

Apache Kafka 在5分钟或更短的时间内解释清楚

随着越来越多的公司使用实时大数据来获取洞察并做出数据驱动的决策,对于处理这些数据的弹性工具的需求也在增加。
apache kafka是一个用于大数据系统的工具,因为它能够处理高吞吐量和实时处理大量数据。
什么是apache kafka
apache kafka 是一种开源软件,它使得存储和处理数据流成为可能。它提供了多种界面,用于将数据写入kafka集群,并从第三方系统读取、导入和导出数据。

apache kafka最初是作为linkedin的消息队列开发的。作为apache软件基金会的一个项目,这个开源软件已经发展成为一个具有广泛功能的强大的流式平台。
该系统基于一个以集群为中心的分布式架构,其中包含多个主题,优化了实时处理大数据流,如下图所示:
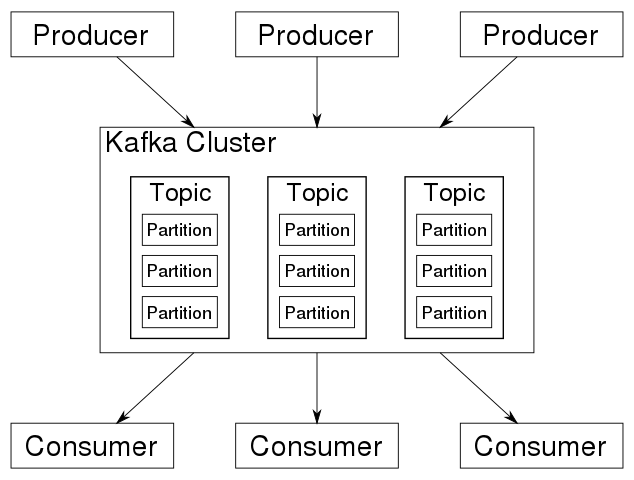
借助kafka的帮助,数据流可以被存储和处理。这使得kafka适用于大量数据和在大数据环境中的应用。
可以通过提供的接口从第三方系统加载数据流或将其导出到这些系统中。系统的核心组件是一个分布式提交或事务日志。
kafka:基本功能
kafka解决了直接连接数据源和数据接收器时出现的问题。
例如,当系统直接连接时,如果接收者不可用,则无法缓冲数据。此外,如果发送者发送的数据快于接收者接受和处理数据的速度,发送者可能会使接收者过载。
kafka充当了发送者和接收者之间的消息系统。由于其分布式事务日志,系统可以存储数据并以高可用性提供数据。数据一旦到达,可以以高速进行处理。数据可以实时聚合。
kafka架构
kafka的架构由一个集群计算机网络组成。在这个计算机网络中,所谓的代理存储带有时间戳的消息。这些信息被称为主题。存储的信息在集群中进行复制和分发。
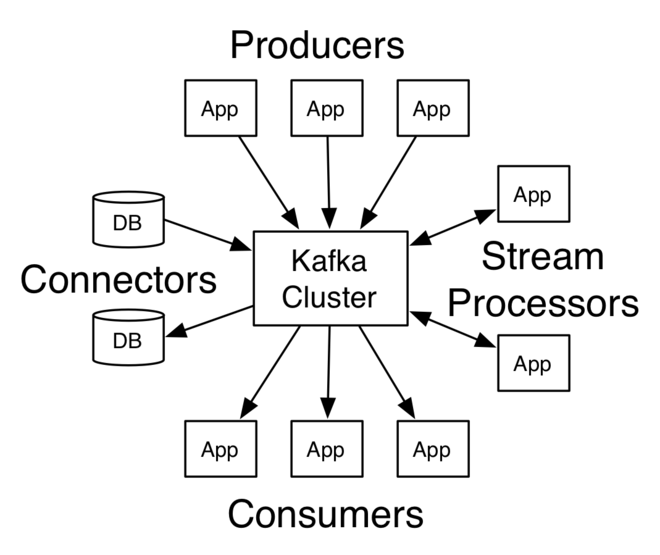
生产者是将消息或数据写入kafka集群的应用程序。消费者是从kafka集群中读取数据的应用程序。
此外,还有一个名为kafka streams的java库,它从集群中读取数据、处理数据,并将结果写回集群。
kafka区分“普通主题”和“压缩主题”。普通主题会存储一段时间,并且不能超过定义的存储大小。如果超过存储限制的时间,则kafka可能会删除旧的消息。压缩主题既没有时间限制,也没有存储空间限制。
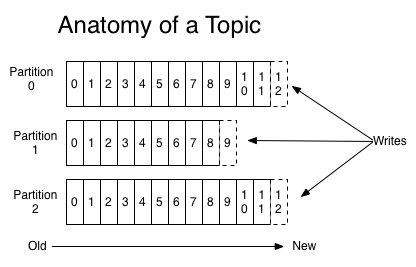
一个主题被分成多个分区。分区的数量在主题创建时设置,并确定主题的可扩展性。主题的消息被分发到分区中。偏移量是每个分区的属性。分区是扩展和复制工作的基本机制。
对主题的写入或读取总是涉及到某个分区。每个分区按其偏移量进行排序。如果你在一个主题上写入一条消息,可以选择指定一个键。
该键的哈希值确保具有相同键的所有消息最终进入同一个分区。在一个分区内保证按照消息的到达顺序进行处理。
kafka接口
总的来说,kafka提供了以下四个主要接口(api – 应用程序编程接口):
- 生产者api
- 消费者api
- 流api
- 连接api
生产者api允许应用程序将数据或消息写入kafka集群。可以通过消费者api读取kafka集群的数据。生产者和消费者api使用kafka消息协议。它是一种二进制协议。原则上,可以使用任何编程语言开发生产者和消费者客户端。
流api是一个java库。它可以以有状态和容错的方式处理数据流。可以通过提供的操作符进行数据的过滤、分组和分配。此外,还可以将自己的操作符集成到api中。
流api支持表、连接和时间窗口。在kafka主题中记录所有状态更改,以确保应用程序状态的可靠存储。如果发生故障,可以通过从主题中读取状态更改来恢复应用程序状态。
kafka connect api提供了从第三方系统加载和导出数据的接口。它基于生产者和消费者api。
特殊的连接器处理与第三方系统的通信。众多商业或免费连接器将不同厂商的第三方系统连接到kafka。
kafka的特点

