和组织团队的工作
- 添加检查点以恢复到以前的版本
- 与团队成员共享协作
- 将Datalore单元嵌入到社交媒体网站、交互式图表、发布等中
Google Colab
来自Google研究的Google Colab是一个基于Web的Jupyter笔记本环境,可以通过免费的Google账号在浏览器中访问。如果您是数据科学爱好者,Google Colab可能是开始构建项目的好方式。
您已经在数据科学项目中使用Colab了吗?如果是的话,请查看此视频教程,了解您应该使用的Colab的酷功能。

Google Colab还具有以下显著特点:
- 从各种来源导入数据和文件
- 将笔记本自动保存到Google Drive
- 与GitHub集成以便进行版本控制
- 预安装了scikit-learn、pandas和PyTorch等数据科学库
- 在免费套餐的限制下,可以访问GPU资源,可通过获得扩展的计算资源访问
Nextjournal
Nextjournal是另一个协作数据科学笔记本。在数据科学项目和研究中,跨具有不同操作系统和硬件配置的计算机实现结果的可重复性是一项具有挑战性的任务。
作为“可重复研究的笔记本”的口号,Nextjournal侧重于实时协作和可重复性。
以下是Nextjournal独特的一些功能:
- 将整个文件系统创建和共享为docker镜像
- 由单独的应用程序协同管理的Docker容器
- 在单个运行时中使用多种编程语言的能力
- 项目期间进行安装的Bash环境
- 通过最小必要的设置支持GPU
因此,如果您想要重现机器学习研究论文的结果,Nextjournal可能是您的理想选择。
Count
Count提供了一个具有灵活性的定制功能的数据科学笔记本。使用Count笔记本,您可以选择将数据分析结果呈现为KPI报告、深入报告或内部应用程序。
Count的设计目标是改变数据团队的工作方式。他们的愿景是提供一个连接分析师和利益相关者的协作数据平台。
