

如何安装Beautiful Soup并在网络爬虫项目中使用它?

在当今数据驱动的世界中,传统的手动数据采集方法已经过时。每台桌子上都有一台连接互联网的计算机,使得网络成为了一个巨大的数据来源。因此,更高效和节省时间的现代数据采集方法是网络爬虫。而当谈到网络爬虫时,Python有一个被称为Beautiful Soup的工具。在本文中,我将为您介绍安装Beautiful Soup的步骤,以便开始进行网络爬虫。
在安装和使用Beautiful Soup之前,让我们先了解一下为什么您应该选择它。
Beautiful Soup是什么?
假设您正在研究“COVID对人们健康的影响”,并找到了一些包含相关数据的网页。但是如果它们没有提供单击下载选项来借用他们的数据怎么办?这时就需要Beautiful Soup登场了。
Beautiful Soup是Python库的索引之一,用于从目标站点中提取数据。它更方便地从HTML或XML页面中提取数据。
Leonard Richardson在2004年提出了Beautiful Soup用于网络爬虫的想法。但是他对该项目的贡献一直持续到今天。他自豪地在Twitter账号上更新每个Beautiful Soup的新版本发布。
尽管Beautiful Soup用于网络爬虫是使用Python 3.8开发的,但它也与Python 3和Python 2.4完美兼容。

通常,网站使用验证码保护来防止其数据被AI工具获取。在这种情况下,通过在Beautiful Soup中对‘user-agent'标头进行一些更改或使用Captcha-solving APIs可以模拟一个可靠的浏览器并欺骗检测工具。
然而,如果您没有时间去了解Beautiful Soup,或者希望以高效和轻松的方式完成爬取工作,那么您不应该错过检查这个web scraping API,在那里您只需提供一个URL,就能获取数据。
如果您已经是一名程序员,使用Beautiful Soup进行爬取将不会令人生畏,因为它具有直观的语法,可以浏览网页并根据条件解析提取所需数据。与此同时,它也非常适合新手。
尽管Beautiful Soup不适用于高级爬取,但它在从标记语言编写的文件中提取数据方面效果最佳。
清晰而详细的文档是Beautiful Soup获得的另一个优点。
让我们找到一种简单的方法将Beautiful Soup引入您的机器。
如何安装Beautiful Soup进行网络爬虫?
Pip – 一个简单的Python包管理器,于2008年开发,现在已成为开发人员安装任何Python库或依赖项的标准工具。
Pip默认随最新版Python的安装一起提供。因此,如果您的系统上已安装了最近版本的Python,您可以开始使用。
打开命令提示符并键入以下pip命令即可立即安装Beautiful Soup。
pip install beautifulsoup4您将在显示器上看到类似于以下截图的内容。
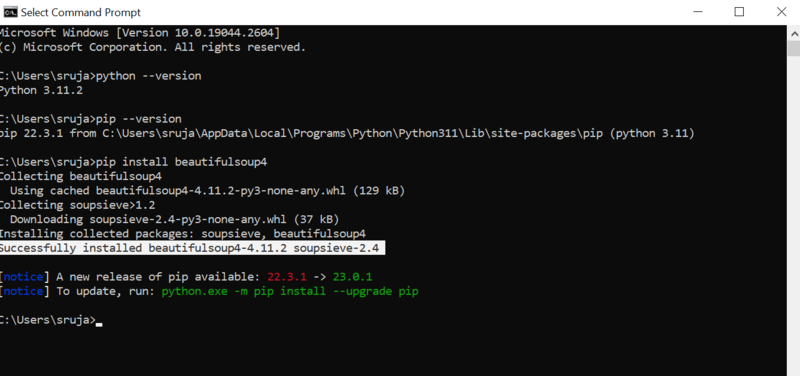
确保将PIP安装程序更新到最新版本,以避免常见错误。
更新PIP安装程序到最新版本的命令是:
pip install --upgrade pip我们在本文中已经成功完成了一半的工作。
现在您的机器上已经安装了Beautiful Soup,让我们深入了解如何使用它进行网络爬虫。
如何导入和使用Beautiful Soup进行网络爬虫?