kafka是一个对于希望建立实时数据系统的组织非常有价值的工具。它的一些主要特点包括:
高吞吐量
kafka是一个分布式系统,可以在多台机器上运行,并且设计用于处理高数据吞吐量,因此非常适合处理实时大量数据。
持久性和低延迟
kafka存储所有已发布的数据,这意味着即使消费者处于离线状态,一旦恢复在线状态,仍然可以消费数据。此外,kafka设计为具有低延迟,因此可以快速实时地处理数据。
高可扩展性
kafka可以在实时增加大量数据的情况下,性能几乎不会降低,非常适合用于大规模、高吞吐量的数据处理应用。
容错性
容错性也内置在kafka的设计中,它将数据复制到多个节点,因此如果一个节点失败,仍然可以在其他节点上使用。kafka确保数据始终可用,即使发生故障。
发布-订阅模型
在kafka中,生产者将数据写入主题,消费者从主题中读取数据。这允许数据生产者和消费者之间具有高度解耦,使其成为创建事件驱动架构的理想选择。
简单的api
kafka提供了一个简单易用的api,用于生成和消费数据,使其适用于广泛的开发人员。
压缩
kafka支持数据压缩,这可以帮助减少所需的存储空间并增加数据传输速度。
实时流处理
kafka可用于实时流处理,使组织能够在数据生成时实时处理数据。
kafka的应用场景
kafka提供了广泛的可能用途。典型的应用领域包括:
实时网站活动跟踪
kafka可以实时收集、处理和分析网站活动数据,使企业能够根据用户行为获得洞察并作出决策。
实时金融数据分析
kafka允许您实时处理和分析金融数据,以更快地识别趋势和潜在突破。
分布式应用程序的监控
kafka可以收集和处理分布式应用程序的日志数据,使组织能够监控其性能并快速识别和解决问题。
不同来源日志文件的聚合
kafka可以从不同来源聚合日志文件,并在集中位置提供分析和监控。
分布式系统中的数据同步
kafka允许您在多个系统之间同步数据,确保所有系统具有相同的信息并能够有效地协同工作。这就是为什么像沃尔玛这样的零售商使用它的原因。
kafka的另一个重要的应用领域是机器学习。kafka支持机器学习等功能:
实时模型训练
apache kafka可以实时流式处理数据,以训练机器学习模型,从而实现更准确、最新的预测。
实时分析模型的推导
kafka可以处理和分析数据以推导出分析模型,提供洞察和预测,可用于决策和采取行动。
机器学习应用的示例包括通过将实时支付信息与历史数据和模式进行关联来进行欺诈检测,基于当前、历史或基于位置的数据进行定制的客户专属优惠的交叉销售,或通过机器数据分析进行预测性维护。
kafka学习资源
既然我们已经谈到了kafka是什么以及它的用例,以下是一些学习和在实际环境中使用kafka的资源:
#1. apache kafka系列 – apache kafka初学者教程v3
apache kafka初学者教程是stephane maarek在udemy上提供的一门入门课程。该课程旨在为那些对这项技术还不熟悉但具有一定java和linux cli理解的个人提供全面的kafka介绍。
它涵盖了所有基本概念,并提供了实际示例和一个真实项目,帮助您更好地理解kafka的工作原理。