Count的旗舰SQL笔记本具有以下功能:
- 与多个数据库的无缝集成
- 通过连接到多个数据库(如BigQuery、PostgreSQL和MySQL)构建更快的查询
- 提供即时数据可视化
Hex
Hex是另一个提供协作数据工作空间的Jupyter替代品,它为Python和SQL提供了协作笔记本界面。它可以使团队在数据科学项目的构思和分析之间更快地切换。
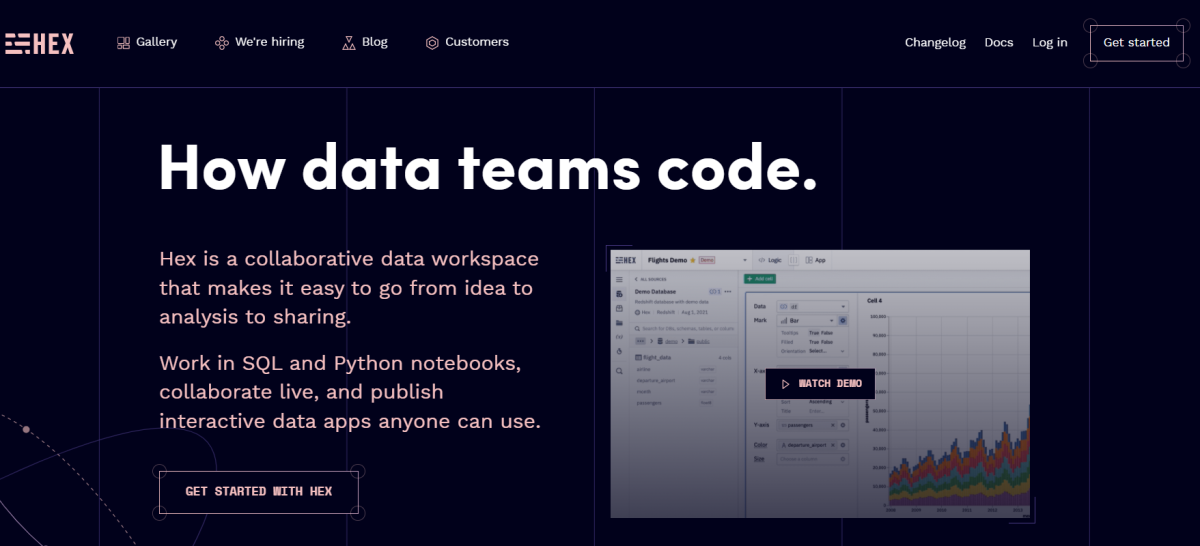
Hex笔记本的一些特点包括:
- 浏览数据库架构
- 编写SQL查询,并在数据框上运行数据分析
- 实时协作,版本控制和代码补全
- 与Snowflake、BigQuery和RedShift的大数据集成
- 将分析发布为交互式数据应用
因此,您可以使用Hex来简化与数据库的连接和查询。
Kaggle
Kaggle还提供了一个基于Web的Jupyter笔记本环境,旨在确保可再现和协作分析。
这些笔记本可以是展示数据科学项目的绝佳方式。它还有助于从浏览器开始建立数据科学项目的组合。
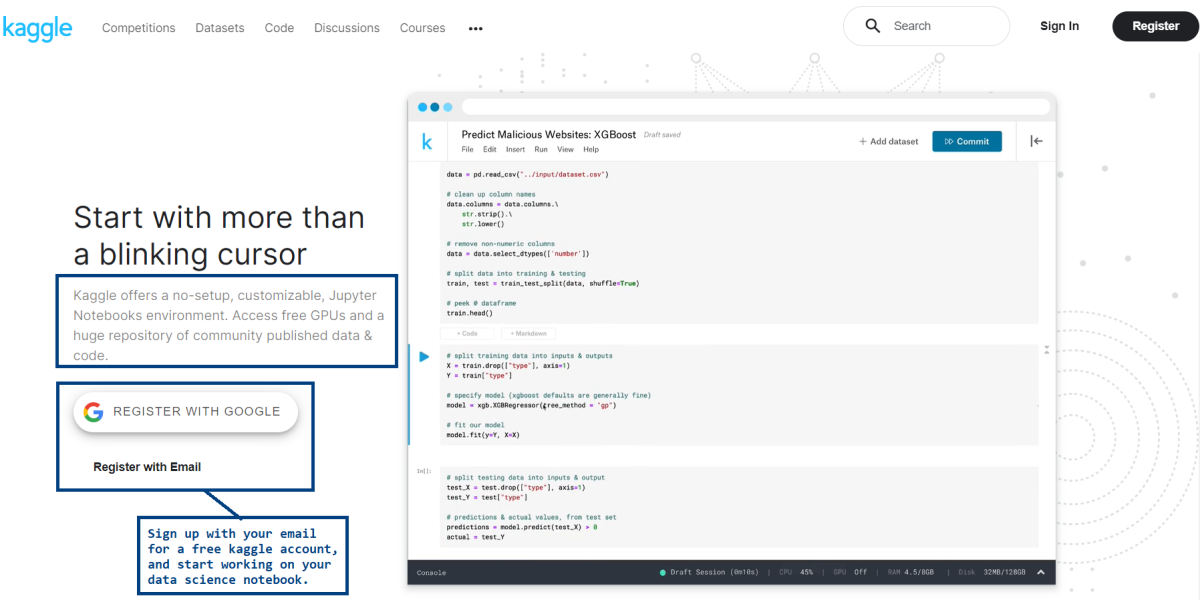
Kaggle提供以下两种版本:
- 脚本:脚本可以是Python或R脚本。如果您是R用户,还可以考虑使用附加的RMarkdown脚本。
- 笔记本:笔记本提供了一个基于浏览器的Jupyter笔记本环境,可访问硬件加速器、数据集等。
笔记本界面允许您管理数据集和硬件加速器。一旦您在Kaggle上发布了一个笔记本,所有社区成员都可以在浏览器中交互式地运行您的笔记本。
您可以使用Kaggle托管的所有数据集或来自竞赛的数据集。
参与Kaggle competitions将帮助您更迅速地提升数据科学技能。以下是一个关于如何开始使用Kaggle的视频教程。
Databricks笔记本
Databricks notebooks也是协作的数据科学笔记本。