在您的python IDE中键入以下命令,将beautiful Soup导入当前的python脚本中。
from bs4 import BeautifulSoup现在Beautiful Soup就在您的Python文件中可供爬取使用。
让我们看一个代码示例,了解如何使用beautiful Soup提取所需数据。
我们可以告诉Beautiful Soup在源网站中查找特定的HTML标签,并提取这些标签中的数据。
在本文中,我将使用marketwatch.com,它会更新各个公司的实时股票价格。让我们从这个网站上提取一些数据,以熟悉Beautiful Soup库。
导入“requests”包,这样我们就可以接收和响应HTTP请求,并使用“urllib”从URL加载网页。
from urllib.request import urlopen
import requests将网页链接保存在一个变量中,以便稍后可以轻松访问。
url = 'https://www.marketwatch.com/investing/stock/amzn'接下来,使用“urllib”库的“urlopen”方法将HTML页面存储在一个变量中。将URL传递给“urlopen”函数,并将结果保存在一个变量中。
page = urlopen(url)创建一个Beautiful Soup对象,并使用“html.parser”解析所需的网页。
soup_obj = BeautifulSoup(page, 'html.parser')现在,目标网页的整个HTML脚本都存储在“soup_obj”变量中。
在继续之前,让我们查看目标页面的源代码,以了解有关HTML脚本和标签的更多信息。
使用鼠标右键单击网页上的任何位置。然后,您会找到一个检查选项,如下图所示。
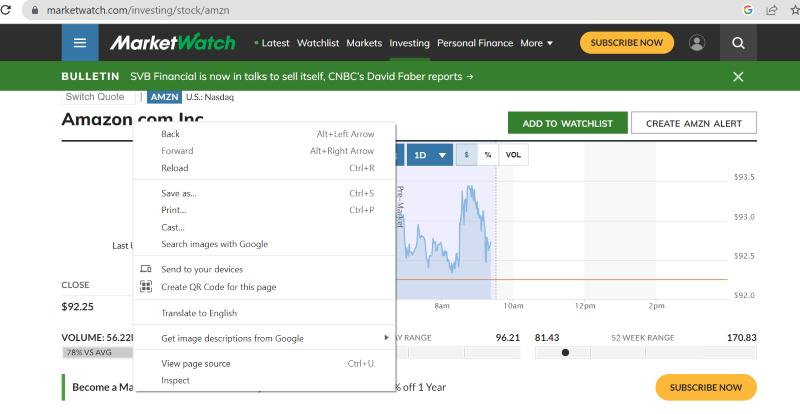
单击检查以查看源代码。
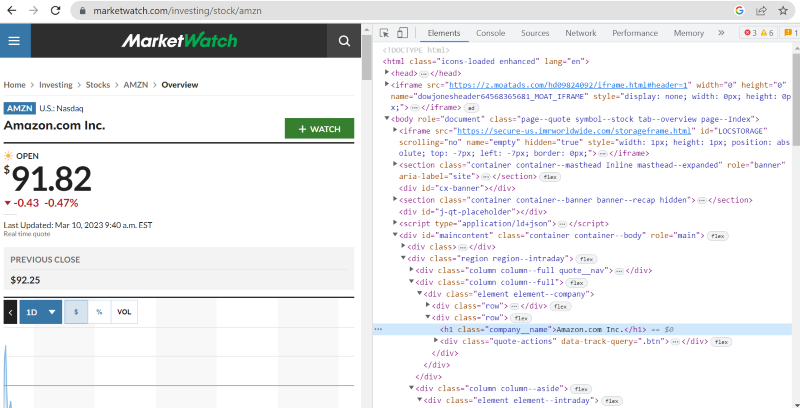
在上面的源代码中,您可以找到标签、类别和有关网站界面上每个元素的更具体信息。
Beautiful Soup中的“find”方法允许我们搜索所请求的HTML标签并提取数据。为此,我们给出类名和标签给提取特定数据的方法。
例如,网页上显示的“亚马逊公司”具有类名:“company__name”,标签为:“h1”。我们可以将此信息输入到“find”方法中,以将相关的HTML片段提取到一个变量中。
name = soup_obj.find('h1', attrs={'class': 'company__name'})让我们在屏幕上输出存储在变量“name”中的HTML脚本和所需的文本。
print(name)
print(name.text)
您可以看到提取的数据打印在屏幕上。
网络爬取IMDb网站
在观看电影之前,我们很多人都会在IMBb网站上寻找电影评级。这个演示将给你一个排名前的电影列表,并帮助你熟悉用于网络爬取的Beautiful Soup。