#2. apache kafka系列 – kafka streams
kafka streams数据处理是stephane maarek提供的另一门课程,旨在深入理解kafka streams。
课程涵盖了kafka streams架构、kafka streams api、kafka streams和ksql、一些真实用例以及如何使用kafka streams实现它们。该课程适用于有kafka先前经验的人。

#3. 绝对初学者的apache kafka
apache kafka绝对初学者是一门适合新手的课程,介绍了kafka的基础知识,包括其架构、核心概念和特性。它还涵盖了设置和配置kafka集群、生产和消费消息以及一个微型项目。

#4. 完整的apache kafka实践指南
kafka实践指南旨在提供与kafka一起工作的实践经验。它还涵盖了基本的kafka概念,以及有关创建集群、多个代理和编写自定义生产者和控制台的实用指南。该课程不需要任何先决条件。

#5. 使用apache kafka构建数据流应用程序
使用apache kafka构建数据流应用程序是为希望学习如何使用apache kafka构建数据流应用程序的开发人员和架构师提供的指南。
| 预览 | 产品 | 评分 | 价格 | |
|---|---|---|---|---|

|
使用apache kafka构建数据流应用程序:设计、开发和优化应用程序… | $44.99 | 在亚马逊上购买 |
本书介绍了kafka的关键概念和架构,并解释了如何使用kafka构建实时数据流水线和流应用程序。
内容涵盖了设置kafka集群、发送和接收消息以及将kafka与其他系统和工具集成的主题。此外,本书提供了最佳实践,帮助读者构建高性能和可扩展的数据流应用程序。
#6. apache kafka快速入门指南
kafka快速入门指南介绍了kafka的基础知识,包括其架构、关键概念和基本操作。它还提供了逐步说明,帮助您设置一个简单的kafka集群并使用它来发送和接收消息。
| 预览 | 产品 | 评分 | 价格 | |
|---|---|---|---|---|

|
apache kafka快速入门指南:通过apache kafka 2.0简化实时数据处理… | $30.99 | 在亚马逊上购买 |
此外,本指南还概述了更高级的功能,如复制、分区和容错性。本指南适用于对kafka新手的开发人员、架构师和数据工程师,并希望快速上手该平台。
结论
apache kafka 是一个分布式流处理平台,用于构建实时数据管道和流数据应用。kafka 在大数据系统中发挥着重要作用,通过提供快速、可靠和可扩展的方式,实时收集和处理大量数据。
它使得公司能够获得洞察力,做出数据驱动的决策,并提高他们的运营和整体性能。
您还可以使用 kafka 和 spark 进行 数据处理。