与我们迄今见过的大多数其他数据科学笔记本一样,这些笔记本也支持访问不同的数据源。此外,它们还支持交互式数据可视化和多种编程语言。
此外,Databricks笔记本还支持实时共同创作和版本控制。
▶观看此视频教程以开始使用Databricks笔记本。

以下是这些笔记本的一些独特特点:
- 由Spark驱动的数据仪表板
- 作业调度程序,用于扩展运行数据管道
- 笔记本工作流程,用于多阶段管道
- 将笔记本连接到集群以加快计算速度
- 与Tableau、Looker、PowerBI等工具集成
CoCalc
CoCalc提供了一个适用于学术用途的Jupyter笔记本环境。除了经典Jupyter笔记本的功能外,CoCalc还提供了集成的课程管理系统。
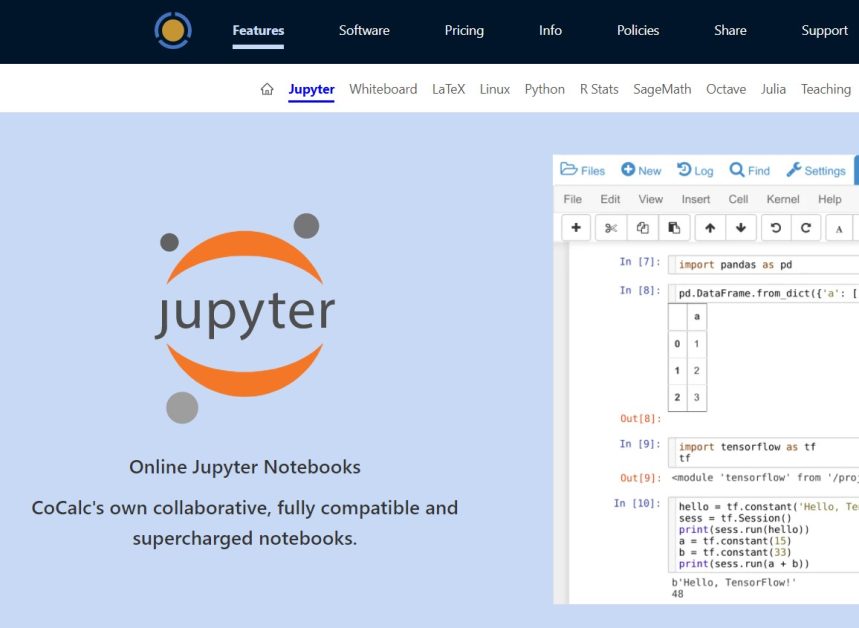
让我们列举一些使CoCalc适用于教授数据科学并促进实时同步的功能。
- 从学生提交的文件中收集所有文件
- 使用NBGrader自动评分学生提交
- Python、R统计软件和Julia的内核在学术界广泛使用
Observable
Observable notebook是另一个用于数据科学团队的协作平台。
Observable旨在汇集数据分析师、开发人员和决策者,以及促进团队之间的无缝协作。
以下是Observable笔记本提供的一些很酷的功能:
- 复制现有项目,以最小的设置立即开始
- 可视化和UI组件,便于探索数据
- 发布和导出笔记本,并将代码嵌入网页中
- 安全链接共享协作
总结
我希望您会发现这个数据科学笔记本的清单有帮助。如果您想促进团队内部和团队之间的合作,现在您有一份可以选择的数据科学笔记本清单。此外,适当的工具可以帮助团队有效地协作!
从big data analysis到学术界和可重复研究,您可以针对许多用例找到专门定制的数据科学笔记本。愉快的teamwork和协作的数据科学!🤝