第1步:导入Beautiful Soup和requests库。
from bs4 import BeautifulSoup
import requests第2步:让我们将要爬取的URL分配给一个名为“url”的变量,以便在代码中轻松访问。
使用“requests”包来从URL获取HTML页面。
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')第3步:在下面的代码片段中,我们将解析当前URL的HTML页面,以创建Beautiful Soup的对象。
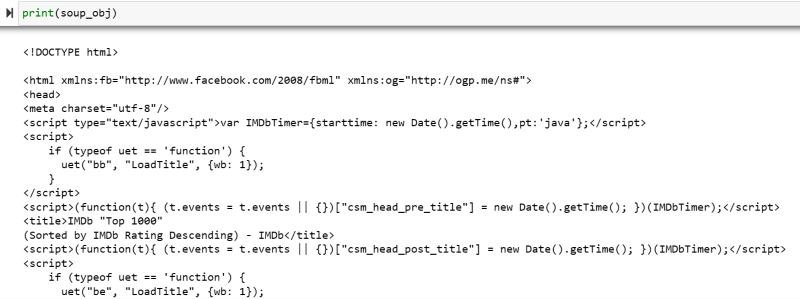
soup_obj = BeautifulSoup(url.text, 'html.parser')变量“soup_obj”现在包含所需网页的整个HTML脚本,如下图所示。
让我们检查网页的源代码,找到我们想要抓取的HTML脚本数据。
将光标悬停在您想要提取的网页元素上。然后,右键单击它,选择检查选项以查看该特定元素的源代码。以下视觉效果将更好地指导您。
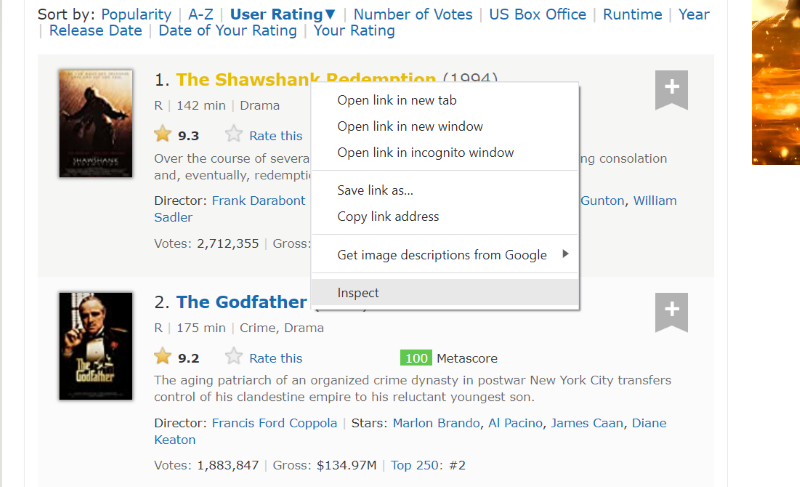
类别' lister-list ‘在连续的div标签中包含所有排名前的电影相关数据的子分区。
在每个电影卡的HTML脚本中,在类别“lister-item mode-advanced”下,我们有一个存储电影名称,排名和发布年份的“h3”标签,如下图所示。
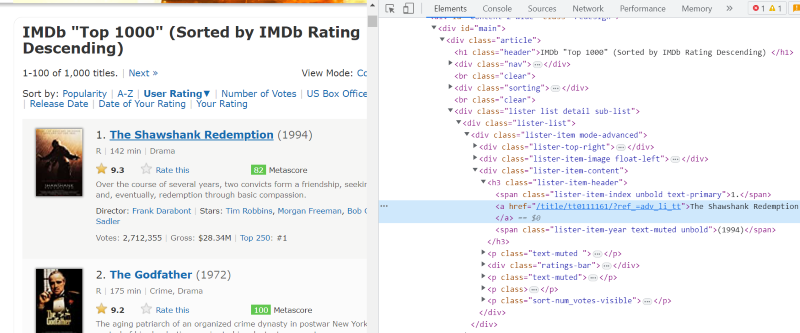
注意:beautiful Soup中的“find”方法搜索与给定输入名称匹配的第一个标签。与“find”不同,“find_all”方法查找与给定输入匹配的所有标签。
步骤4:您可以使用“find”和“find_all”方法将每部电影的名称,排名和年份的HTML脚本保存在列表变量中。
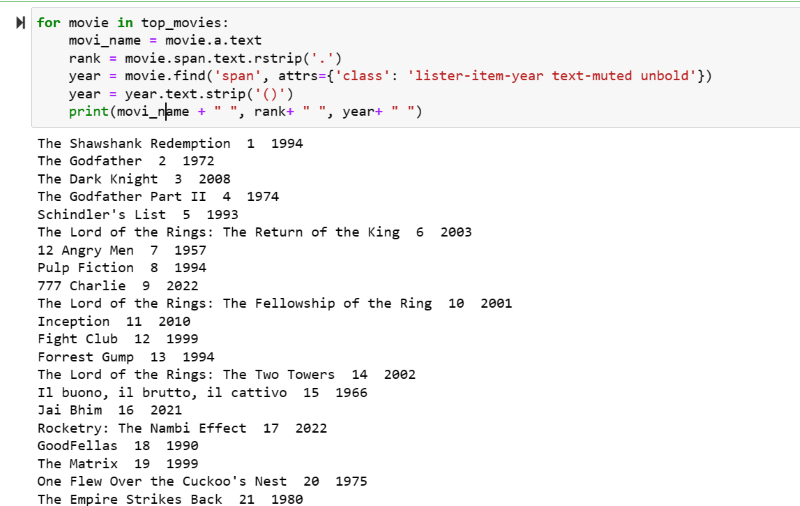
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')步骤5:循环遍历存储在变量“top_movies”中的电影列表,并使用以下代码从其HTML脚本中以文本格式提取每部电影的名称,排名和年份。
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")在输出截图中,您可以看到电影列表及其名称,排名和发布年份。
您可以轻松将打印的数据移入一个Excel表格中,并使用一些Python代码对其进行分析。
最后
本文指导您安装beautiful Soup进行网络抓取。此外,我展示的抓取示例应该可以帮助您开始使用Beautiful Soup。
由于您对如何安装Beautiful Soup进行网络抓取感兴趣,我强烈建议您查看这份详尽的指南以了解更多信息:web scraping using Python






